标签:分支 位置 规则 lazy x86_64 mamicode 修改 https 简单的
【小宅按】近期公司推出来基于ARM芯片的服务器,本文就一些基本概念,比如ARM, ARM64, ARMv8, ARM7,ARMv7, 64位等让人费解的概念进行了粗浅地分析,涉及的关键字已用粗体标出。文中观点仅仅是一家之言,拙劣之处,欢迎斧正。
https://zhuanlan.zhihu.com/p/66348633 华为官网的账号
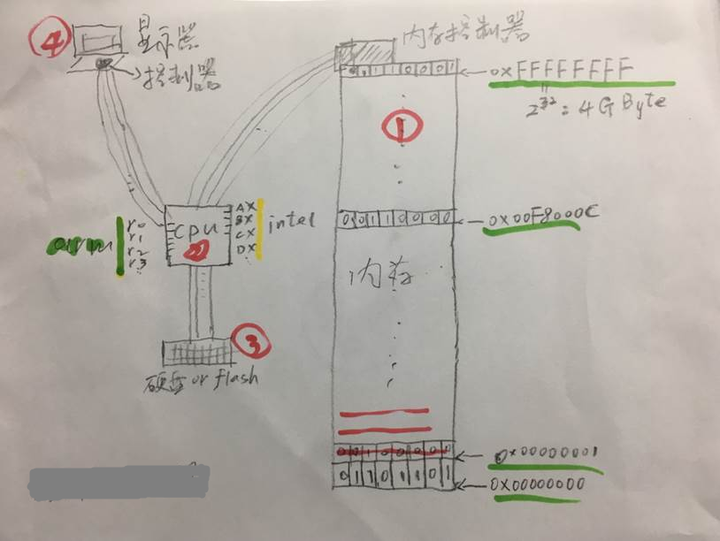 (图1)
(图1)
基本原理(记住1Byte=8bit):
电子计算机本质上是通过给三极管 (或MOS管用半导体材料如硅和硒制成的) 的基极输送不同的电压(大于或小于0.7伏特,再讲就深了,今天先不讲了),进而控制三极管对电容进行充电和放电,实际是通过控制电子的流动(所以叫做电子计算机,个人理解),抽象出0和1的表示。图1中红线标出的内存,每行可以理解为8个电容,由内存控制器控制充放电以及读取电压,充电状态(与地电压(电势差)大于3.3V)表示1,放电状态(电压小于1.8V)表示0,红线部分的宽度永远是8bit,不会变。有专门的的电路对这些电容的充放电状态进行读取,比如读到了某Byte的8个电容是00000110,就表示十进制数字6,(当然也有可能理解为96,比如某些摩托罗拉芯片下,大尾或小尾从左还是从右开始算的区别,超出本文讨论范围)
驱动:
简单来说,CPU与内存之间通过若干根连线(地址、控制、数据总线)来交互信息,比如把0x00F800C这个内存地址的第2个BIT位写为1,就会触发显卡读取某些内存地址里的内容并显示到显示器上。(实际上显示设备和内存之间也有连线,实现DMA操作,深了今天不讲)。当然为什么写第2个BIT位就能触发某种动作,这是人为规定的,叫做架构规范,架构后面通过一系列复杂的电路来实现这个规定,比如intelx86规定内存地址0x00F800C的第2个BIT位写1可以触发显示动作,而ARMv8架构下,虽然同样都是触发显示动作,但不一定是操作这个位。这就是两种架构的差异。如果你作为程序员,编写Intelx86架构下的显卡驱动程序,实际是在编写程序来操作0x00F800C地址Byte的第2个BIT位。这个特定位是通过将基地址+偏移写进芯片的datasheet来告知芯片应用者(公司)的。比如这个例子中,0x00F8000是基地址,而C是偏移,用0x00F8000+0x0C来表示实际地址。这是一个极其聪明和有用的规定,这样做的好处,后面章节会详细描述。
64位与32位:是指图1中的绿线和黄线标出的部分,在32位CPU模式下,某个地址是十六进制表示为00F8000C,这里每个数字包含4个二进制bite位,共32位。而64位状态下,这个数字实际是 0000000000F8000C,有64个bit位。在CPU内部有寄存器,intel 80x86架构的寄存器名称是ax,bx,cx等,而ARM架构下是r0,r1,r2,r3,r4,r5等,寄存器的宽度也分32位和64位。在ARMv7以及以前的架构中,只有32位。在2013年ARM推出64位架构ARMv8,寄存器是64位宽,相应的寄存器名称为x0,x1,x2,x3等。在C语言中,64位和32位的差异体现在sizeof(指针)上,实际代表的是内存地址的宽度,注意是图1中绿线标出的宽度,不是红线,红线永远是8bit宽,不要混淆。
指令集:
CPU读取硬盘或FLASH的上物理位置从0到4K之间的一段二进制流,这段流称为程序,这段程序的大小就是4K,CPU把这段程序写入内存地址0x00000000到0x00001000 (这里0x00001000=4096=4K),之后,CPU内的PC寄存器内写入0x00000000,表示从内存地址0处开始执行机器指令。本质是读出该地址后4个地址(指令长度规定,指令周期涉及CPU主频,再讲就深了,后面再开贴)中共4Byte长度的二进制数字,比如读到了52800e01,这个数字实际上对应的是一套电路编号,执行的操作是add r0,r1,意思是将r0和r1中存放的数字相加,把结果写进r0,这个过程实际上是调用编号为52800e01的电路来完成的,而这种不同编号的电路的集合,就是所谓的指令集。Intel CPU用的是复杂指令集CISC(Complex Instruction Set Computer),前面说的add r0,r1,这是一个CPU指令,实际对应一套复杂的电路实现(包含若干电阻电容MOS等)。intel80x86系统有300条指令,就表示至少有300套不同的电路来实现这300个功能。 而ARM采用的是精简指令集RISC(Reduced Instruction Set Computer),有100条指令,实际对应100套不同的电路装置来实现这100个功能。我们用一个简单的C语言函数来剖析RISC和CISC的区别:
int test_mul(void)
{
return 6*8;
}
这个函数算出6乘以8,返回结果,我们来看看实际执行时,CISC和RISC的差别(此处为了简洁明了的阐述我们的问题,实际过程比这个复杂,我们提纲挈领,再讲就深了,后面有空再开贴)

(图2
从图中可以看出,同样是实现6乘以8的功能,RISC用加法来实现,把8连续加了6次,也就是说调用了6次add电路来实现的,而CISC直接调用乘法电路,实现了6*8,你可以粗浅地理解为RISC很精简,没有乘法电路。当然,随着CPU技术的发展,RISC和CISC一直在互相学习,取长补短慢慢融合了,目前界限已没有那么明显。从例子可以看出,CISC程序编码简单。而RISC程序编码相对复杂,因为电路种类较少,实现同样的功能需要用仅有的电路来变通实现。C语言编译器和操作系统共同作用,屏蔽了这种差异中的大部分内容,使得不同芯片环境下,实现相同功能的代码变得大同小异(记住是大同小异,实际还是有差异)。
理解了RISC和CISC,我们再来谈谈ARM。在单片机时代,有很多设计以及制造芯片的公司,比如飞利浦,飞思卡尔,意法半导体,ARM,恩智浦等公司,当然,领头羊还是Intel.这些公司中ARM比较独特,他依托牛津剑桥科研实力,不做具体的芯片,只设计指令集(电路),这些人很聪明,他们深知,市面上存在多种芯片,但实现原理都是大同小异,所以他们专注于研发各种科学且合理的指令电路的设计,并将自己的设计形成了规范,这个规范就是ARMvX架构,从8位时代的ARMv1,到32位的ARMv7,再到64位的ARMv8又叫ARM64,这些不同的架构规范,后面对应的一整套RISC指令集,也就是电路图,ARM公司的商业模式是出售指令集授权。比如ARM公司将ARMv4的指令集(电路图)工艺以及实现样片等打包授权给卖三星公司,三星拿到的是ARMv3的核心架构设计图纸,里面包含了RISC 指令集的实现电路图,三星在这个核架构的基础上添加自己的外设,比如I2C模块及引脚、GPU显示增强模块及引脚、汽车内网络CAN模块及引脚,AI人工智能计算模块等,将CPU核以及这些外设模块集成到一块芯片中,命名为ARM7-S3C44B0X芯片,另一款基于ARMv5架构生产出的芯片产品命名为S5P4418-ARM9等,投放市场出售。
至此,你应该明白了ARM,ARMv7以及ARM7的概念了,ARMv7是架构名,ARM7是基于ARMv3架构生产的一个芯片的产品名称。到ARM11芯片之后,ARM公司更改了芯片的命名规则,由老的ARMx改为 Cortex系列,简言之:
Cortex-M系列:M-Profile,即"Microcontroller" -Profile,侧重微控制器单片机方面的场合。
Cortex-R系列:R-Profile,即"Real-Time"-Profile,侧重于实时系统的场合。
Cortex-A系列: A-Profile,即“Application”-Profile,侧重于应用功能的场合。
比如我司生产的Hi3798mv200芯片,大的架构基于ARMv8(又叫ARM64)的,而ARMv8中又有Cortex A53分支,准确表达应该是:华为Hi3798mv200是基于ARMv8的Cortex-A53系列的一款芯片。下面是从wiki百科扣的图,从中可以窥出ARM家族的架构和产品系列的一斑。
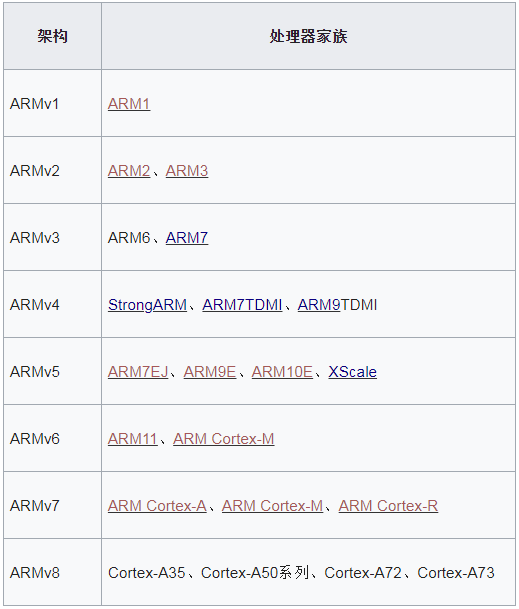
基于统一标准的ARMvX架构标准制造出的芯片,好处非常多,生产芯片的目的是显然是为了运行应用程序。一个典型的场景是linux操作系统的应用,华为和三星生产了两款不同的cortex A53芯片,内核架构是相同的,不同的是外设基地址,请参考前面“驱动”章节的描述。Linux操作系统移植到华为和三星的这两款芯片上,只需要修改相关外设所对应的的头文件中的基地址就可完成大部分功能的移植(注意是大部分,不是全部),当然这依赖于linux开源系统优秀的设计。基于linux以及android系统之上的应用,也实现了统一,基本不会出现一个app既要开发基于三星芯片的版本,又要开发基于华为芯片的另外一个版本的情况,从而推进了移动互联网生态链的大发展(请对比考虑基于X86 linux和基于armv8 linux的确是需要开发两套不同的APP版本的情况),ARM统一架构的好处是显而易见的。Intel显然已经意识到这种优势,自己也买了ARM的授权,推出相应的“ARM核”芯片产品。
划重点,有助于理解,试想这样一个场景:有四款cpu,分别是1.intel x86_64,2.三星Cortex a57,3.华为Cortex a53,4.博通bcm2837,这4款cpu运行的都是64位linux 4.0,现在有个app要上市,请问这个app需要上架几个不同版本?答案是两个,intelx86一个,其他三个同一个。?为什么是两个?根本原因是前面所说的指令集和驱动。
最后,再来谈谈我司推出的ARM芯片服务器,从本质上来看,我认为这种服务器在功耗方面与Intel x86系列差别不大,这是数字电路的原理使然,VOH和VOL(请百度)的逻辑电平是一样的,差别在于电路工艺以及散热等系统的设计。 我个人粗浅地认为,ARM服务器的优势有两点:
1.生态优势,主要是基于ARM linux 之上的应用产业链,前文已有阐述。
2.开源优势,因为ARM的生态链上公司很多,各个公司在商业实践过程中会产生各种新的改良建议和想法,ARM架构集中了太多的智慧,而Intel实际是在单打独斗。一个典型的例子就是ARM的SIMD技术:NEON(下一篇我会结合NEON实例来聊GPU、人工智能、TPU)。
更多精彩内容,请滑至顶部点击右上角关注小宅哦~
标签:分支 位置 规则 lazy x86_64 mamicode 修改 https 简单的
原文地址:https://www.cnblogs.com/jinanxiaolaohu/p/10893555.html