标签:数据集 预测 preview 成功 mat 因此 状态 nbsp 扩展
机器学习算法用于训练模型的迭代试错过程(迭代方法):
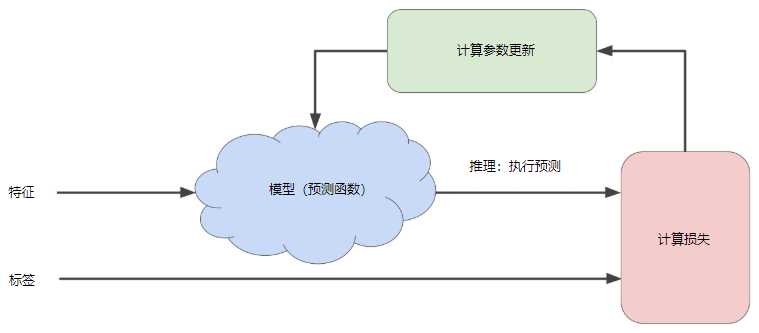
迭代策略在机器学习中的应用非常普遍,这主要是因为它们可以很好地扩展到大型数据集。
“模型”部分将一个或多个特征作为输入,然后返回一个预测作为输出。
“计算损失”部分是模型将要使用的损失函数,机器学习系统在“计算参数更新”部分检查损失函数的值。
现在,假设这个神秘的绿色框会产生新值,然后机器学习系统将根据所有标签重新评估所有特征,为损失函数生成一个新值,而该值又产生新的参数值。
这种学习过程会持续迭代,直到该算法发现损失可能最低的模型参数。
通常可以不断迭代,直到总体损失不再变化或至少变化极其缓慢为止。这时候,可以说该模型已收敛。
在训练机器学习模型时,首先对权重和偏差进行初始猜测,然后反复调整这些猜测,直到获得损失可能最低的权重和偏差为止。
回归问题所产生的损失与权重值的图形始终是凸形。换言之,图形始终是碗状图。
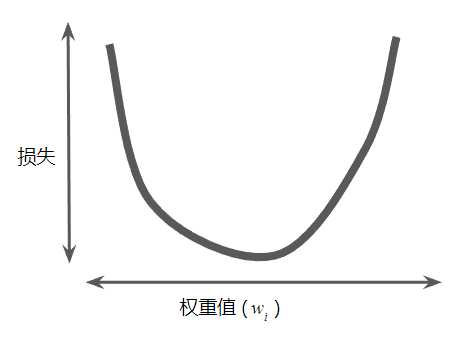
凸形问题只有一个最低点;即只存在一个斜率正好为 0 的位置。这个最小值就是损失函数收敛之处。
通过计算整个数据集中每个权重值的损失函数来找到收敛点这种方法效率太低,通过梯度下降法可以高效地找到收敛点。
梯度下降法的第一个阶段是为权重值选择一个起始值(起点)。
起点并不重要;因此很多算法就直接将权重值设为 0 或随机选择一个值。
下图显示选择了一个稍大于 0 的起点:
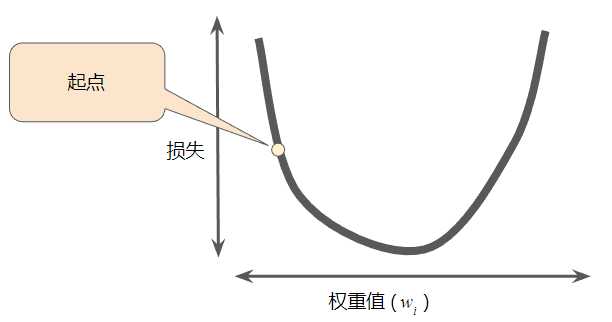
然后,梯度下降法算法会计算损失曲线在起点处的梯度。简而言之,梯度是偏导数的矢量;它可以让您了解哪个方向距离目标“更近”或“更远”。
请注意,梯度是一个矢量,因此具有以下两个特征:方向和大小。
梯度始终指向损失函数中增长最为迅猛的方向。梯度下降法算法会沿着负梯度的方向走一步,以便尽快降低损失。
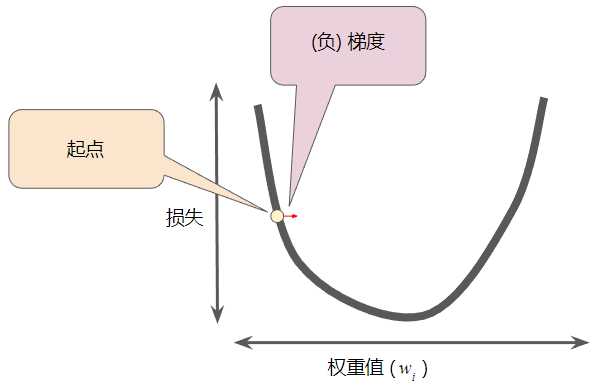
为了确定损失函数曲线上的下一个点,梯度下降法算法会将梯度大小的一部分与起点相加( 一个梯度步长将我们移动到损失曲线上的下一个点):
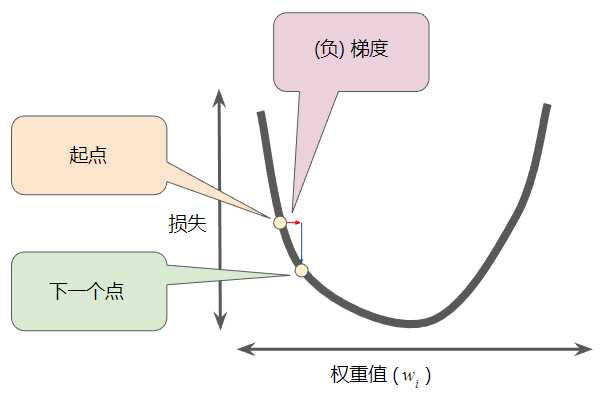
然后,梯度下降法会重复此过程,逐渐接近最低点。
梯度下降法算法用梯度乘以一个称为学习速率(有时也称为步长)的标量,以确定下一个点的位置。
例如,如果梯度大小为 2.5,学习速率为 0.01,则梯度下降法算法会选择距离前一个点 0.025 的位置作为下一个点。
超参数是编程人员在机器学习算法中用于调整的旋钮。
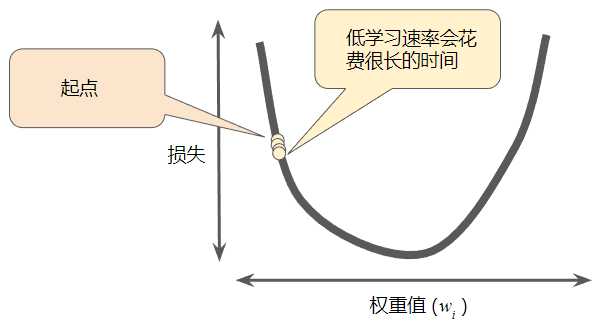
大多数机器学习编程人员会花费相当多的时间来调整学习速率。如果选择的学习速率过小,就会花费太长的学习时间:
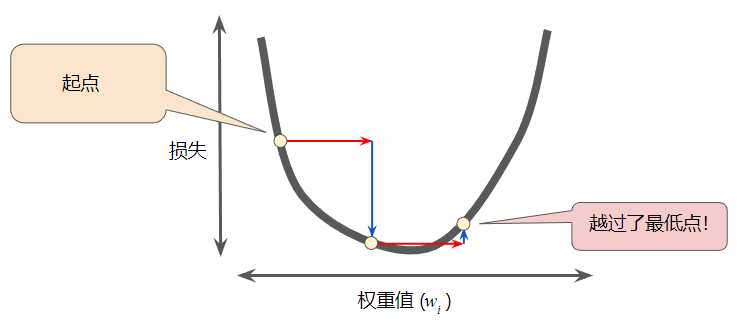
相反,如果指定的学习速率过大,下一个点将永远在 U 形曲线的底部随意弹跳:
每个回归问题都存在一个“恰好合适”学习速率,这个值与损失函数的平坦程度相关。
如果知道损失函数的梯度较小,则可以放心地试着采用更大的学习速率,以补偿较小的梯度并获得更大的步长。
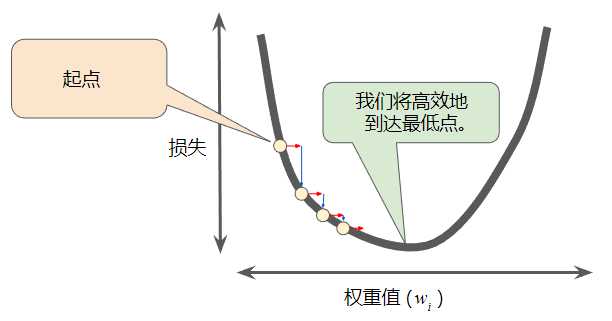
在实践中,成功的模型训练并不意味着要找到“完美”(或接近完美)的学习速率。
目标是找到一个足够高的学习速率,该速率要能够使梯度下降过程高效收敛,但又不会高到使该过程永远无法收敛。
在梯度下降法中,批量指的是用于在单次迭代中计算梯度的样本总数。如果是超大批量,则单次迭代就可能要花费很长时间进行计算。
包含随机抽样样本的大型数据集可能包含冗余数据。实际上,批量大小越大,出现冗余的可能性就越高。一些冗余可能有助于消除杂乱的梯度,但超大批量所具备的预测价值往往并不比大型批量高。
通过从数据集中随机选择样本,可以通过小得多的数据集估算(尽管过程非常杂乱)出较大的平均值。
随机梯度下降法 (SGD) 每次迭代只使用一个样本(批量大小为 1)。
如果进行足够的迭代,SGD 也可以发挥作用,但过程会非常杂乱。“随机”这一术语表示构成各个批量的一个样本都是随机选择的。
小批量随机梯度下降法(小批量 SGD)是介于全批量迭代与 SGD 之间的折衷方案。
小批量通常包含 10-1000 个随机选择的样本。小批量 SGD 可以减少 SGD 中的杂乱样本数量,但仍然比全批量更高效。
梯度下降法也适用于包含多个特征的特征集。
收敛 (convergence)
通俗来说,收敛通常是指在训练期间达到的一种状态,即经过一定次数的迭代之后,训练损失和验证损失在每次迭代中的变化都非常小或根本没有变化。
也就是说,如果采用当前数据进行额外的训练将无法改进模型,模型即达到收敛状态。
在深度学习中,损失值有时会在最终下降之前的多次迭代中保持不变或几乎保持不变,暂时形成收敛的假象。
损失 (Loss)
一种衡量指标,用于衡量模型的预测偏离其标签的程度。
或者更悲观地说是衡量模型有多差。要确定此值,模型必须定义损失函数。
例如,线性回归模型通常将均方误差用作损失函数,而逻辑回归模型则使用对数损失函数。
训练 (training)
确定构成模型的理想参数的过程。
梯度下降法 (gradient descent)
一种通过计算并且减小梯度将损失降至最低的技术,它以训练数据为条件,来计算损失相对于模型参数的梯度。
通俗来说,梯度下降法以迭代方式调整参数,逐渐找到权重和偏差的最佳组合,从而将损失降至最低。
步 (step)
对一个批次的向前和向后评估。
超参数 (hyperparameter)
在模型训练的连续过程中,您调节的“旋钮”。
例如,学习速率就是一种超参数。
与参数相对。
学习速率 (learning rate)
在训练模型时用于梯度下降的一个标量。
在每次迭代期间,梯度下降法都会将学习速率与梯度相乘。得出的乘积称为梯度步长。
学习速率是一个重要的超参数。
步长 (step size)
与学习速率的含义相同。
批次 (batch) ,批量
模型训练的一次迭代(即一次梯度更新)中使用的样本集。
另请参阅批次大小。
批次大小 (batch size),批量大小
一个批次中的样本数。
例如,SGD 的批次大小为 1,而小批次的大小通常介于 10 到 1000 之间。
批次大小在训练和推断期间通常是固定的;不过,TensorFlow 允许使用动态批次大小。
小批次 (mini-batch),小批量
从整批样本内随机选择并在训练或推断过程的一次迭代中一起运行的一小部分样本。
小批次的批次大小通常介于 10 到 1000 之间。
与基于完整的训练数据计算损失相比,基于小批次数据计算损失要高效得多。
随机梯度下降法 (SGD, stochastic gradient descent)
批次大小为 1 的一种梯度下降法。
换句话说,SGD 依赖于从数据集中随机均匀选择的单个样本来计算每步的梯度估算值。
基于大型数据集执行梯度下降法时,以下哪个批量大小可能比较高效?
标签:数据集 预测 preview 成功 mat 因此 状态 nbsp 扩展
原文地址:https://www.cnblogs.com/anliven/p/10258292.html