标签:ase com 最大值 img 绝对值 tar ring reg 手机
一、背景
本实例是本人参加某公司的面试的题目,根据文件描述选择模型,对用户是否是潜在的bad用户做出预测,总共五个文件
1)Question
risk_train和risk_test的每一行为一个用户的贷款申请数据,Feature Description提供了字段说明,y_bad字段为需要预测的标签。applist为risk_train和risk_test当中各用户的app安装数据
请根据risk_train中的特征和y_bad标签,与applist当中挖掘出的app特征,并根据你的想法生成衍生特征,训练模型来准确预测y_bad,用选择出的模型对risk_test中每一个loanID预测y_bad的概率
最后整理出模型PPT报告,risk_test的预测结果(保存为test_score.csv文件,仅保留loanID和score两列)
2)Feature Description
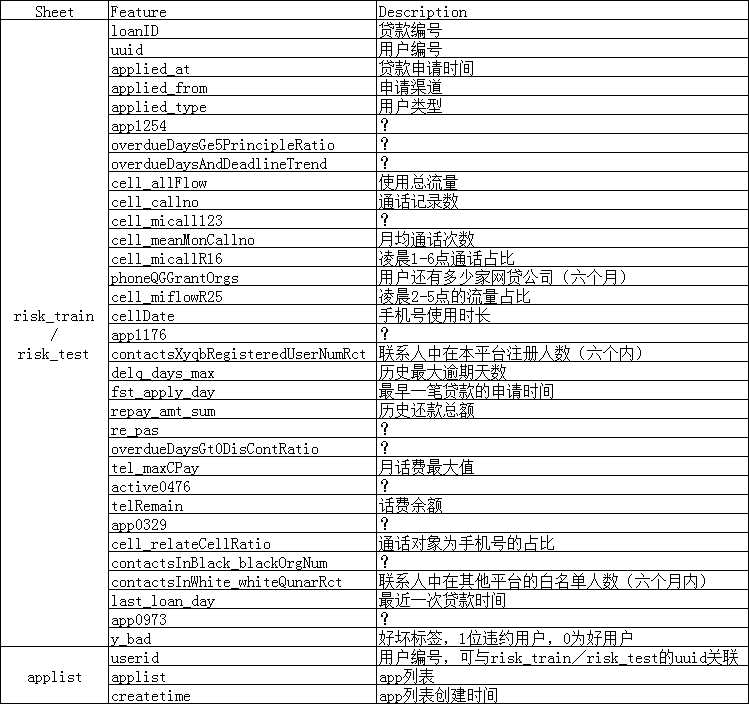
3)risk_train
4)applist
5)risk_test
我已经将2)~5)文件上传百度云盘,提取码:5fur
二、各个特征
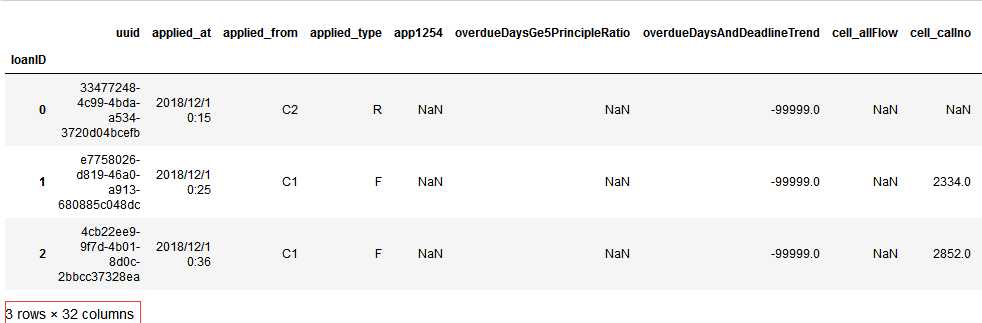
我们先来看看risk_train.csv文件:
import pandas as pd df_train = pd.read_csv(‘risk_train.csv‘, index_col=‘loanID‘) df_train.head() #这里我们已经知道了loanID存在,我们想把该列作为行索引
代码示例结果:
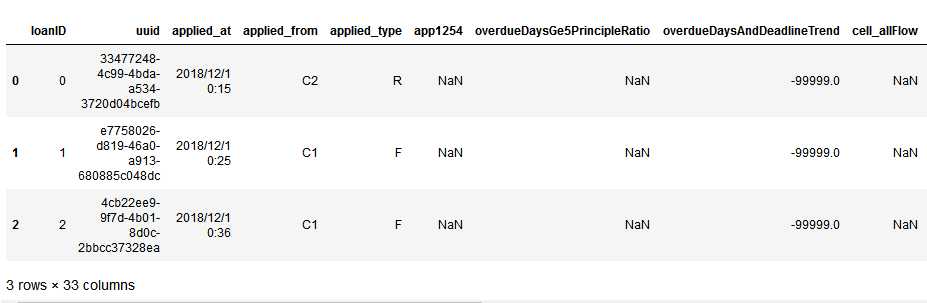
当然,如果你并不知道存在存在loadID列,可以先读入文件,然后再进行设置行索引:
import pandas as pd df_train = pd.read_csv(‘risk_train.csv‘) df_train.head(3)
代码示例结果:
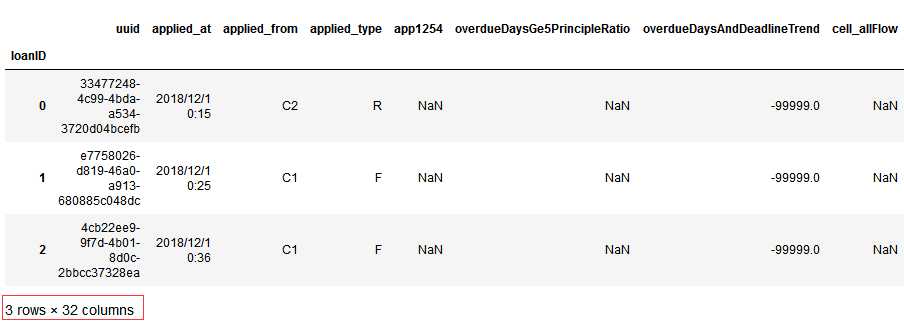
这时候我们观察了上面的结果,想将loadID设置为索引:
df_train.set_index([‘loanID‘], inplace=True) df_train.head(3)
代码示例结果:
下面我们逐一处理各个特征:
1)loadID:
这里我们读取文件时候先不将其当作行索引,我们直接将该列从df_train中drop掉,如果该列需要出现在最终的结果中,我们可以用一个临时变量去保存它
并且为了保持对train和test文件的同步处理,我们采用函数方式:
def feature_engineering(train_test_data):
df_train_test = []
for dataset in train_test_data:
#LoadID对标签的区分没有作用,直接drop
dataset.drop(‘loanID‘,axis=1, inplace=True)
print(‘Feature loanID is OK‘)
df_train_test.append(dataset)
return df_train_test
import pandas as pd
df_train = pd.read_csv(‘risk_train.csv‘)
df_test = pd.read_csv(‘risk_test.csv‘)
df_list = feature_engineering( [ df_train, df_test ] )
df_list[0].head(2)#只展示处理后df_train的前两行
代码示例结果:
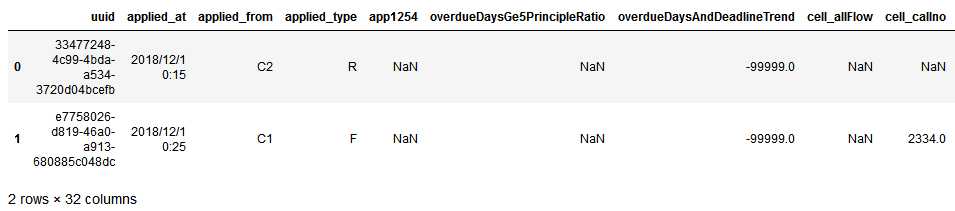
2)uuid:用户ID,这里可能存在重复值,要知道某个用户可能存在多次贷款,该列暂不处理
3)applied_at:贷款申请时间
我们先来看看时间分布:
df_list[0].applied_at#df_train df_list[1].applied_at#df_test
代码示例结果(df_train):
代码示例结果(df_test):

我们从上面的数据发现10000条train和5000条test数据,均是2018年12月份申请的,并且train和test从12月1号到25号,并没有交集,本来可以考虑将该列特征进行拆分:day和time,由于日期day没有交集,所以只将一天24小时作为特征
这里我采用方法:先提前每个贷款用户的小时点,然后进行one-hot,这里用了pd.get_dummies()方法,执行了one-hot之后将原列进行删除
import pandas as pd
#本来想applied_at进行拆分,日期Day作为一个特征,hour作为一个特征
#无奈观察到train的日期都是在1-15号,而test日期都在15-25号,所以
#这里就只把applied_at按照一天24小时进行映射:0-23
def Apply_at(x):
#day = x.split(‘ ‘)[0].split(‘/‘)[-1]
hour = x.split(‘ ‘)[1].split(‘:‘)[0]
return hour
#return day
def feature_engineering(train_test_data):
df_train_test = []
for dataset in train_test_data:
#LoadID对标签的区分没有作用,直接drop
dataset.drop(‘loanID‘,axis=1, inplace=True)
print(‘Feature loanID is OK‘)
#applied_at提取到某天的小时
dataset[‘applied_at‘] = dataset[‘applied_at‘].map(Apply_at).astype(int)
#one-hot
dataset = pd.concat( [dataset, pd.get_dummies(dataset[‘applied_at‘], prefix=‘applied_at‘)], axis=1 )
dataset.drop(‘applied_at‘,axis=1, inplace=True)
print(‘Feature applied_at is OK‘)
df_train_test.append(dataset)
return df_train_test
df_train = pd.read_csv(‘risk_train.csv‘)
df_test = pd.read_csv(‘risk_test.csv‘)
df_list = feature_engineering( [ df_train, df_test ] )
df_list[0].head(2)
代码示例结果(只展示train的结果,发现该列已经one-hot处理):

4)applied_from:申请渠道
5)applied_type:用户类型
one-hot方式和applied_at相似:
import pandas as pd
#本来想applied_at进行拆分,日期Day作为一个特征,hour作为一个特征
#无奈观察到train的日期都是在1-15号,而test日期都在15-25号,所以
#这里就只把applied_at按照一天24小时进行映射:0-23
def Apply_at(x):
#day = x.split(‘ ‘)[0].split(‘/‘)[-1]
hour = x.split(‘ ‘)[1].split(‘:‘)[0]
return hour
#return day
def feature_engineering(train_test_data):
df_train_test = []
for dataset in train_test_data:
#LoadID对标签的区分没有作用,直接drop
dataset.drop(‘loanID‘,axis=1, inplace=True)
print(‘Feature loanID is OK‘)
#applied_at提取到某天的小时
dataset[‘applied_at‘] = dataset[‘applied_at‘].map(Apply_at).astype(int)
#one-hot
dataset = pd.concat( [dataset, pd.get_dummies(dataset[‘applied_at‘], prefix=‘applied_at‘)], axis=1 )
dataset.drop(‘applied_at‘,axis=1, inplace=True)
print(‘Feature applied_at is OK‘)
#applied_from
dataset = pd.concat([dataset, pd.get_dummies(dataset[‘applied_from‘], prefix=‘applied_from‘)], axis=1)
dataset.drop(‘applied_from‘,axis=1, inplace=True)
print(‘Feature applied_from is OK‘)
#applied_type
dataset = pd.concat([dataset, pd.get_dummies(dataset[‘applied_type‘], prefix=‘applied_type‘)], axis=1)
dataset.drop(‘applied_type‘,axis=1, inplace=True)
print(‘Feature applied_type is OK‘)
df_train_test.append(dataset)
return df_train_test
df_train = pd.read_csv(‘risk_train.csv‘)
df_test = pd.read_csv(‘risk_test.csv‘)
df_list = feature_engineering( [ df_train, df_test ] )
df_list[0].head(2)
代码示例结果:

6)app1254:空值比例太高,直接drop掉
dataset.drop(‘app1254‘,axis=1, inplace=True)
7)overdueDaysGe5PrincipleRatio:?
我们先看看空值情况:
print(df_list[0][‘overdueDaysGe5PrincipleRatio‘].isnull().sum()) print(df_list[1][‘overdueDaysGe5PrincipleRatio‘].isnull().sum())
代码示例结果:
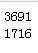
空值比例分别为36.91%和34.32%,尝试用众数填充,这里填充方法有三种:
a)直接观察法,观察到出现次数最多的是0,则用0填充
df_list[0][‘overdueDaysGe5PrincipleRatio‘].value_counts() df_list[0][‘overdueDaysGe5PrincipleRatio‘] = df_list[0][‘overdueDaysGe5PrincipleRatio‘].fillna(0) df_list[1][‘overdueDaysGe5PrincipleRatio‘].value_counts() df_list[1][‘overdueDaysGe5PrincipleRatio‘] = df_list[0][‘overdueDaysGe5PrincipleRatio‘].fillna(0)
b)先求出众数,然后填充:
Mode = dataset[‘overdueDaysGe5PrincipleRatio‘].value_counts().index[0]#求出众数 dataset[‘overdueDaysGe5PrincipleRatio‘] = dataset[‘overdueDaysGe5PrincipleRatio‘].fillna(Mode)
c)用scipy.stats模块求众数:
from scipy.stats import mode Mode = mode(dataset[‘overdueDaysGe5PrincipleRatio‘]).mode[0] dataset[‘overdueDaysGe5PrincipleRatio‘] = dataset[‘overdueDaysGe5PrincipleRatio‘].fillna(Mode)
注意上面代码中的dataset可以用df_list[0]或者df_list[1]来代替
然后我们对该特征进行归一化处理:
import sys
#Normalization Or Standardization
def Normal_Or_Standard(df_data, Feature, method):
if method == ‘Normalization‘:
return (df_data[Feature] - df_data[Feature].min()) / (df_data[Feature].max() - df_data[Feature].min())
elif method == ‘Standardization‘:
return (df_data[Feature] - df_data[Feature].mean()) / df_data[Feature].std()
else:
print(‘Please choose Normalization or Standardization‘)
sys.exit()
df_list[0][‘overdueDaysGe5PrincipleRatio‘] = Normal_Or_Standard(df_list[0], ‘overdueDaysGe5PrincipleRatio‘, ‘Normalization‘)
df_list[1][‘overdueDaysGe5PrincipleRatio‘] = Normal_Or_Standard(df_list[1], ‘overdueDaysGe5PrincipleRatio‘, ‘Normalization‘)
df_list[0][‘overdueDaysGe5PrincipleRatio‘]
代码示例结果:

8)overdueDaysAndDeadlineTrend:?
我们先看看是否存在空值:
df_list[0][‘overdueDaysAndDeadlineTrend‘].isnull().sum() df_list[1][‘overdueDaysAndDeadlineTrend‘].isnull().sum()
代码示例结果:
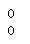
可以看出并不存在空值,我们可以利用上面的代码查看是否存在空值,以后的讲解中就不再粘贴上面查看空值代码
我们再看看值的分布:
print(df_list[0][‘overdueDaysAndDeadlineTrend‘].value_counts()) print(df_list[0][‘overdueDaysAndDeadlineTrend‘].value_counts())
代码示例结果(只展示了train中的数据):
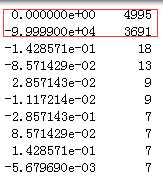
从上面的值分布看,虽然不存在空值,但是该列特征0和-99999比例占了很大,-99999这样异常大(绝对值大)数据的样本是否可以考虑扔掉?
首先我们的样本集是不平衡数据集,也就是y_bad用户本来就很少,10000条数据中只存在490个不良用户,不可轻易直接drop掉-99999的样本
考虑到我们最后需要进行下采样处理,我们需要先考虑一下这些-99999的样本中有多少个y_bad用户,如果这样的样本中y_bad用户很少,那么我们就可以采用drop掉的方法了:
df_list[0][‘y_bad‘][df_list[0][‘overdueDaysAndDeadlineTrend‘]==-99999].value_counts()
代码示例结果:
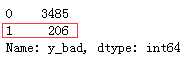
从上面的结果发现,overdueDaysAndDeadlineTrend值是-99999的样本中,y_bad用户有206个,而我们的train中总共才有490个y_bad用户,所以我们不能直接drop掉这些-99999样本,我们先来归一化:
df_list[0][‘overdueDaysAndDeadlineTrend‘] = Normal_Or_Standard(df_list[0], ‘overdueDaysAndDeadlineTrend‘, ‘Normalization‘) df_list[1][‘overdueDaysAndDeadlineTrend‘] = Normal_Or_Standard(df_list[1], ‘overdueDaysAndDeadlineTrend‘, ‘Normalization‘) df_list[0][‘overdueDaysAndDeadlineTrend‘].value_counts()
代码示例结果(展示部分):

我们发现归一化之后的数据基本上非0即1(数据很接近一),那么是否可以考虑将该列连续型值用0或者1来离散化呢?可以作为一个方法进行尝试
9)cell_allFlow:使用总流量
存在空值,先用平均值填充一下,由于范围跨度很大,考虑进行归一化:
df_list[0][‘cell_allFlow‘] = df_list[0][‘cell_allFlow‘].fillna(df_list[0][‘cell_allFlow‘].mean()) #归一化 df_list[0][‘cell_allFlow‘] = Normal_Or_Standard( df_list[0],‘cell_allFlow‘, method=‘Normalization‘ )
df_list[1]处理方式一样
10)cell_callno:通话记录数,与cell_allFlow相似的处理方法,也可以尝试用Standardization
df_list[0][‘cell_callno‘] = df_list[0][‘cell_callno‘].fillna(df_list[0][‘cell_callno‘].mean()) #归一化 df_list[0][‘cell_callno‘] = Normal_Or_Standard( df_list[0],‘cell_callno‘, method=‘Normalization‘ ) df_list[0][‘cell_callno‘]
df_list[1]处理方式一样
11)cell_micall123:?
print(df_list[0][‘cell_micall123‘].value_counts()) print(df_list[1][‘cell_micall123‘].value_counts())
代码示例结果:
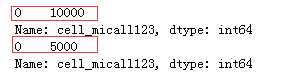
从上面的结果看:cell_micall123特征train和test全为0,对于标签区分没有作用,drop掉
df_list[0].drop(‘cell_micall123‘,axis=1, inplace=True) df_list[1].drop(‘cell_micall123‘,axis=1, inplace=True)
12)cell_meanMonCallno:月均通话次数
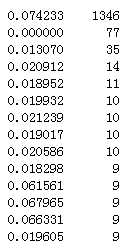
#cell_meanMonCallno空值用median()填充,然后进行标准化,不存在负值 df_list[0][‘cell_meanMonCallno‘] = df_list[0][‘cell_meanMonCallno‘].fillna(df_list[0][‘cell_meanMonCallno‘].median()) #标准化:Normalization df_list[0][‘cell_meanMonCallno‘] = Normal_Or_Standard( df_list[0], ‘cell_meanMonCallno‘, method=‘Normalization‘) df_list[0][‘cell_meanMonCallno‘].value_counts()
代码示例结果(df_list[1]处理方式一样):
13)cell_micallR16:凌晨1-6点通话占比
cell_micallR16存在空值,并且值的范围在0到1之间,考虑不用标准化,尝试用随机数填充:
#随机数填充
import numpy as np
def Random_Fillna(df_data, Feature, Num):
Mean = df_data[Feature].mean()
Min = df_data[Feature].min()
Max = df_data[Feature].max()
Std = df_data[Feature].std()
Null_count = df_data[Feature].isnull().sum()
if Num == ‘Float‘:
Produce = np.random.uniform( low=Mean - Std, high=Mean + Std, size = Null_count )
elif Num == ‘Int‘:
Produce = np.random.randint( low=Min, high=Max, size = Null_count )
return Produce
#尝试用随机数填充
df_list[0][‘cell_micallR16‘][ np.isnan(df_list[0][‘cell_micallR16‘]) ] = Random_Fillna(df_list[0], ‘cell_micallR16‘, ‘Float‘)
df_list[0][‘cell_micallR16‘] = df_list[0][‘cell_micallR16‘].astype(float)
df_list[0][‘cell_micallR16‘].value_counts()
df_list[1]处理方式一样
14)phoneQGGrantOrgs:用户还有多少家网贷公司(六个月)
先来看看空值数目和值分布:
print(df_list[0][‘phoneQGGrantOrgs‘].isnull().sum()) print(df_list[0][‘phoneQGGrantOrgs‘].value_counts())
代码示例结果(df_list[1]处理方式一样):
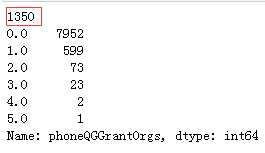
众数填充:
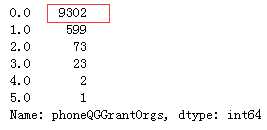
#众数填充 Mode = df_list[0][‘phoneQGGrantOrgs‘].value_counts().index[0] df_list[0][‘phoneQGGrantOrgs‘] = df_list[0][‘phoneQGGrantOrgs‘].fillna(Mode) print(df_list[0][‘phoneQGGrantOrgs‘].value_counts())
代码示例结果(df_list[1]处理方式一样):
15)cell_miflowR25:凌晨2-5点的流量占比
print(df_list[0][‘cell_miflowR25‘].isnull().sum()) print(df_list[1][‘cell_miflowR25‘].isnull().sum())
代码示例结果:
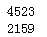
空值比例还是蛮高的,尝试用随机数填充:
#尝试用随机数填充 df_list[0][‘cell_miflowR25‘][ np.isnan(df_list[0][‘cell_miflowR25‘]) ] = Random_Fillna(df_list[0], ‘cell_miflowR25‘, ‘Float‘) df_list[0][‘cell_miflowR25‘] = df_list[0][‘cell_miflowR25‘].astype(float) df_list[0][‘cell_miflowR25‘].value_counts()
代码示例结果(df_list[1]处理方式一样)
16)cellDate:手机号使用时长
print(df_list[0][‘cellDate‘].isnull().sum()) #cellDate:空值较多,约40%,median()填充并标准化 df_list[0][‘cellDate‘] = df_list[0][‘cellDate‘].fillna(df_list[0][‘cellDate‘].median()) #标准化:Normalization df_list[0][‘cellDate‘] = Normal_Or_Standard( df_list[0], ‘cellDate‘, method=‘Normalization‘)
代码示例结果(df_list[1]处理方式一样):
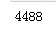
17)app1176:?
#app1176?空值比例达到98%靠上(9882/10000),考虑直接drop df_list[0].drop(‘app1176‘,axis=1, inplace=True)
df_list[1]处理方式一样
18)contactsXyqbRegisteredUserNumRct:联系人中在本平台注册人数(六个内)
#contactsXyqbRegisteredUserNumRct,空值用范围内的随机数填充 #随机值填充 df_list[0][‘contactsXyqbRegisteredUserNumRct‘][ np.isnan(df_list[0][‘contactsXyqbRegisteredUserNumRct‘]) ] = Random_Fillna(df_list[0], ‘contactsXyqbRegisteredUserNumRct‘, ‘Int‘) df_list[0][‘contactsXyqbRegisteredUserNumRct‘] = Normal_Or_Standard( df_list[0], ‘contactsXyqbRegisteredUserNumRct‘, method=‘Normalization‘) df_list[0][‘contactsXyqbRegisteredUserNumRct‘].value_counts()
代码示例结果(df_list[1]处理方式一样):
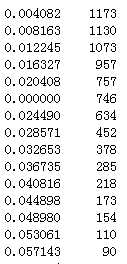
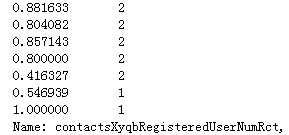
19)delq_days_max:历史最大逾期天数
#delq_days_max空值约占37%,用随机数填充 df_list[0][‘delq_days_max‘][ np.isnan(df_list[0][‘delq_days_max‘]) ] = Random_Fillna(df_list[0], ‘delq_days_max‘, ‘Int‘) df_list[0][‘delq_days_max‘] = df_list[0][‘delq_days_max‘].astype(int) df_list[0][‘delq_days_max‘] = Normal_Or_Standard( df_list[0], ‘delq_days_max‘, method=‘Normalization‘) df_list[0][‘delq_days_max‘].value_counts()
填充前:
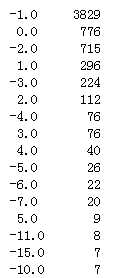
填充后:
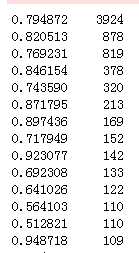
这里的处理方式是否合适,还得再考虑一下
20)fst_apply_day:最早一笔贷款的申请时间
#fst_apply_day用随机数填充 df_list[0][‘fst_apply_day‘][ np.isnan(df_list[0][‘fst_apply_day‘]) ] = Random_Fillna(df_list[0], ‘fst_apply_day‘, ‘Int‘) df_list[0][‘fst_apply_day‘] = df_list[0][‘fst_apply_day‘].astype(int) df_list[0][‘fst_apply_day‘] = Normal_Or_Standard( df_list[0], ‘fst_apply_day‘, method=‘Normalization‘) df_list[0][‘fst_apply_day‘]
代码示例结果(df_list[1]处理方式一样):
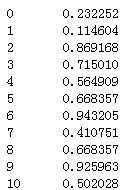
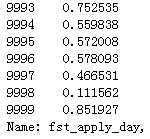
21)repay_amt_sum:历史还款总额
#repay_amt_sum用随机数填充 df_list[0][‘repay_amt_sum‘][ np.isnan(df_list[0][‘repay_amt_sum‘]) ] = Random_Fillna(df_list[0], ‘repay_amt_sum‘, ‘Int‘) df_list[0][‘repay_amt_sum‘] = df_list[0][‘repay_amt_sum‘].astype(int) df_list[0][‘repay_amt_sum‘] = Normal_Or_Standard( df_list[0], ‘repay_amt_sum‘, method=‘Normalization‘) df_list[0][‘repay_amt_sum‘]
代码示例结果(df_list[1]处理方式一样):
22)re_pas:?
print(df_list[0][‘re_pas‘].isnull().sum()) print(df_list[0][‘re_pas‘].min(), df_list[0][‘re_pas‘].max()) print(df_list[1][‘re_pas‘].isnull().sum()) print(df_list[1][‘re_pas‘].min(), df_list[1][‘re_pas‘].max())
代码示例结果:

从上面的结果看,re_pas不存在空值,但是train中范围在0-66,test在66-100,考虑将其离散化?
这里进行归一化操作:
df_list[0][‘re_pas‘] = Normal_Or_Standard(df_list[0], ‘re_pas‘, ‘Normalization‘) df_list[1][‘re_pas‘] = Normal_Or_Standard(df_list[1], ‘re_pas‘, ‘Normalization‘)
代码示例结果(只展示了df_list[0]的):

23)overdueDaysGt0DisContRatio:?
print(df_list[0][‘overdueDaysGt0DisContRatio‘].isnull().sum()) df_list[0][‘overdueDaysGt0DisContRatio‘][np.isnan(df_list[0][‘overdueDaysGt0DisContRatio‘])] = Random_Fillna(df_list[0], ‘overdueDaysGt0DisContRatio‘, ‘Float‘) print(df_list[1][‘overdueDaysGt0DisContRatio‘].isnull().sum()) df_list[1][‘overdueDaysGt0DisContRatio‘][np.isnan(df_list[1][‘overdueDaysGt0DisContRatio‘])] = Random_Fillna(df_list[1], ‘overdueDaysGt0DisContRatio‘, ‘Float‘)
代码示例结果(只展示了df_list[0]的):

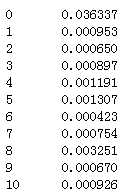
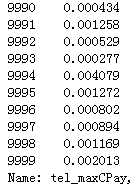
24)tel_maxCPay:月话费最大值
随机值填充,标准化:
print(df_list[0][‘tel_maxCPay‘].isnull().sum()) df_list[0][‘tel_maxCPay‘][np.isnan(df_list[0][‘tel_maxCPay‘])] = Random_Fillna(df_list[0], ‘tel_maxCPay‘, ‘Int‘) print(df_list[1][‘tel_maxCPay‘].isnull().sum()) df_list[1][‘tel_maxCPay‘][np.isnan(df_list[1][‘tel_maxCPay‘])] = Random_Fillna(df_list[1], ‘tel_maxCPay‘, ‘Int‘) df_list[0][‘tel_maxCPay‘] = Normal_Or_Standard(df_list[0], ‘tel_maxCPay‘, ‘Normalization‘) df_list[1][‘tel_maxCPay‘] = Normal_Or_Standard(df_list[1], ‘tel_maxCPay‘, ‘Normalization‘) df_list[0][‘tel_maxCPay‘]
代码示例结果(标准化处理后只展示df_list[0]的):
25)active0476:?
print(df_list[0][‘active0476‘].isnull().sum()) print(df_list[1][‘active0476‘].isnull().sum()) df_list[0].drop(‘active0476‘,axis=1,inplace=True) df_list[1].drop(‘active0476‘,axis=1,inplace=True)
代码示例结果:空值太多,直接drop掉
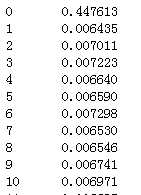
26)telRemain:话费余额
随机填充并归一化:
#telRemain 空值约13%,用随机值填充 df_list[0][‘telRemain‘][ np.isnan(df_list[0][‘telRemain‘]) ] = Random_Fillna(df_list[0], ‘telRemain‘, ‘Int‘) df_list[1][‘telRemain‘][ np.isnan(df_list[1][‘telRemain‘]) ] = Random_Fillna(df_list[1], ‘telRemain‘, ‘Int‘) df_list[0][‘telRemain‘] = Normal_Or_Standard(df_list[0], ‘telRemain‘, ‘Normalization‘) df_list[1][‘telRemain‘] = Normal_Or_Standard(df_list[1], ‘telRemain‘, ‘Normalization‘) df_list[0][‘telRemain‘]
代码示例结果(标准化处理后只展示df_list[0]的):
27)app0329:?
print(df_list[0][‘app0329‘].isnull().sum()) print(df_list[1][‘app0329‘].isnull().sum()) df_list[0].drop(‘app0329‘,axis=1,inplace=True) df_list[1].drop(‘app0329‘,axis=1,inplace=True)
代码示例结果:空值太多,直接drop掉
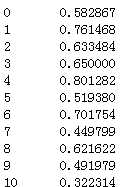
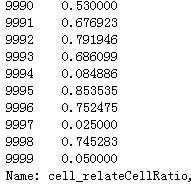
28)cell_relateCellRatio:通话对象为手机号的占比
用平均值填充:
df_list[0][‘cell_relateCellRatio‘] = df_list[0][‘cell_relateCellRatio‘].fillna(df_list[0][‘cell_relateCellRatio‘].mean()) df_list[0][‘cell_relateCellRatio‘]
代码示例结果(只展示df_list[0]的):
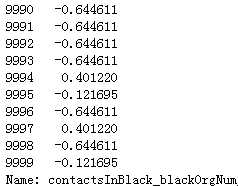
29)contactsInBlack_blackOrgNum:?
contactsInBlack_blackOrgNum不知道啥特征,不过和cell_relateCellRatio相关,空值比例都一样,平均值填充,然后标准化,这里只展示了train的处理
df_list[0][‘contactsInBlack_blackOrgNum‘] = df_list[0][‘contactsInBlack_blackOrgNum‘].fillna(df_list[0][‘contactsInBlack_blackOrgNum‘].mean()) df_list[0][‘contactsInBlack_blackOrgNum‘] = Normal_Or_Standard(df_list[0], ‘contactsInBlack_blackOrgNum‘, ‘Standardization‘) df_list[0][‘contactsInBlack_blackOrgNum‘]
代码示例结果(只展示df_list[0]的):

30)contactsInWhite_whiteQunarRct:联系人中在其他平台的白名单人数(六个月内)
众数填充:
#众数填充 Mode = df_list[0][‘contactsInWhite_whiteQunarRct‘].value_counts().index[0] df_list[0][‘contactsInWhite_whiteQunarRct‘] = df_list[0][‘contactsInWhite_whiteQunarRct‘].fillna(Mode) print(df_list[0][‘contactsInWhite_whiteQunarRct‘].value_counts())
代码示例结果(只展示df_list[0]的):

31)last_loan_day:最近一次贷款时间
last_loan_day:不存在空值,但是这个特征中含有多个-99999,与verdueDaysAndDeadlineTrend有什么关系吗?还是这个-99999是自己造的值呢?
df_list[0][‘last_loan_day‘] = Normal_Or_Standard(df_list[0], ‘last_loan_day‘, ‘Normalization‘) df_list[1][‘last_loan_day‘] = Normal_Or_Standard(df_list[1], ‘last_loan_day‘, ‘Normalization‘) df_list[0][‘last_loan_day‘]
代码示例结果(只展示df_list[0]的):


32)app0973:空值太多,drop掉
df_list[0].drop(‘app0973‘,axis=1,inplace=True)
代码示例结果(只展示drop掉df_list[0]的)
33)y_bad:好坏标签,1位违约用户,0为好用户
三、applist处理
我们的目的是为train和test中的用户增加applist特征信息,初步方案是根据applist文件构建word2vec,然后将train和test中的用户app列表转换为特征矩阵
我们先来看看applist.csv文件:
df_app = pd.read_csv(‘applist.csv‘,encoding=‘gbk‘) df_app.head()
代码示例结果:

1)构建word2vec:
from gensim.models import Word2Vec
class Applist_Process:
def Applist_Produce(self, filename):
App_list = []
Uuid = []
with open(filename) as app:
app.readline()#跳过header
for eachline in app:
eachline = eachline.replace(‘\n‘,‘‘)
temp_list = []
array = eachline.strip().split(‘,‘, 1)
uuid = array[0]
App_time = array[1]
Uuid.append(uuid)
for eachapp in App_time.split(‘##‘)[0:-1]:
eachapp = eachapp.strip()
temp_list.append(eachapp)
App_list.append(temp_list)
return App_list, dict(zip(Uuid, App_list))
def Word2vec(self, app_list):
word2vec_model = Word2Vec(app_list, size=100, iter=10, min_count=3)
word2vec_model.save( ‘word2vec_model.w2v‘ )
return word2vec_model
def getVector(self, app_of_each_id, word2vec_model):
i = 0
index2word_set = set(word2vec_model.wv.index2word)
applist_vector = np.zeros((word2vec_model.layer1_size))
for eachapp in app_of_each_id:
if eachapp in index2word_set:
applist_vector = np.add(applist_vector, word2vec_model.wv[eachapp] )
i += 1
applist_vector = np.around(np.divide(applist_vector, i),3)
return applist_vector
#Begin处理Applist.csv
AP = Applist_Process()
#app_list:#获取所有用户的app_list,这是个嵌套列表,每个列表元素为每个用户的app列表
#uuid_app_dict:key=uuid, value=该用户applist
app_list, uuid_app_dict = AP.Applist_Produce(‘applist.csv‘)
word2vec_model = AP.Word2vec( app_list )
代码示例解释:获得word2vec模型及用户对应的applist
vector_list_train = []
num = 0
for eachid in X_train_uuid:
num += 1
if eachid in uuid_app_dict:
vector_list_train.append( AP.getVector(uuid_app_dict[eachid], word2vec_model) )
else:
vector_list_train.append( [0 for i in range(100)] )
print( ‘The %dth uuid in train finished‘ % num )
vector_list_test = []
num = 0
for eachid in X_test_uuid:
num += 1
if eachid in uuid_app_dict:
vector_list_test.append( AP.getVector(uuid_app_dict[eachid], word2vec_model) )
else:
vector_list_test.append( np.around(np.random.uniform(0, 0.001, 100),3) )
print( ‘The %dth uuid in test finished‘ % num )
print(‘Applist process finished‘)
代码示例解释:注意上面的X_train_uuid和X_test_uuid分别是训练集和测试集中的uuid特征
经过上面的处理,我们就可以根据applist文件,利用pd.concat()为train和test中的每个用户增加新的特征
经过上面的数据处理过程之后我们进行模型构建与训练预测过程,请读者参考:风控-贷款审批一模型训练,预测
标签:ase com 最大值 img 绝对值 tar ring reg 手机
原文地址:https://www.cnblogs.com/always-fight/p/10536645.html