标签:概率 最优二叉树 图片 9.png buffered pack setw 路径 编程
建树,造树,编码,解码
0.1,0.1,0.1,0.1,0.1,0.1,0.2,0.2i like you //文档| 字符 | 频率 |
|---|---|
| i | 0.2 |
| l | 0.1 |
| k | 0.1 |
| e | 0.1 |
| y | 0.1 |
| o | 0.1 |
| u | 0.1 |
| 空格 | 0.2 |
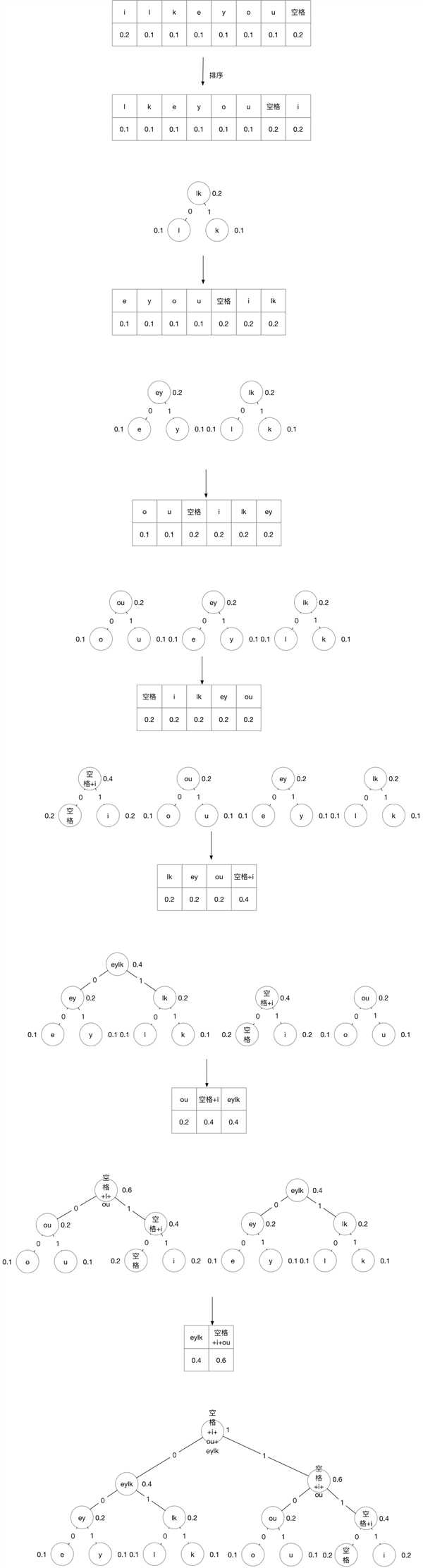
从根向下一次读取0或者1,进行编码,编码结果如下表
| 字符 | 编码 |
|---|---|
| i | 111 |
| l | 010 |
| k | 011 |
| e | 000 |
| y | 001 |
| o | 100 |
| u | 101 |
| 空格 | 110 |
for many young people they dont have the habit to save money because they think they are young and should enjoy the life quickly so there is no need to save money but saving part of the income can better help us to deal with emergent situations though it is hard to store income index zero we still can figure out some ways //读取文档中的英文文档
String[] a = new String[800];
try (FileReader reader = new FileReader("英文文档");
BufferedReader br = new BufferedReader(reader)
) {
int b =0;
for (int i =0;i<800;i++){
a[b]=br.readLine();
b++;
}
} catch (IOException e) {
e.printStackTrace();
}
String[] b = a[0].split("");
// System.out.println(Arrays.toString(b));
//开始构造哈夫曼树
Objects Za= new Objects("a",an);
Objects Zb = new Objects("b",bn);
Objects Zc = new Objects("c",cn);
Objects Zd = new Objects("d",dn);
Objects Ze = new Objects("e",en);
Objects Zf = new Objects("f",fn);
Objects Zg = new Objects("g",gn);
Objects Zh = new Objects("h",hn);
Objects Zi = new Objects("i",in);
Objects Zj = new Objects("j",jn);
Objects Zk = new Objects("k",kn);
Objects Zl = new Objects("l",ln);
Objects Zm = new Objects("m",mn);
Objects Zn = new Objects("n",nn);
Objects Zo = new Objects("o",on);
Objects Zp = new Objects("p",pn);
Objects Zq = new Objects("q",qn);
Objects Zr = new Objects("r",rn);
Objects Zs = new Objects("s",sn);
Objects Zt = new Objects("t",tn);
Objects Zu = new Objects("u",un);
Objects Zv = new Objects("v",vn);
Objects Zw = new Objects("w",wn);
Objects Zx = new Objects("x",xn);
Objects Zy = new Objects("y",yn);
Objects Zz = new Objects("z",zn);
Objects Zkongge = new Objects(" ",zkongge);
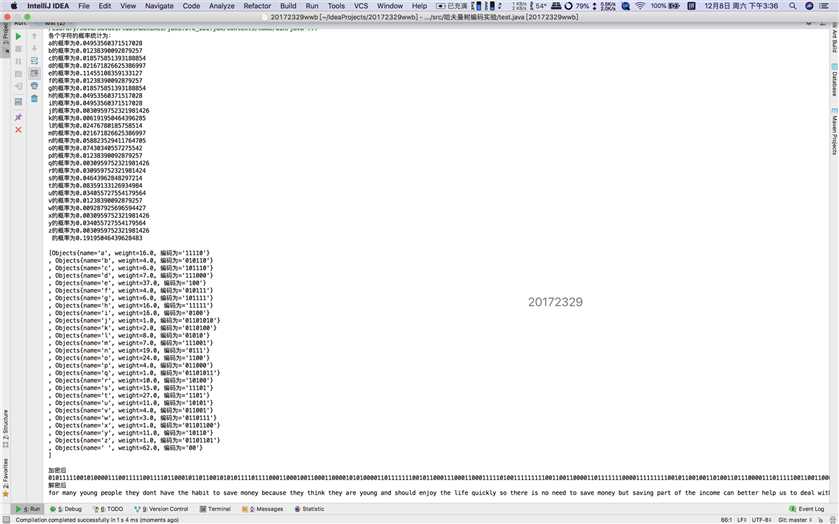
System.out.println("各个字符的概率统计为:");
Objects[] temp = new Objects[]{Za,Zb,Zc,Zd,Ze,Zf,Zg,Zh,Zi,Zj,Zk,Zl,Zm,Zn,Zo,Zp,Zq,Zr,Zs,Zt,Zu,Zv,Zw,Zx,Zy,Zz,Zkongge};
for (int i =0;i<temp.length;i++){
System.out.println(temp[i].getName()+"的概率为"+temp[i].getWeight()/323);
}
名字,权重,编码,还有他的左孩子,右孩子。package 哈夫曼树编码实验;
public class Objects implements Comparable<Objects> {
private String name;
private double weight;
private String date;
private Objects left;
private Objects right;
public Objects(String Name , double Weight){
name=Name;
weight=Weight;
date="";
}
public String getName() {
return name;
}
public double getWeight() {
return weight;
}
public Objects getLeft() {
return left;
}
public Objects getRight() {
return right;
}
public void setLeft(Objects left) {
this.left = left;
}
public void setRight(Objects right) {
this.right = right;
}
public void setName(String name) {
this.name = name;
}
public void setWeight(double weight) {
this.weight = weight;
}
@Override
public String toString() {
return "Objects{" + "name='" + name + '\'' + ", weight=" + weight + ", 编码为='" + date + '\'' + '}'+"\n";
}
@Override
public int compareTo(Objects o) {
if (weight>=o.weight){
return 1;
}
else {
return -1; //规定发现权重相等向后放;
}
}
public void setDate(String date) {
this.date = date;
}
public String getDate() {
return date;
}
}
List tempp = new ArrayList();
for (int i =0;i<temp.length;i++){
tempp.add(temp[i]);
}
Collections.sort(tempp); //将我们的Objects类中的每一个字符放进链表进行排序
while (tempp.size() > 1) { //直到我们链表只剩下一个元素,也就是我们的根结点的时候跳出循环
Collections.sort(tempp); //排序
Objects left = (Objects) tempp.get(0); //得到第一个元素,作为左孩子
left.setDate( "0"); //初始化左孩子的编码为0
Objects right = (Objects) tempp.get(1); //得到第二个元素,作为右孩子
right.setDate( "1"); //初始化有孩子的编码为1
Objects parent = new Objects(left.getName()+right.getName(), left.getWeight() + right.getWeight()); //构造父结点
parent.setLeft(left); //设置左结点
parent.setRight(right); //设置右结点
tempp.remove(left); //删除左结点
tempp.remove(right); //删除右结点
tempp.add(parent); //将父结点添加进入链表
}
//开始进行哈夫曼编码
Objects root = (Objects) tempp.get(0); //我们通过一个root保存为根结点
System.out.println( ); //我们利用先序遍历,遍历到每一个结点,因为这样可以保证都从根结点开始遍历
List list = new ArrayList();
Queue queue = new ArrayDeque();
queue.offer(root);
while (!queue.isEmpty()){
list.add(queue.peek());
Objects temp1 = (Objects) queue.poll();
if(temp1.getLeft() != null)
{
queue.offer(temp1.getLeft());
temp1.getLeft().setDate(temp1.getDate()+"0"); //判断假如为左结点,就基于结点本身的编码加上0
}
if(temp1.getLeft() != null)
{
queue.offer(temp1.getRight());
temp1.getRight().setDate(temp1.getDate()+"1"); //判断假如为右结点,就基于结点本身的编码加上1
}
} //进行加密
String result = ""; //定义了一个字符串,用来保存加密后的文档
for (int i =0 ;i<b.length;i++){
for (int j=0;j<temp.length;j++){
if (b[i].equals(temp[j].getName())){
result+=temp[j].getDate(); //因为现在我们之前保存Objects的数组中的每一个字符已经有各自的编码,所以我们用我们之前保存文档的数组b进行对于,假如找到相对应的,就将编码赋给result,进行累加,重复过程
break;
}
}
}
System.out.println("加密后");
System.out.println(result);
File file = new File("加密后文档");
FileWriter fileWritter = null;
try {
fileWritter = new FileWriter(file.getName(),true);
} catch (IOException e) {
e.printStackTrace();
}
try {
fileWritter.write(result);
} catch (IOException e) {
e.printStackTrace();
}
try {
fileWritter.close();
} catch (IOException e) {
e.printStackTrace();
} //解密,读取需要解密的文档
try (FileReader reader = new FileReader("加密后文档");
BufferedReader br = new BufferedReader(reader)
) {
int e =0;
for (int i =0;i<800;i++){
a[e]=br.readLine();
e++;
}
} catch (IOException e) {
e.printStackTrace();
}
String duqu=a[0];
String jiemi=""; //保存解密后的文档
String temp2=""; // 作为一个临时的字符串,一个一个进行获取密文,当进行匹配成功了以后,变为空,如下
for (int i =0;i<duqu.length();i++){
temp2+=duqu.charAt(i);
for (int j = 0;j<temp.length;j++){ //这里解密的思路就是我们从加密的文档中一个一个字符进行获取,然后与我们的之前建好的Objects数组中的元素的编码
if (temp2.equals(temp[j].getDate())){ //进行获取,然后获取成功以后将其赋给jiemi,然后清空temp2;
jiemi+=temp[j].getName();
temp2="";
}
}
}
System.out.println("解密后");
System.out.println(jiemi);
//将解密后的文本写入文件
File file1 = new File("解密后文档");
FileWriter fileWritter1 = null;
try {
fileWritter1 = new FileWriter(file1.getName(),true);
} catch (IOException e) {
e.printStackTrace();
}
try {
fileWritter1.write(jiemi);
} catch (IOException e) {
e.printStackTrace();
}
try {
fileWritter1.close();
} catch (IOException e) {
e.printStackTrace();
}
标签:概率 最优二叉树 图片 9.png buffered pack setw 路径 编程
原文地址:https://www.cnblogs.com/qh45wangwenbin/p/10089416.html
{kind=link}