标签:mob cpu 基础上 5* 其他 不同类 gpu 比赛结果 shu
Squeeze-and-Excitation Networks
SE-net 来自于Momenta
1 SE-net的灵感
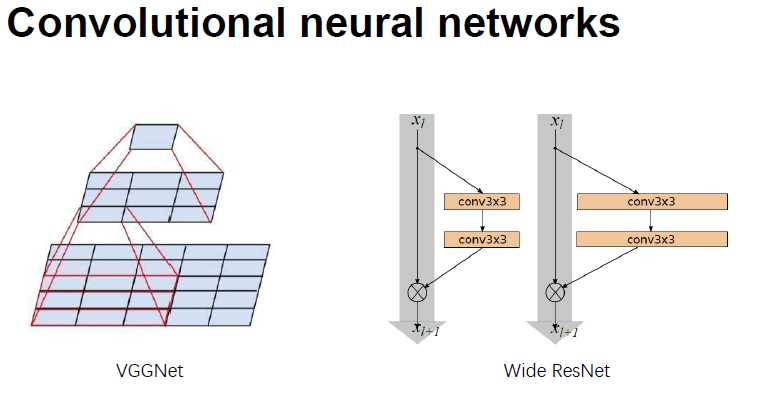
VGG 网络将 Alexnet 7*7 和 5*5 替换成了3*3 的卷积核
Wide Resnet如下右:
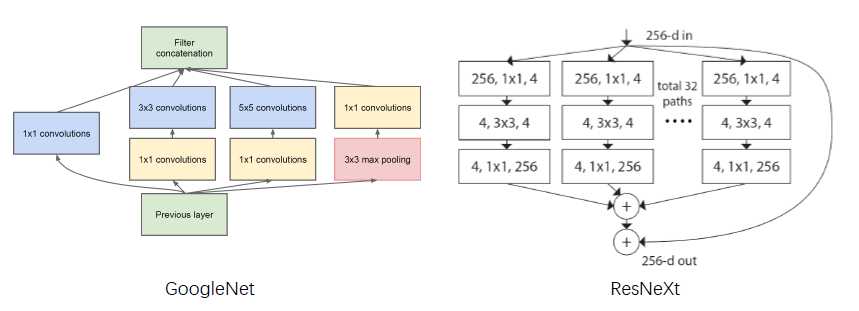
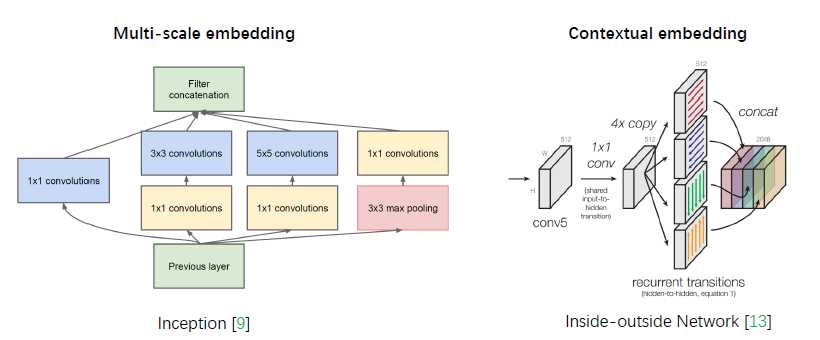
除此之外,GoogleNet 内部inxeption 实际使用的是一个多尺度 的结构。
googlenet 是将卷积在空间维度上进行组合
ResNeXt 是将左边的分支结构极端化,在不同的通道上进行group conversation,最后concat
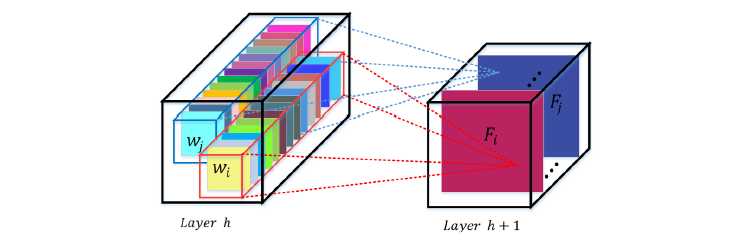
我们希望conv filter 可以在local receptive fields的基础上 融合 channel-wise 和 spatial 的信息作融合。
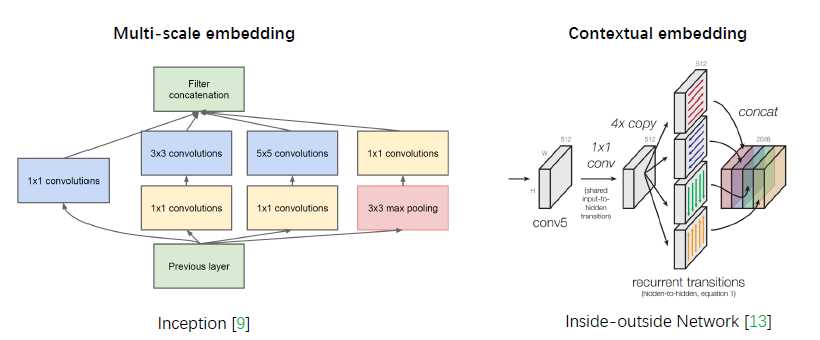
下图左边inception将卷积核在空间上进行了组合,右图inside-outsideNetwork 将不同方向的卷积在空间上组合到了一起
2 Squeeze-and-Excitation Networks
网络是否可以在通道关系方面做增强呢?
动机:
对于通道内部依赖做了显示的建模,选择强化有用的特征,抑制无用的特征

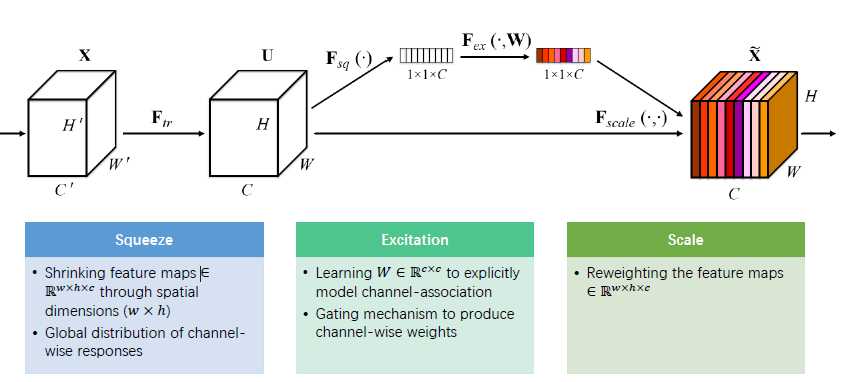
SE module 结构:
Ftr:X到U的卷积过程 ,但是通道之间的关系并没有发生变化:
Fsq:将每个通道做了一个squeeze操作,将每个通道表示成了一个标量,得到per channel的描述
Fex:将per channel标量进行“激活”,可以理解为算出了per channel的W
最后将per channel的W乘回到原来的feature map上得到加权后的channel,将channel 做了恰当的融合
SE-Module 可以用于网络的任意阶段
squeeze 操作保证了,在网络的早期感受野就可以大到全图的范围。
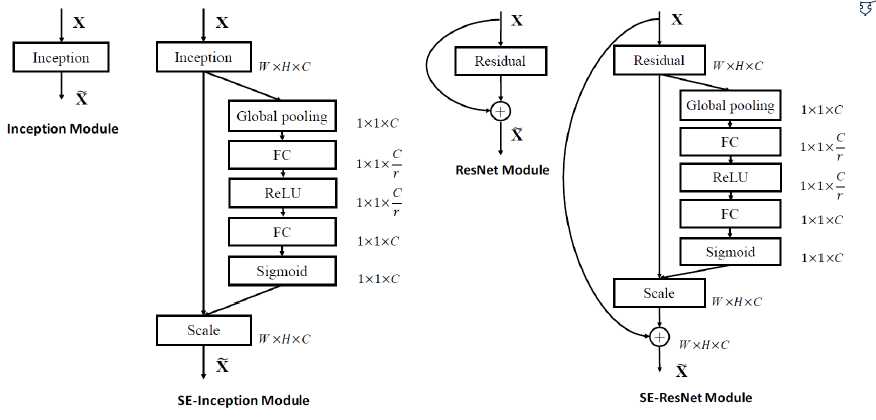
SE-inception Module and SE-ResNet Module:
下图左边将Inception Module 转化成SE 模块,在此操作中使用squeeze操作是Global polling 操作,也可以使用Global conv 操作,但是考虑到feature map 比较大的时候,G C 的W 也会比较大,所以选择用pooling,一种max 一种average plooing
最终选择的是average pooling,主要的考虑是,如果做检测任务,输入FM 大小是变化的,average 基本可以保持能量。如果用max FM 越大,能量不能保持,比如小的FM 求max 和 大的 FM 求 max 在测试时候并不等价。所以选择average pooling。得到1*1*c的向量。
后面可以接FC,但是为了减少参数,做了降维操作,增加了一个降维的系数r,输出 1*1*C/r
后接RELU,后面在做一个升维操作,得到1*1*C
最终使用S函数进行激活。
可以看到参数量主要取决与FC,在实验时r一般取16,经验值!
右图中,是resnet module,改造和inception分支很类似。
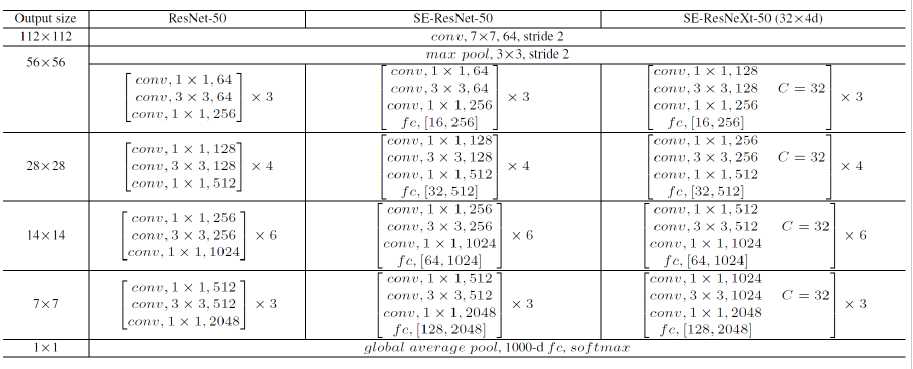
Architectures:
fc[16,256]表示,r 降维系数是16,会先降到16,然后升到256
在SE-ResNeXt-50中 (32*4d)中,将3*3卷积变成了group卷积,c取32
模型cost分析:
1 ,参数量
2 , 运算速度
参数量主要来自于在block内部增加的FC,会增加3%-10%的参数量 ,一般是10%,但是在某些情况下,网络在靠近输出的情况下
作者把7*7上的FC SE去掉了,得到总参数占3%,但是在TOP5的精度损失不到1%,非常的Cost-effective
其他的BN,RELU,POOLING 理论的计算量少。但是全连接对比卷积引起的计算量也很少

理论上计算量增加的计算量不到1%
实际inference GPU 时间增加了10%,分析原因可能是卷积核频繁操作, GPU运算不太友好,大size POOling的问题
CPU 测试和理论分析值接近。
训练的情况:
内部服务器:
Momenta ROCS
先对类别进行sample,再对类别内的图片进行sample,可以确保看到每个类别内图片概率的都是相同的

组员在之前场景分类用的小技巧,不是对图像随机采样,而是先对类别进行采样,再在每个特定类别中选去一张图像
可以保证数据见到的很平衡的,提高训练结果。
训练超参数:
任何网络保证每张卡可以处理32张图像,batchsize:1024 / 2048.当batch_size 是2048时候,LR可以调到1
实验部分:

可以看到添加SE以后计算量并没有增加很多。
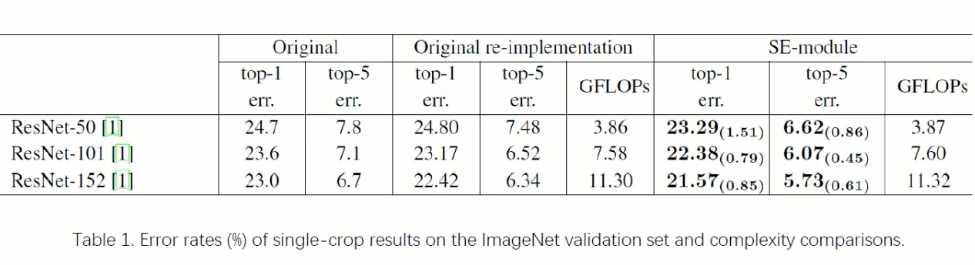
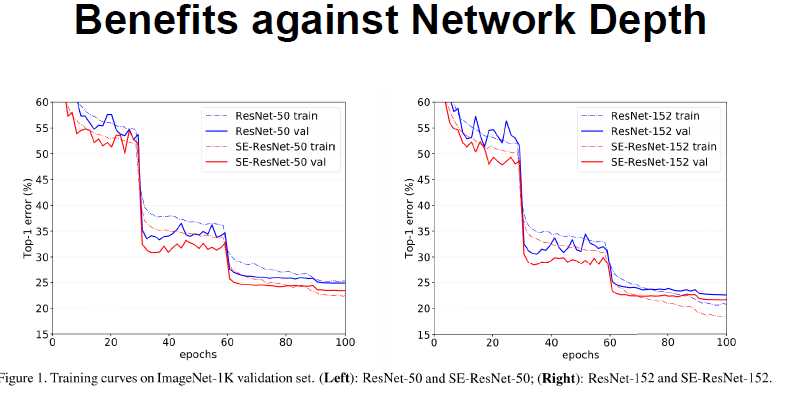
红色是SE
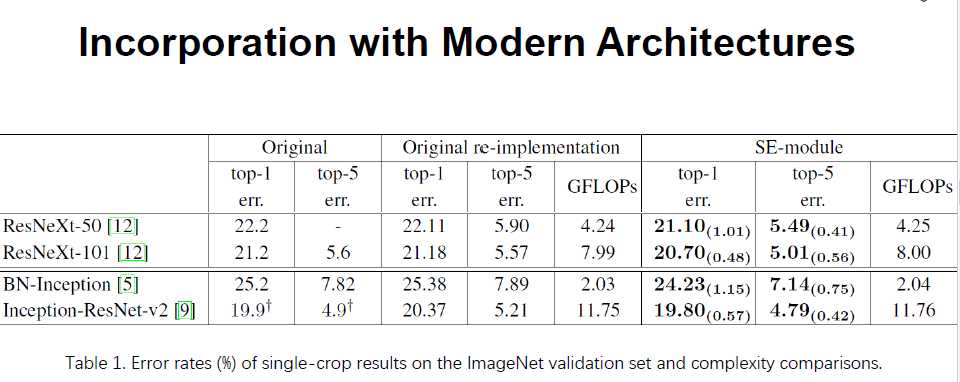
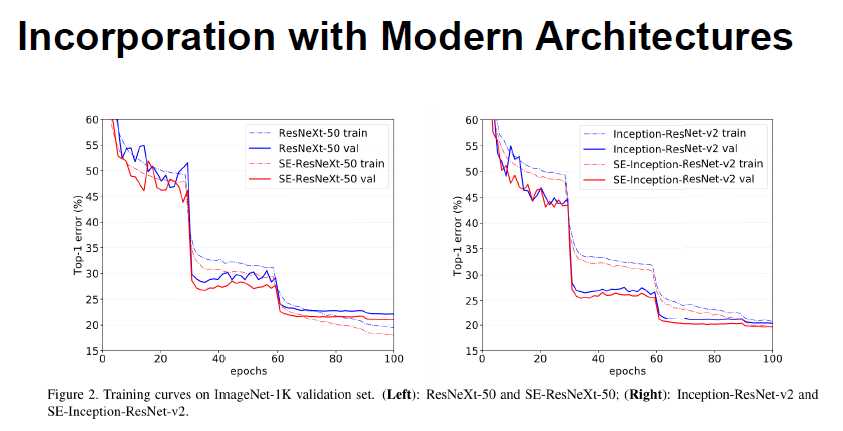
BN-inception 是一个直线型的网络,没有skip-connection:(想验证是否是只能用在skip-layer中)
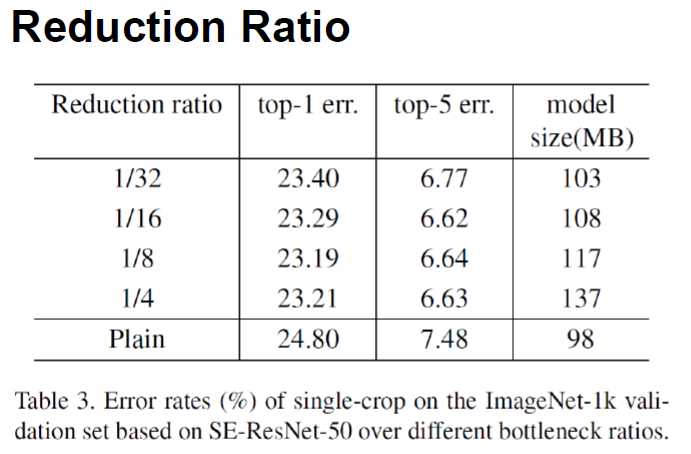
下图:两个小FC中的第一个,下采样的比例选取规则,50层的网路。在1/32的时候,性能还是有些差异,虽然size小了。
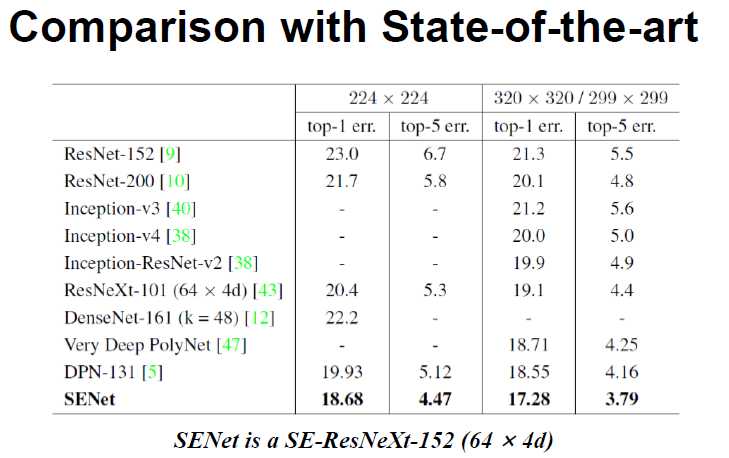
下图是实际在参加比赛时,imagenet的结果:
SE-ResNeXt-152 (64 * 4d)做的改进技巧:
1:把7*7 拆解成3个3*3连续卷积 (最早在inception中出现)
2:loss (label_smoothing)
3: 在训练的最后几个epoch,把BN fix住了,正常情况BN需要一起学习。5-10w次
因为,BN 只跟batch的数据相关,如果BN和其他W一直变的话很难学到一致的程度,fixBN,就可以保证 最后在训练和测试算出的的均值和方差都是一致的。
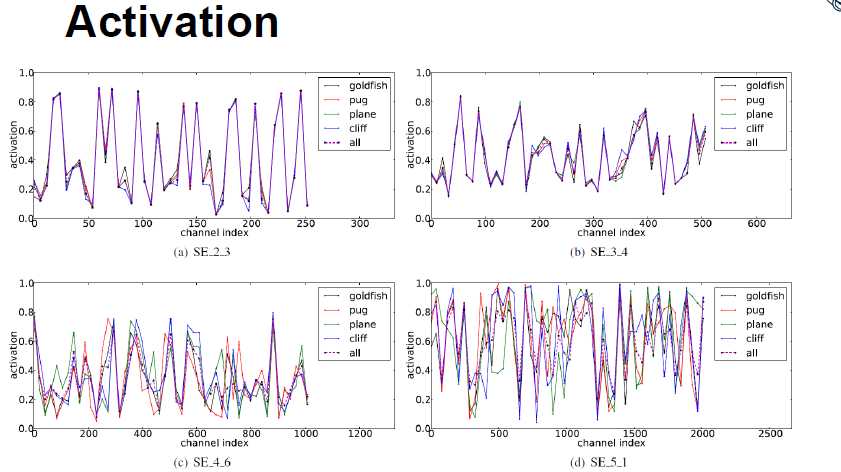
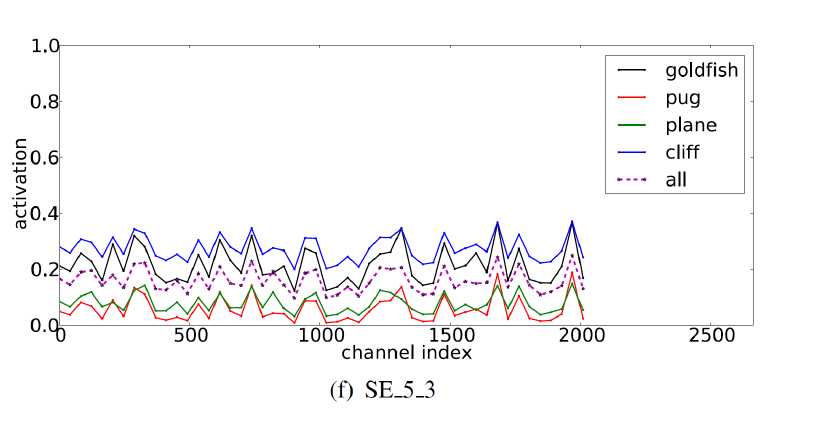
Excitation的分布结果:
取得基本都是每个stage最后的layer。在浅层网络学到的比较commen,share FM,在深层以后可以学到spacial
下图有意思的是:
基本大部分线都是1,都是重合的,激活是饱和状态,个别是0.如果激活所有的值是1的话,其实scale之后没有任何变化,可以认为就是原始的resnet moudle。 换句话说:这个SE模块没有起到任何作用,可以摘除掉
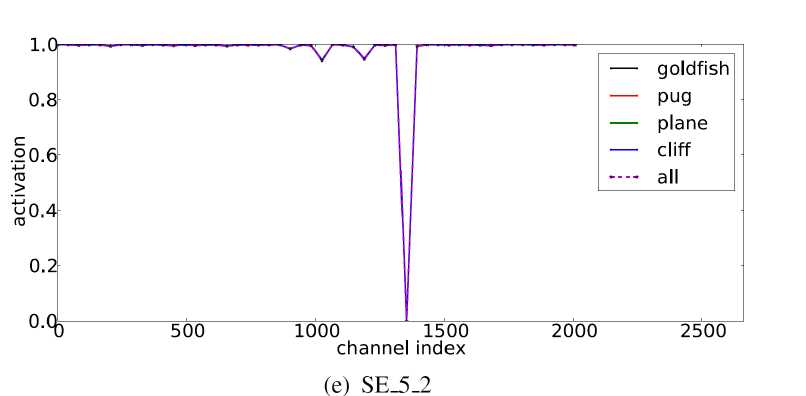
不同类别的激活基本都是相同的,只是浮值变化,这些浮值可以通过分类器的scale进行调节,上层+这层的SE起的作用不大,因为趋势相同,可能会退化成标准网络
结果把最后一个SE模块摘掉对整体影响不大。
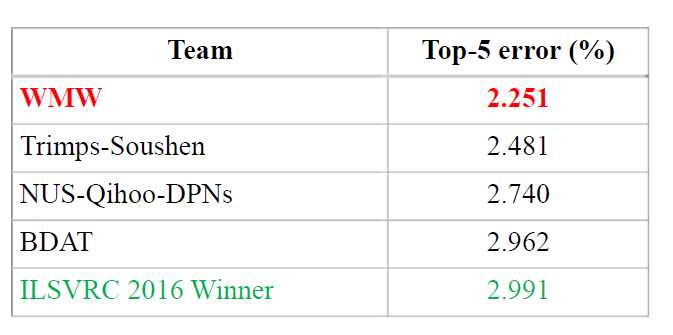
比赛结果:
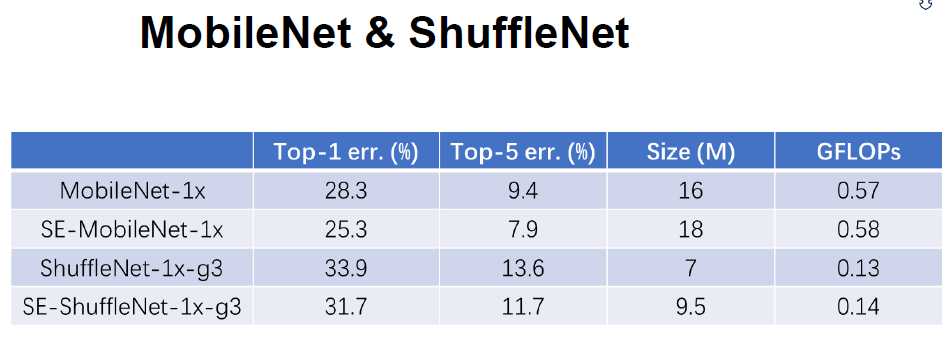
SE网络在Mob和Shufflenet中进行实验:在mobilenet上有3%的提升在shuffle上2%的提升,size 多一点点。
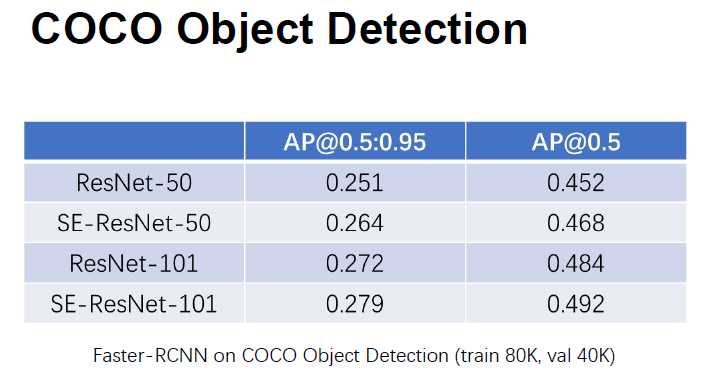
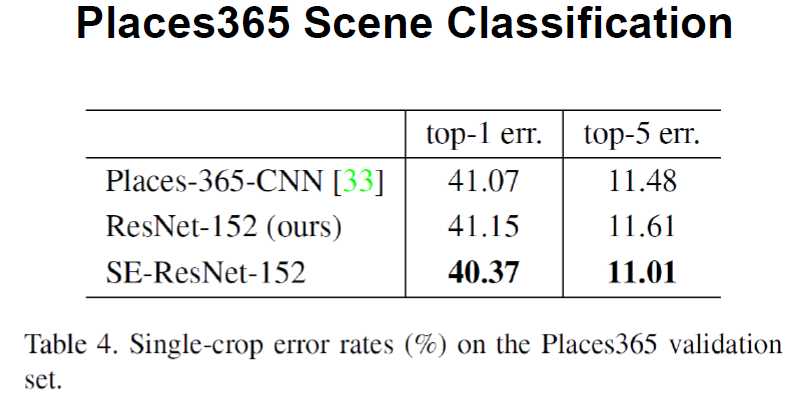
场景分类上的结果:
加了SE之后发现,显著超过之前的结果:

FAQ:
在不把SEfix的情况下有多大的收益?
只是竞赛的时候做了fix,追求极致的结果/
Squeeze Excitation Module 对网络的改进分析
标签:mob cpu 基础上 5* 其他 不同类 gpu 比赛结果 shu
原文地址:https://www.cnblogs.com/Libo-Master/p/9663508.html