标签:port 有序 出版社 height 字段 rom 格式 __str__ from
class Book(APIView): # parser_classes = [FormParser, ] def get(self, request): book_list = models.Book.objects.all() temp = [] for book in book_list: temp.append({"title": book.title, "publish_date": book.publishDate}) # 如果字段较多,不方便 return JsonResponse(temp, safe=False) def post(self, request): print("post") print(request.data) return HttpResponse("ok")
from django.core.serializers import serialize # django自带的序列化
class Book(APIView): # parser_classes = [FormParser, ] def get(self, request): book_list = models.Book.objects.all() data = serialize("json", book_list) # 格式 print(data) return HttpResponse(data) def post(self, request): print("post") print(request.data) return HttpResponse("ok")
get请求访问时,返回的数据:
[{"model": "app01.book", "pk": 1, "fields": {"title": "\u897f\u6e38\u8bb0", "price": "123.00", "publishDate": null, "publish": 1, "authors": [1, 2]}},
{"model": "app01.book", "pk": 2, "fields": {"title": "\u4e09\u56fd\u6f14\u4e49", "price": "456.00", "publishDate": null, "publish": 2, "authors": [3]}},
{"model": "app01.book", "pk": 3, "fields": {"title": "\u7ea2\u697c\u68a6", "price": "745.12", "publishDate": null, "publish": 3, "authors": [2]}},
{"model": "app01.book", "pk": 4, "fields": {"title": "\u6c34\u6d52\u4f20", "price": "456.23", "publishDate": null, "publish": 1, "authors": [3]}}]
默认的是这种格式,而且没有校验的功能;
from rest_framework.response import Response from rest_framework import serializers class BookSerializer(serializers.Serializer): # 在这个类中写什么字段,就序列化什么字段 title = serializers.CharField(max_length=32) price = serializers.DecimalField(max_digits=5, decimal_places=2) publishDate = serializers.DateField() class Book(APIView): # parser_classes = [FormParser, ] def get(self, request): book_list = models.Book.objects.all() bs = BookSerializer(book_list, many=True) # 实例化上面那个类,传入一个queryset,mang=True表示很多序列化一条以上的数据 print(bs.data) return Response(bs.data) def post(self, request): print("post") print(request.data) return HttpResponse("ok")
可以看到bs.data是一个列表中 放的一个个的有序字典:
[OrderedDict([(‘title‘, ‘西游记‘), (‘price‘, ‘123.00‘), (‘publishDate‘, None)]),
OrderedDict([(‘title‘, ‘三国演义‘), (‘price‘, ‘456.00‘), (‘publishDate‘, None)]),
OrderedDict([(‘title‘, ‘红楼梦‘), (‘price‘, ‘745.12‘), (‘publishDate‘, None)]),
OrderedDict([(‘title‘, ‘水浒传‘), (‘price‘, ‘456.23‘), (‘publishDate‘, None)])]
在前端响应中的数据是:
[ { "title": "西游记", "price": "123.00", "publishDate": null }, { "title": "三国演义", "price": "456.00", "publishDate": null }, { "title": "红楼梦", "price": "745.12", "publishDate": null }, { "title": "水浒传", "price": "456.23", "publishDate": null } ]
使用book表:
class Book(models.Model): title = models.CharField(max_length=32) price = models.DecimalField(max_digits=5, decimal_places=2) publishDate = models.DateField(default="2018-09-18") publish = models.ForeignKey(to="Publish", on_delete=models.CASCADE, default=1) authors = models.ManyToManyField(to="Author", default=2) def __str__(self): return self.title
先写那个序列化类:
对于普通字段:
class BookSerializer(serializers.Serializer): title = serializers.CharField(max_length=32) price = serializers.DecimalField(max_digits=5, decimal_places=2) publishDate = serializers.DateField()
在写我们的视图:
class Book(APIView): # parser_classes = [FormParser, ] def get(self, request): book_list = models.Book.objects.all() bs = BookSerializer(book_list, many=True) print(bs.data) return Response(bs.data) def post(self, request): print(request.data) bs = BookSerializer(data=request.data, many=False) # many默认就是False,可以不写 if bs.is_valid(): # 校验 # 添加到数据库, 需要手动创建 models.Book.objects.create(**request.data) return Response(bs.data) # 创建成功,返回创建的数据 else: return Response(bs.errors) # 失败,返回错误信息
序列化的过程:
我们写了 bs = BookSerializer(data=request.data, many=False) 这句话的时候,
对于bs.data数据:
restframework序列化组件是这样做的:
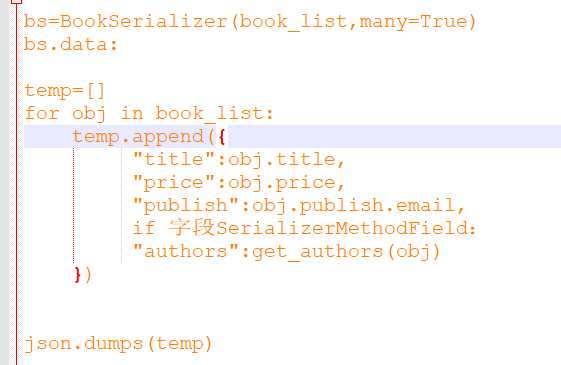
temp = [ ]
for obj in book_list:
temp.append({
"title": obj.title, # 这里面的键就是我们写的字段
"price": obj.price,
"publishDate": obj.publishDate
})
json.dumps(temp),
那么,如果我们写了一对多,或者多对多字段,如:
class BookSerializer(serializers.Serializer): title = serializers.CharField(max_length=32) price = serializers.DecimalField(max_digits=5, decimal_places=2) publishDate = serializers.DateField() publish = serializers.CharField(max_length=32) # 一对多关系 authors = serializers.CharField(max_length=32) # 多对多关系
在序列化过程中,就会出现obj.publish, 结果是publish的对象; obj.authors, 结果是管理对象,即 app01.Author.None;
结果如下:
# get请求的结果
[ { "title": "西游记", "price": "123.00", "publishDate": null, "publish": "沙河出版社", # 显示的str方法的结果 "authors": "app01.Author.None" }, { "title": "三国演义", "price": "456.00", "publishDate": null, "publish": "西二旗出版社", "authors": "app01.Author.None" }, { "title": "红楼梦", "price": "745.12", "publishDate": null, "publish": "望京西出版社", "authors": "app01.Author.None" }, { "title": "水浒传", "price": "456.23", "publishDate": null, "publish": "沙河出版社", "authors": "app01.Author.None" }]
所以,对于一对多的字段:
class BookSerializer(serializers.Serializer): title = serializers.CharField(max_length=32) price = serializers.DecimalField(max_digits=5, decimal_places=2) publishDate = serializers.DateField() publish_email = serializers.CharField(max_length=32, source="publish.email") publish_name = serializers.CharField(max_length=32, source="publish.name") authors = serializers.CharField(max_length=32)
写上source之后,那里循环的时候就是采用的obj.source的内容了,所以前面的字段名称也就不一定要和表对齐了。
# get请求的结果
[ { "title": "西游记", "price": "123.00", "publishDate": null, "publish_email": "132", "publish_name": "沙河出版社", "authors": "app01.Author.None" }, { "title": "三国演义", "price": "456.00", "publishDate": null, "publish_email": "456", "publish_name": "西二旗出版社", "authors": "app01.Author.None" }]
对于多对多字段,我们当然也可以写source了,比如:
class BookSerializer(serializers.Serializer): title = serializers.CharField(max_length=32) price = serializers.DecimalField(max_digits=5, decimal_places=2) publishDate = serializers.DateField() publish_email = serializers.CharField(max_length=32, source="publish.email") publish_name = serializers.CharField(max_length=32, source="publish.name") authors = serializers.CharField(max_length=32, source="authors.all")
但是这样的话前端拿到的就是:
[ { "title": "西游记", "price": "123.00", "publishDate": null, "publish_email": "132", "publish_name": "沙河出版社", "authors": "<QuerySet [<Author: 觉先生>, <Author: 胡大炮>]>" # 前端根本不能处理queryset类型,所以也就没有意义了 }]
所以,多对多字段我们这么写:
class BookSerializer(serializers.Serializer): title = serializers.CharField(max_length=32) price = serializers.DecimalField(max_digits=5, decimal_places=2) publishDate = serializers.DateField() publish_email = serializers.CharField(max_length=32, source="publish.email") publish_name = serializers.CharField(max_length=32, source="publish.name") # authors = serializers.CharField(max_length=32) authors = serializers.SerializerMethodField() # 多对多字段 def get_authors(self, obj): # 这里的obj是循环中的书籍对象, 函数名称必须是 get_多对多字段名 ret = [] for author in obj.authors.all(): ret.append( {"name": author.name, "age": author.age} ) return ret
前端拿到的数据:
[ { "title": "西游记", "price": "123.00", "publishDate": null, "publish_email": "132", "publish_name": "沙河出版社", "authors": [ # 这样前端就可以处理了 { "name": "觉先生", "age": 18 }, { "name": "胡大炮", "age": 28 } ] } ]
多对多字段的序列话的时候:
循环时,如果时多对多字段,那么
temp.append({
"字段名(authors)": get_authors()函数的返回值
});
from app01 import models from rest_framework.views import APIView from rest_framework.response import Response from rest_framework import serializers class BookSerializer(serializers.ModelSerializer): class Meta: model = models.Book # fields = ["title", "price", "publishDate"] # 可以指定字段 fields = "__all__" # 所有字段 class Book(APIView): # parser_classes = [FormParser, ] def get(self, request): book_list = models.Book.objects.all() bs = BookSerializer(book_list, many=True) print(bs.data) return Response(bs.data) def post(self, request): print(request.data) bs = BookSerializer(data=request.data, many=False) # many默认就是False,可以不写 if bs.is_valid(): # 校验 bs.save() # 直接save() return Response(bs.data) # 创建成功,返回创建的数据 else: return Response(bs.errors) # 失败,返回错误信息
get请求数据,结果为:
[ { "id": 1, "title": "西游记", "price": "123.00", "publishDate": null, "publish": 1, # 默认取得都是主键 "authors": [ 1, 2 ] }, { "id": 2, "title": "三国演义", "price": "456.00", "publishDate": null, "publish": 2, "authors": [ 3 ] }, { "id": 3, "title": "红楼梦", "price": "745.12", "publishDate": null, "publish": 3, "authors": [ 2 ] } ]
我们也可以自己配置, 方法和上面直接使用Serializer一致:
class BookSerializer(serializers.ModelSerializer): class Meta: model = models.Book # fields = ["title", "price", "publishDate"] # 可以指定字段 fields = "__all__" # 所有字段 publish_email = serializers.CharField(max_length=32, source="publish.email") publish_name = serializers.CharField(max_length=32, source="publish.name") authors = serializers.SerializerMethodField() # 多对多字段 def get_authors(self, obj): # 这里的obj是循环中的书籍对象 ret = [] for author in obj.authors.all(): ret.append( {"name": author.name, "age": author.age} ) return ret
get请求数据结果:
[ { "id": 1, "publish_email": "132", "publish_name": "沙河出版社", "authors": [ { "name": "觉先生", "age": 18 }, { "name": "胡大炮", "age": 28 } ], "title": "西游记", "price": "123.00", "publishDate": null, "publish": 1 } ]
post提交数据时,数据库中没有的字段,就算是提交了,也不会报错,但是要是我们配置了某些字段,那么在提交时,这些字段也必须有,不然会校验失败;
如: 我们配置了 publish_email字段,所以提交数据,要求必须有这个字段,就算提交了这个字段,数据库也不会保存,但是不提交会校验失败。
标签:port 有序 出版社 height 字段 rom 格式 __str__ from
原文地址:https://www.cnblogs.com/glh-ty/p/9671397.html