标签:follow span ons ble llb original 爬虫 定义 spider
定义一些规则用于提取页面符合规则的数据,然后继续爬取。
scrapy startproject 项目名称
cd 项目名称/项目名称/spiders
scrapy genspider -t crawl 爬虫名称 域名
scrapy crawl 爬虫名称
scrapy startproject dushu cd dushu/dushu/spiders scrapy genspider -t crawl ds www.dushu.com
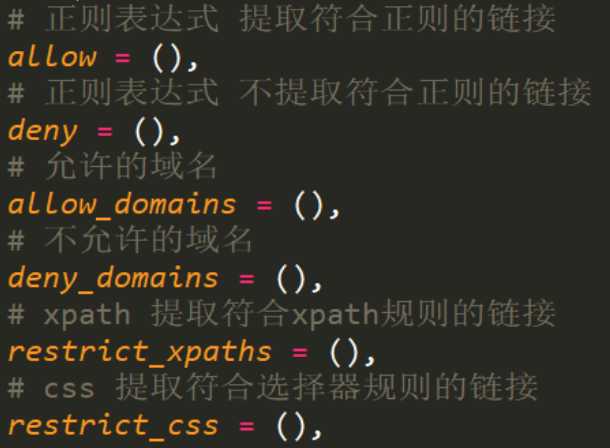
class DsSpider(CrawlSpider): name = ‘ds‘ allowed_domains = [‘www.dushu.com‘] start_urls = [‘https://www.dushu.com/book/1163_1.html‘] rules = ( Rule(LinkExtractor(allow=r‘/book/1163_\d+.html‘), callback=‘parse_item‘, follow=True), )
def parse_item(self, response): item = {} div_list = response.xpath(‘//div[@class="bookslist"]/ul/li/div‘) for div in div_list: item[‘src‘] = div.xpath(‘./div/a/img/@data-original‘).extract_first() item[‘alt‘] = div.xpath(‘./div/a/img/@alt‘).extract_first() item[‘author‘] = div.xpath(‘./p[1]/a[1]/text()|./p[1]/text()‘).extract_first() yield item
class DushuPipeline(object): def open_spider(self,spider): self.fp = open(‘dushu.json‘,‘w‘,encoding=‘utf-8‘) def process_item(self, item, spider): # obj = json.loads(str(item)) # str = json.dumps(obj,ensure_ascii=False) self.fp.write(str(item)) return item def close_spider(self,spider): self.fp.close()
# Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = ‘Mozilla/4.0 (compatible; MSIE 6.0; AOL 9.0; Windows NT 5.0;‘ # Obey robots.txt rules ROBOTSTXT_OBEY = False
scrapy crawl ds
标签:follow span ons ble llb original 爬虫 定义 spider
原文地址:https://www.cnblogs.com/huanggaoyu/p/10656459.html