标签:replica add address names port hadoop2 tab gen .sh
用来测试,我在VMware下用Centos7搭起一个三节点的Hadoop完全分布式集群。其中NameNode和DataNode在同一台机器上,如果有条件建议大家把NameNode单独放在一台机器上,因为NameNode是集群的核心承载压力是很大的。hadoop版本:Hadoop-2.7.4;
|
hadoopo1 |
hadoopo2 |
hadoopo3 |
| Namenode | ResourceManage | SecondaryNamenode |
| Datanode | Datanode | Datanode |
| NodeManage | NodeManage | NodeManage |
一、准备环境
hadoop-2.7.4.tar.gz,hadoop2.x安装包;
二、部署集群
三、修改配置文件(hadoop01节点)
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
<!-- hadoop01:主机名,9000:端口 -->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
<!-- secondaryNamenode地址 -->
<property>
<name>dfs.secondary.http.address</name>
<value>hadoop03:50090</value>
</property>
<!-- 数据块冗余份数-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- edtis文件存放地址-->
<property>
<name>dfs.namenode.edits.dir</name>
<value>/data/hadoop/namenode/name</value>
</property>
<!-- datanode数据目录存放地址-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/datanode/data</value>
</property>
<!-- checkpoint数据目录存放地址-->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/data/hadoop/namenode/namesecondary</value>
</property>
<!-- 集群调度框架为YARN--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 注意:"hadoop01"替换为NameNode所在主机名--> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop01:19888</value> </property>
<!--resourcemanager主机名 --> <!-- 注意:"hadoop02"替换为resourcemanager所在主机名--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop02</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>hadoop02:8088</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>3000</value> </property> <!--nodemanager最多分配cpu虚拟核心个数 --> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>4</value> </property> <!--nodemanager最多内存大小 --> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>3000</value> </property> <!--作业调度过程中 作业单个内存最少内存大小 --> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>500</value> </property> <!--作业调度过程中 作业单个最多的cpu分配 --> <property> <name>yarn.scheduler.maximum-allocation-vcores</name> <value>4</value> </property>
hadoop01
hadoop02
hadoop03
四、创建数据目录
五、配置hadoop环境变量(三节点)
su – root
vim /etc/profile
//在文件末尾添加如下设置
//最后更新环境变量(root/hadoop)
source /etc/profile
HADOOP_HOME=/home/hadoop/install/hadoop-2.7.4 PATH=$PATH:$HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
六、配置SSH互信(三节点)
192.168.1.10 hadoop01 192.168.1.11 hadoop02 192.168.1.12 hadoop03


七、分发hadoop安装目录(hadoop01)
scp –r ~/install hadoop@hadoop02:~/install
scp –r ~/install hadoop@hadoop03:~/install
八、格式化并且启动HDFS(重点)
C$AWBT5A5")

九、启动集群

H$576_F4")
NW")


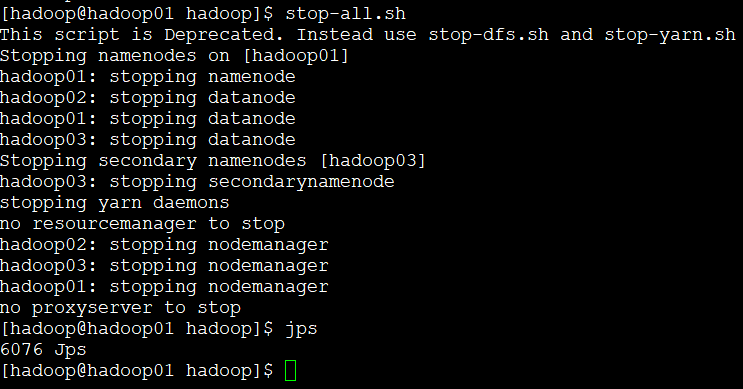
十、关闭集群
标签:replica add address names port hadoop2 tab gen .sh
原文地址:https://www.cnblogs.com/luomeng/p/10630904.html
{kind=link}