标签:sheet rop file 创建 日志采集 1.7 结果 sync port
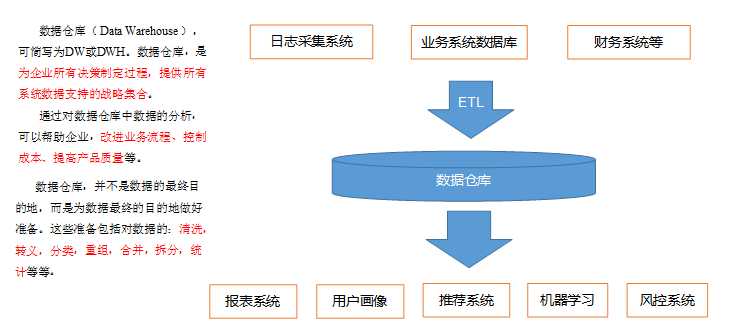
数据仓库DW
数据来源:
爬虫 日志采集系统 业务数据 财务系统
数据去向:
报表系统、用户画像
推荐系统、机器学习、风控系统
① 数据采集平台搭建
② 实现用户行为数据仓库的分层搭建
③ 实现业务数据仓库的分层搭建
④ 针对数据仓库中的数据进行,留存、转化率、GMV(每天交易额)、复购率、活跃等报表行为;
技术选型

Hadoop集群 端口号、配置文件、JDK、读写流程
采集:
方式一: log日志--->flume--->kafka(API)--->hdfs; 方式二: Logstash(读取日志)-->ELK(存储查询)全文检索引擎-sqoop
DataX导数据; mysql->sqoop
存储:mysql(存储业务--分析结果) ;ES(存、查都很快)<---->HBase(存快,分析慢); S3
计算:Tez(分析hive中指标)&hive; Flink--Spark
查询:Presto,Impala,Kylin
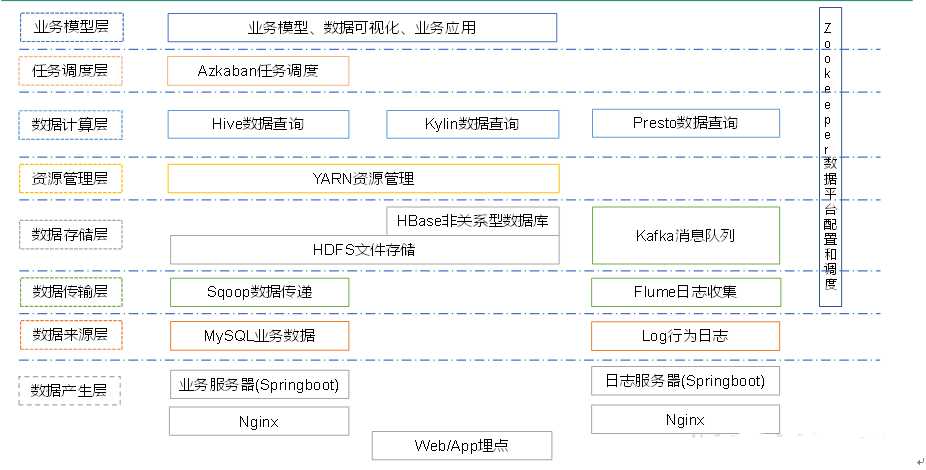
系统架构图:
日志文件|mysql数据表---分别由flume|sqoop处理--分别交给-->kafka| HDFS
由Yarn统一调度
Hive| Presto负责数据查询;
Azkaban任务调度器
最后可视化;
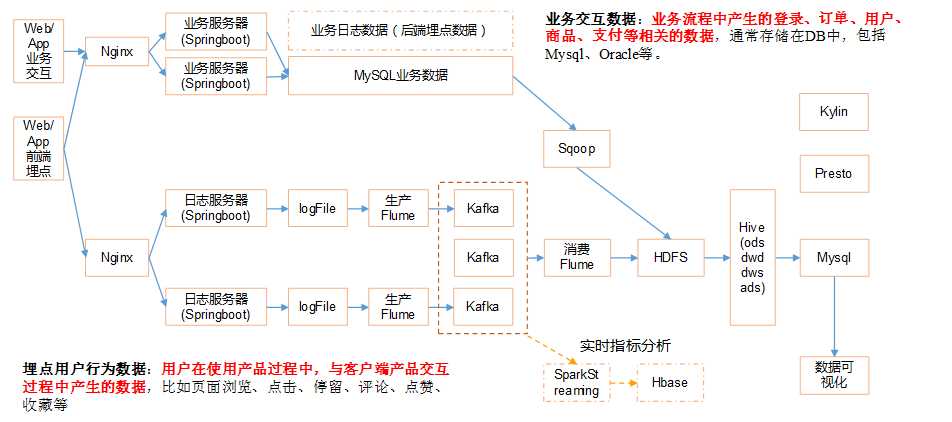
系统数据流程:
Web/App埋点行为数据->log日志服务器(友盟-第三方日志服务器)->logFile格式->Flume生产-->kafka(kafka(相当于路由池)可以接实时数据、es等)--flume消费-->HDFS
业务交互-->mysql(业务服务器-->Nginx实现负载均衡)->sqoop-->>hdfs--->hive数仓-->把结果存储到mysql
框架版本选型 产品 版本 Hadoop 2.7.2 Flume 1.7.0 Kafka 0.11.0.2 Kafka Manager 1.3.3.22 Hive 1.2.1 Sqoop 1.4.6 MySQL 5.6.24 Azkaban 2.5.0 Java 1.8 Zookeeper 3.4.10 Presto 0.189 集群资源规划设计 服务器hadoop101 服务器hadoop102 服务器hadoop103 HDFS NameNode DataNode DataNode
DataNode SecondaryNameNode Yarn NodeManager Resourcemanager NodeManager
NodeManager Zookeeper Zookeeper Zookeeper Zookeeper Flume(采集日志) Flume Flume Kafka Kafka Kafka Kafka Flume(消费Kafka) Flume Hive Hive MySQL MySQL Presto Presto
数据生成模块
埋点数据:
ap(产品字段如多个app)
①公共字段
cm(公共字段基本所有安卓手机都包含的字段); cm公共字段;json对象
et事件; et事件字段:json数组
②业务字段(埋点上报的字段,有具体的业务类型)
事件日志的设计:
①商品列表页(loading)

action 动作:开始加载=1,加载成功=2,加载失败=3 loading_time 加载时长:计算下拉开始到接口返回数据的时间,(开始加载报0,加载成功或加载失败才上报时间) loading_way 加载类型:1-读取缓存,2-从接口拉新数;(加载成功才上报加载类型) extend1 扩展字段 Extend1 extend2 扩展字段 Extend2 type 加载类型:自动加载=1,用户下拽加载=2,底部加载=3(底部条触发点击底部提示条/点击返回顶部加载) type1 加载失败码:把加载失败状态码报回来(报空为加载成功,没有失败)
②商品点击(display)
action 动作:曝光商品=1,点击商品=2, goodsid 商品ID(服务端下发的ID) place 顺序(第几条商品,第一条为0,第二条为1,如此类推) extend1 曝光类型:1 - 首次曝光 2-重复曝光(没有使用) category 分类ID(服务端定义的分类ID)
③商品详情页(newsdetail)详情页从哪来
entry 页面入口来源:应用首页=1、push=2、详情页相关推荐=3 action 动作:开始加载=1,加载成功=2(pv),加载失败=3, 退出页面=4 goodsid 商品ID(服务端下发的ID) show_style 商品样式:0、无图、1、一张大图、2、两张图、3、三张小图、4、一张小图、5、一张大图两张小图 news_staytime 页面停留时长:从商品开始加载时开始计算,到用户关闭页面所用的时间。若中途用跳转到其它页面了,则暂停计时,待回到详情页时恢复计时。或中途划出的时间超过10分钟,则本次计时作废,不上报本次数据。如未加载成功退出,则报空。 loading_time 加载时长:计算页面开始加载到接口返回数据的时间 (开始加载报0,加载成功或加载失败才上报时间) type1 加载失败码:把加载失败状态码报回来(报空为加载成功,没有失败) category 分类ID(服务端定义的分类ID)
④广告(ad)
entry 入口:商品列表页=1 应用首页=2 商品详情页=3 action 动作:请求广告=1 取缓存广告=2 广告位展示=3 广告展示=4 广告点击=5 content 状态:成功=1 失败=2 detail 失败码(没有则上报空) source 广告来源:admob=1 facebook=2 ADX(百度)=3 VK(俄罗斯)=4 behavior 用户行为:主动获取广告=1 ;被动获取广告=2 newstype Type: 1- 图文 2-图集 3-段子 4-GIF 5-视频 6-调查 7-纯文 8-视频+图文 9-GIF+图文 0-其他 show_style 内容样式:无图(纯文字)=6 一张大图=1 三站小图+文=4 一张小图=2 一张大图两张小图+文=3 图集+文 = 5 一张大图+文=11 GIF大图+文=12 视频(大图)+文 = 13 来源于详情页相关推荐的商品,上报样式都为0(因为都是左文右图)
⑤消息通知(notification)
action 动作:通知产生=1,通知弹出=2,通知点击=3,常驻通知展示(不重复上报,一天之内只报一次)=4 type 通知id:预警通知=1,天气预报(早=2,晚=3),常驻=4 ap_time 客户端弹出时间 content 备用字段
⑥用户前台活跃(active_foreground)
push_id 推送的消息的id,如果不是从推送消息打开,传空 access 1.push 2.icon 3.其他
⑦用户后台活跃(active_background)
active_source 1=upgrade,2=download(下载),3=plugin_upgrade
⑧ 评论(comment)
序号 字段名称 字段描述 字段类型 长度 允许空 缺省值 1 comment_id 评论表 int 10,0 2 userid 用户id int 10,0 √ 0 3 p_comment_id 父级评论id(为0则是一级评论,不为0则是回复) int 10,0 √ 4 content 评论内容 string 1000 √ 5 addtime 创建时间 string √ 6 other_id 评论的相关id int 10,0 √ 7 praise_count 点赞数量 int 10,0 √ 0 8 reply_count 回复数量 int 10,0 √ 0
⑨收藏(favorites)
序号 字段名称 字段描述 字段类型 长度 允许空 缺省值 1 id 主键 int 10,0 2 course_id 商品id int 10,0 √ 0 3 userid 用户ID int 10,0 √ 0 4 add_time 创建时间 string √
10 点赞(praise)
序号 字段名称 字段描述 字段类型 长度 允许空 缺省值 1 id 主键id int 10,0 2 userid 用户id int 10,0 √ 3 target_id 点赞的对象id int 10,0 √ 4 type 点赞类型 1问答点赞 2问答评论点赞 3 文章点赞数4 评论点赞 int 10,0 √ 5 add_time 添加时间 string √
11 错误日
errorBrief 错误摘要
errorDetail 错误详情
12启动日志数据start action=1可以算成前台活跃
entry 入口: push=1,widget=2,icon=3,notification=4, lockscreen_widget =5 open_ad_type 开屏广告类型: 开屏原生广告=1, 开屏插屏广告=2 action 状态:成功=1 失败=2 loading_time 加载时长:计算下拉开始到接口返回数据的时间,(开始加载报0,加载成功或加载失败才上报时间) detail 失败码(没有则上报空) extend1 失败的message(没有则上报空)
sdk软件开发工具
12个主题(1个appbase公共日志)对应12张表, 1张启动日志表,
启动日志1张表-->离线和实时; 需要写flume的拦截器
事件日志kafka的事件event主题 11个; 分的越细越灵活,
将生成的jar包log-collector-0.0.1-SNAPSHOT-jar-with-dependencies.jar拷贝到hadoop101服务器上,并同步到hadoop102的/opt/module路径下 [kris@hadoop101 module]$ xsync log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar 在hadoop102上执行jar程序 [kris@hadoop101 module]$ java -classpath log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar com.atguigu.appclient.AppMain >/opt/module/test.log 在/tmp/logs路径下查看生成的日志文件 [kris@hadoop101 module]$ cd /tmp/logs/ [kris@hadoop101 logs]$ ls
Linux环境变量配置:
(1)修改/etc/profile文件:所有用户的Shell都有权使用这些环境变量。
(2)修改~/.bashrc文件:针对某一个特定的用户,如果你需要给某个用户权限使用这些环境变量,你只需要修改其个人用户主目录下的.bashrc文件就可以了。
(3)配置登录远程服务器立即source一下环境变量
[kris@hadoop101 ~]$ cat /etc/profile >> .bashrc
[kris@hadoop102 ~]$ cat /etc/profile >> .bashrc
[kris@hadoop103 ~]$ cat /etc/profile >> .bashrc
日志生成集群启动脚本
[kris@hadoop101 bin]$ vim lg.sh #!/bin/bash for i in hadoop101 hadoop102 do ssh $i "java -classpath /opt/module/logcollector-1.0-SNAPSHOT-jar-with-dependencies.jar com.atguigu.appclient. AppMain >/opt/module/test.log &" done 修改脚本执行权限 [kris@hadoop101 bin]$ chmod +x lg.sh 启动脚本 [kris@hadoop101 module]$ lg.sh
集群时间同步修改脚本
在/home/kris/bin目录下创建脚本dt.sh [kris@hadoop101 bin]$ vim dt.sh #!/bin/bash log_date=$1 for i in hadoop101 hadoop102 hadoop103 do ssh $i "sudo date -s $log_date" done 修改脚本执行权限 [kris@hadoop101 bin]$ chmod 777 dt.sh 启动脚本 [kris@hadoop101 bin]$ dt.sh 2019-2-10
集群所有进程查看脚本; 在/home/kris/bin目录下创建脚本xcall.sh
[kris@hadoop101 bin]$ vim xcall.sh #!/bin/bash for i in hadoop101 hadoop102 hadoop103 do echo ----------$i------------ ssh $i "$*" done 修改脚本执行权限 [kris@hadoop101 bin]$ chmod 777 xcall.sh 启动脚本 [kris@hadoop101 bin]$ xcall.sh jps
服务器hadoop101 服务器hadoop102 服务器hadoop103 HDFS NameNode DataNode DataNode
DataNode SecondaryNameNode Yarn NodeManager Resourcemanager NodeManager
NodeManager
https://www.cnblogs.com/shengyang17/p/10274391.html
添加LZO支持包
输入端采用压缩DEFLATE(deflate)压缩
mapper输出之后采用LZO或snappy
reducer输出之后gzip或bzip2
1)下载后的文件名是hadoop-lzo-master,它是一个zip格式的压缩包,先进行解压,然后用maven编译。生成hadoop-lzo-0.4.20。
2)将编译好后的hadoop-lzo-0.4.20.jar 放入hadoop-2.7.2/share/hadoop/common/[kris@hadoop101 software]$ mv hadoop-lzo-0.4.20.jar /opt/module/hadoop-2.7.2/share/hadoop/common/
[kris@hadoop101 common]$ ls
hadoop-lzo-0.4.20.jar
3)同步hadoop-lzo-0.4.20.jar到hadoop103、hadoop104
[kris@hadoop101 common]$ xsync hadoop-lzo-0.4.20.jar
2 添加配置
1)core-site.xml增加配置支持LZO压缩
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>io.compression.codecs</name> <value> org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.SnappyCodec, com.hadoop.compression.lzo.LzoCodec, com.hadoop.compression.lzo.LzopCodec </value> </property> <property> <name>io.compression.codec.lzo.class</name> <value>com.hadoop.compression.lzo.LzoCodec</value> </property> </configuration>
2)同步core-site.xml到hadoop102、hadoop103
[kris@hadoop101 hadoop]$ xsync core-site.xml
服务器hadoop101 服务器hadoop102 服务器hadoop103
Zookeeper Zookeeper Zookeeper Zookeeper
详细安装见:
https://www.cnblogs.com/shengyang17/p/10325484.html
zookeeper集群启动脚本;
chmod 777 zk.sh
[kris@hadoop101 bin]$ vim zk.sh #!/bin/bash case $1 in "start"){ for i in hadoop101 hadoop102 hadoop103 do ssh $i "/opt/module/zookeeper-3.4.10/bin/zkServer.sh start" done };; "stop"){ for i in hadoop101 hadoop102 hadoop103 do ssh $i "/opt/module/zookeeper-3.4.10/bin/zkServer.sh stop" done };; esac
https://flume.apache.org/releases/content/1.7.0/FlumeUserGuide.html 可使用ctrl+F搜索
服务器hadoop101 服务器hadoop102 服务器hadoop103
Flume(采集日志) Flume Flume
详细安装见:
https://www.cnblogs.com/shengyang17/p/10405979.html
日志采集Flume启动停止脚本
在/home/kris/bin目录下创建脚本f1.sh;并添加执行权限;chmod +x f1.sh
[kris@hadoop101 bin]$ vim f1.sh #!/bin/bash case $1 in "start"){ for i in hadoop101 hadoop102 do echo "------------启动 $i 采集flume数据-----------" ssh $i "nohup /opt/module/flume/bin/flume-ng agent -f /opt/module/flume/conf/file-flume-kafka.conf -n a1 -Dflume.r oot.logger=INFO,LOGFILE >/dev/null 2>&1 &" done };; "stop"){ for i in hadoop101 hadoop102 do echo "------------停止 $i 采集flume数据------------" ssh $i "ps -ef | grep file-flume-kafka | grep -v grep | awk ‘{print \$2}‘ | xargs kill" done };; esac
nohup,该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。nohup就是不挂起的意思,不挂断地运行命令。
详细安装见:
https://www.cnblogs.com/shengyang17/p/10443115.html
详细见:
https://www.cnblogs.com/shengyang17/p/10459101.html
启动KafkaManager
[kris@hadoop101 kafka-manager-1.3.3.22]$ nohup bin/kafka-manager -Dhttp.port=7456 >/opt/module/kafka-manager-1.3.3.22/start.log 2>&1 &
至此,就可以查看整个Kafka集群的状态,包括:Topic的状态、Brokers的状态、Cosumer的状态。
在kafka的/opt/module/kafka-manager-1.3.3.22/application.home_IS_UNDEFINED 目录下面,可以看到kafka-manager的日志。
Kafka Manager启动停止脚本
1)在/home/kris/bin目录下创建脚本km.sh; chmod +x km.sh
[kris@hadoop101 bin]$ vim km.sh
#!/bin/bash case $1 in "start"){ echo "---------启动KafkaManager---------" nohup /opt/module/kafka-manager/bin/kafka-manager -Dhttp.port=7456 >/opt/module/kafka-manager/start.log 2>&1 & };; "stop"){ echo "---------停止KafkaManager---------" ps -ef | grep ProdServerStart | grep -v grep | awk ‘{print $2}‘ | xargs kill };; esac
用Kafka官方自带的脚本,对Kafka进行压测。Kafka压测时,可以查看到哪个地方出现了瓶颈(CPU,内存,网络IO)。一般都是网络IO达到瓶颈。
kafka-consumer-perf-test.sh
kafka-producer-perf-test.sh
(1)在/opt/module/kafka/bin目录下面有这两个文件。我们来测试一下
[kris@hadoop101 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-recor 100000 --throughput 1000 --producer-props bootstrap.servers=hadoop101:9092,hadoop102:9092,hadoop103:9092 5000 records sent, 1000.0 records/sec (0.10 MB/sec), 2.6 ms avg latency, 183.0 max latency. 5012 records sent, 1002.4 records/sec (0.10 MB/sec), 1.0 ms avg latency, 36.0 max latency. 5001 records sent, 1000.2 records/sec (0.10 MB/sec), 0.6 ms avg latency, 8.0 max latency. 5001 records sent, 1000.2 records/sec (0.10 MB/sec), 0.4 ms avg latency, 22.0 max latency. 5001 records sent, 1000.0 records/sec (0.10 MB/sec), 0.6 ms avg latency, 45.0 max latency. 5002 records sent, 1000.2 records/sec (0.10 MB/sec), 0.3 ms avg latency, 3.0 max latency. 5001 records sent, 1000.2 records/sec (0.10 MB/sec), 0.8 ms avg latency, 27.0 max latency. 5001 records sent, 1000.0 records/sec (0.10 MB/sec), 0.5 ms avg latency, 54.0 max latency. 5001 records sent, 1000.0 records/sec (0.10 MB/sec), 0.7 ms avg latency, 60.0 max latency. 5003 records sent, 1000.4 records/sec (0.10 MB/sec), 0.4 ms avg latency, 29.0 max latency. 5000 records sent, 1000.0 records/sec (0.10 MB/sec), 0.7 ms avg latency, 50.0 max latency. 5001 records sent, 1000.2 records/sec (0.10 MB/sec), 0.9 ms avg latency, 82.0 max latency. 5003 records sent, 1000.2 records/sec (0.10 MB/sec), 0.4 ms avg latency, 32.0 max latency. 5000 records sent, 1000.0 records/sec (0.10 MB/sec), 0.8 ms avg latency, 67.0 max latency. 5002 records sent, 1000.2 records/sec (0.10 MB/sec), 0.9 ms avg latency, 80.0 max latency. 5002 records sent, 1000.0 records/sec (0.10 MB/sec), 0.4 ms avg latency, 18.0 max latency. 5000 records sent, 1000.0 records/sec (0.10 MB/sec), 0.9 ms avg latency, 75.0 max latency. 5001 records sent, 1000.2 records/sec (0.10 MB/sec), 0.5 ms avg latency, 23.0 max latency. 5003 records sent, 1000.2 records/sec (0.10 MB/sec), 0.5 ms avg latency, 26.0 max latency. 100000 records sent, 999.950002 records/sec (0.10 MB/sec), 0.72 ms avg latency, 183.00 ms max latency, 0 ms 50th, 1 ms 95th, 3 ms 99th, 44 ms 99.9th
测试生成了多少数据,消费了多少数据;每条信息大小,总共发送的条数;每秒多少条数据;
说明:record-size是一条信息有多大,单位是字节。num-records是总共发送多少条信息。throughput 是每秒多少条信息。
参数解析:本例中一共写入10w条消息,每秒向Kafka写入了0.10MB的数据,平均是1000条消息/秒,每次写入的平均延迟为0.72毫秒,最大的延迟为183毫秒。
Consumer的测试,如果这四个指标(IO,CPU,内存,网络)都不能改变,考虑增加分区数来提升性能。
[kris@hadoop103 kafka]$ bin/kafka-consumer-perf-test.sh --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181 --topic topic_event --fetch-size 10000 --messages 10000000 --threads 1 start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec 2019-03-15 00:04:21:474, 2019-03-15 00:04:21:740, 1.1851, 4.4551, 1492, 5609.0226
参数说明:
--zookeeper 指定zookeeper的链接信息
--topic 指定topic的名称
--fetch-size 指定每次fetch的数据的大小
--messages 总共要消费的消息个数
测试结果说明:
开始测试时间,结束测试时间;最大吞吐率1.1851MB/S;最近每秒消费4.4551MB/S;最大每秒消费1492条;平均每秒消费5609.0226条;
Kafka机器数量(经验公式)=2*(峰值生产速度*副本数/100)+1
先要预估一天大概产生多少数据,然后用Kafka自带的生产压测(只测试Kafka的写入速度,保证数据不积压),计算出峰值生产速度。再根据设定的副本数,就能预估出需要部署Kafka的数量。
比如我们采用压力测试测出写入的速度是10M/s一台,峰值的业务数据的速度是50M/s。副本数为2。
Kafka机器数量=2*(50*2/100)+1=3台
详细安装:
https://www.cnblogs.com/shengyang17/p/10372242.html
Hive运行引擎Tez
1)下载tez的依赖包:http://tez.apache.org 2)拷贝apache-tez-0.9.1-bin.tar.gz到hadoop102的/opt/module目录 [kris@hadoop101 module]$ ls apache-tez-0.9.1-bin.tar.gz 3)解压缩apache-tez-0.9.1-bin.tar.gz [kris@hadoop101 module]$ tar -zxvf apache-tez-0.9.1-bin.tar.gz 4)修改名称 [kris@hadoop101 module]$ mv apache-tez-0.9.1-bin/ tez-0.9.1
1)进入到Hive的配置目录:/opt/module/hive/conf [kris@hadoop101 conf]$ pwd /opt/module/hive/conf 2)在hive-env.sh文件中添加tez环境变量配置和依赖包环境变量配置 [kris@hadoop101 conf]$ vim hive-env.sh 添加如下配置
# Set HADOOP_HOME to point to a specific hadoop install directory export HADOOP_HOME=/opt/module/hadoop-2.7.2 # Hive Configuration Directory can be controlled by: export HIVE_CONF_DIR=/opt/module/hive/conf # Folder containing extra libraries required for hive compilation/execution can be controlled by: export TEZ_HOME=/opt/module/tez-0.9.1 #是你的tez的解压目录 export TEZ_JARS="" for jar in `ls $TEZ_HOME |grep jar`; do export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/$jar done for jar in `ls $TEZ_HOME/lib`; do export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/lib/$jar done export HIVE_AUX_JARS_PATH=/opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar$TEZ_JARS
3)在hive-site.xml文件中添加如下配置,更改hive计算引擎
<property> <name>hive.execution.engine</name> <value>tez</value> </property>
配置Tez
1)在Hive 的/opt/module/hive/conf下面创建一个tez-site.xml文件 [kris@hadoop101 conf]$ pwd /opt/module/hive/conf [kris@hadoop101 conf]$ vim tez-site.xml 添加如下内容
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>tez.lib.uris</name> <value>${fs.defaultFS}/tez/tez-0.9.1,${fs.defaultFS}/tez/tez-0.9.1/lib</value> </property> <property> <name>tez.lib.uris.classpath</name> <value>${fs.defaultFS}/tez/tez-0.9.1,${fs.defaultFS}/tez/tez-0.9.1/lib</value> </property> <property> <name>tez.use.cluster.hadoop-libs</name> <value>true</value> </property> <property> <name>tez.history.logging.service.class</name> <value>org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService</value> </property> </configuration>
上传Tez到集群
1)将/opt/module/tez-0.9.1上传到HDFS的/tez路径 [kris@hadoop101 conf]$ hadoop fs -mkdir /tez [kris@hadoop101 conf]$ hadoop fs -put /opt/module/tez-0.9.1/ /tez [kris@hadoop101 conf]$ hadoop fs -ls /tez /tez/tez-0.9.1
测试
1)启动Hive [kris@hadoop101 hive]$ bin/hive 2)创建LZO表 hive (default)> create table student( id int, name string); 3)向表中插入数据 hive (default)> insert into student values(1,"zhangsan"); 4)如果没有报错就表示成功了 hive (default)> select * from student; 1 zhangsan
小结
1)运行Tez时检查到用过多内存而被NodeManager杀死进程问题:
这种问题是从机上运行的Container试图使用过多的内存,而被NodeManager kill掉了。
解决方法:
方案一:或者是关掉虚拟内存检查。我们选这个,修改yarn-site.xml
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
方案二:mapred-site.xml中设置Map和Reduce任务的内存配置如下:(value中实际配置的内存需要根据自己机器内存大小及应用情况进行修改)
<property> <name>mapreduce.map.memory.mb</name> <value>1536</value> </property> <property> <name>mapreduce.map.java.opts</name> <value>-Xmx1024M</value> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>3072</value> </property> <property> <name>mapreduce.reduce.java.opts</name> <value>-Xmx2560M</value> </property>
标签:sheet rop file 创建 日志采集 1.7 结果 sync port
原文地址:https://www.cnblogs.com/shengyang17/p/10527700.html
