标签:style blog class code java c
k-近邻算法原理:
存在一个样本的数据集合,也叫训练的样本集,样本集中每个数据都有标签,算法分类时,输入没有分类的新数据,将新数据的每个特征与样本集中每个数据对应的特征进行比较,然后样本集可以计算得到与新数据的相似度,然后取前k(通常不大于20)大相似度所对应的类标签,然后将新数据标识为k个中类标签最多的标签。
例子:
使用k-近邻算法识别博客园注册时的验证码。
使用的工具如下:
具体的流程如下:
//========================================================
收集验证码:
使用python编写网络爬虫爬取博客园的验证码,一个能使用的代码如下:

#-*- encoding: utf-8 -*- ‘‘‘ Created on 2014年5月13日 @author: jsy ‘‘‘ import os import re import urllib import time def get_html(url): page = urllib.urlopen(url) html = page.read() page.close() return html def get_image_urls(html): reg = r‘/ValidCodeImage.aspx\?id=\S{14}‘ reg_com = re.compile(reg) image_urls = re.findall(reg_com, html) return image_urls def download_file(url, outpath): if not os.path.exists(outpath): os.mkdir(outpath) tmp_file_name = outpath + ‘/‘ + str(time.strftime(‘%Y%m%d%H%M%S‘)) + ‘.jpg‘ urllib.urlretrieve(‘http://passport.cnblogs.com‘ + url, tmp_file_name) if __name__ == ‘__main__‘: url = ‘http://passport.cnblogs.com/register.aspx?ReturnUrl=http://www.cnblogs.com/‘ outpath = ‘valid_code‘ for i in range(1000): html = get_html(url) image_urls = get_image_urls(html) for j in image_urls: download_file(j, outpath) time.sleep(1)
爬取的验证码如下:
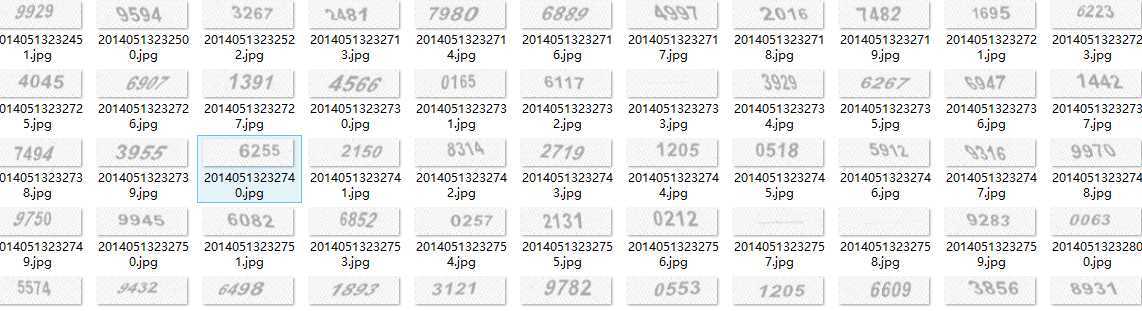
//=============================================
分割验证码中的数字并分类,作为用于k-近邻算法识别数字的训练集。分割的代码如下,主要使用了一下图像处理的方法,比如腐蚀等
#-*- encoding: utf-8 -*- ‘‘‘ Created on 2014年5月14日 @author: jsy ‘‘‘ import os import cv2 def segment_num(image): blured_image = cv2.GaussianBlur(image, (3, 3), 0) retval, binary_image = cv2.threshold(blured_image, 128, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU) # struct_element = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 2)) # binary_image = cv2.dilate(binary_image, struct_element) binary_image = cv2.bitwise_not(binary_image) # cv2.imshow(‘binary image1‘, binary_image) contours, hierarchy = cv2.findContours(binary_image, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE) num_rects = [] for c in contours: num_rects.append(cv2.boundingRect(c)) if num_rects[-1][3] < image.shape[0] / 2: num_rects.pop() continue # cv2.rectangle(image, (num_rects[-1][0], num_rects[-1][1]), (num_rects[-1][0] + num_rects[-1][2], num_rects[-1][1] + num_rects[-1][3]), (0, 0, 0)) # print num_rects # cv2.drawContours(image, contours, -1, (0)) # cv2.imshow(‘original image‘, image) # cv2.imshow(‘binary image‘, binary_image) # cv2.waitKey(-1) return num_rects if __name__ == ‘__main__‘: in_path = ‘valid_code‘ out_path = ‘segmented_numbers‘ filename = os.listdir(in_path) nums = 0 for f in filename: if f[-3:] != ‘jpg‘: continue print f image = cv2.imread(in_path + ‘/‘ + f, cv2.CV_LOAD_IMAGE_GRAYSCALE) num_rects = segment_num(image) # print num_rects for rect in num_rects: tmp_file = out_path + ‘/‘ + str(nums) + ‘.jpg‘ nums += 1 cv2.imwrite(tmp_file, image[rect[1] : (rect[1] + rect[3]), rect[0] : (rect[0] + rect[2])])
分割出数字的效果(已经分类好的0):

然后做好分类:
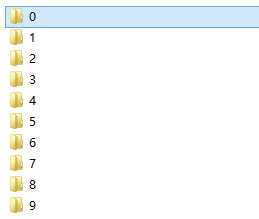
然后使用kNN算法识别数字,代码如下:
#-*- encoding: utf-8 -*- ‘‘‘ Created on 2014年5月13日 @author: jsy ‘‘‘ import os, sys from numpy import * import operator COM_WIDTH = 32 COM_HEIGHT = 32 TRAINING_NUMS = 100 def createDataSet(): group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]]) labels = [‘A‘, ‘A‘, ‘B‘, ‘B‘] return group, labels def autoNorm(filename): import cv2 gray = cv2.imread(filename, 0) gray_resize = cv2.resize(gray, (COM_WIDTH, COM_HEIGHT)) gray_resize = gray_resize * 1.0 gray_norm = cv2.normalize(gray_resize); return reshape(gray_norm, (1, COM_WIDTH * COM_HEIGHT)) def autoNorm2(gray): import cv2 gray_resize = cv2.resize(gray, (COM_WIDTH, COM_HEIGHT)) gray_resize = gray_resize * 1.0 gray_norm = cv2.normalize(gray_resize); return reshape(gray_norm, (1, COM_WIDTH * COM_HEIGHT)) def loadDataSet(path): nums = os.listdir(path) trainingGroup = [] trainingLabels = [] testingGroup = [] testingLabels = [] for n in nums: tmp_nums = os.listdir(path + ‘/‘ + n) trainingNum = 0 for tn in tmp_nums: if tn == ‘Thumbs.db‘: continue tmp_norm_num = autoNorm(path + ‘/‘ + n + ‘/‘ + tn) if trainingNum >= TRAINING_NUMS: testingGroup.append(tmp_norm_num[0,:]) testingLabels.append(int(n)) else: trainingGroup.append(tmp_norm_num[0,:]) trainingLabels.append(int(n)) trainingNum += 1 return trainingGroup, trainingLabels, testingGroup, testingLabels def kNN_distance(inX, inY): pass def kNN(inX, dataSet, labels, k): dataSetSize = dataSet.shape[0] #训练集中样本的个数 diffMat = tile(inX, (dataSetSize, 1)) - dataSet #输入向量与训练集的差 sqDiffMat = diffMat ** 2 #求差的平方 sqDistances = sqDiffMat.sum(axis = 1) #求和 distances = sqDistances ** 0.5 #开方 sortedDistIndicies = distances.argsort() #距离从小到大排序 classCount = {} for i in range(k): #去前k个最小距离的分类标签 voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 #统计前k个最小距离中分类标签出现的次数 #求前k个最小距离中分类标签出现最多的标签 sortedClassCount = sorted(classCount.iteritems(), key = operator.itemgetter(1), reverse = True) return sortedClassCount[0][0] if __name__ == ‘__main__‘: # group, labels = createDataSet() # print kNN([0, 0], group, labels, 3) path = ‘trainingData‘ k = 10 pnum = [0] * 10 nnum = [0] * 10 trainingGroup, trainingLabels, testingGroup, testingLabels = loadDataSet(path) savetxt(‘trainingGroup.txt‘, trainingGroup) savetxt(‘trainingLabels.txt‘, trainingLabels) trainingGroup = loadtxt(‘trainingGroup.txt‘) trainingLabels = loadtxt(‘trainingLabels.txt‘) for i in range(len(testingGroup)): result = kNN(testingGroup[i], array(trainingGroup), trainingLabels, k) result = int(result) print result, testingLabels[i] if result != testingLabels[i]: nnum[int(testingLabels[i])] += 1 else: pnum[int(testingLabels[i])] += 1 print ‘positive nums: ‘, pnum print ‘negative nums: ‘, nnum print ‘准确率:‘, 1.0 * sum(pnum) / len(testingGroup) print ‘错误率:‘, 1.0 * sum(nnum) / len(testingGroup)
识别的结果如下:

positive nums是指每个数字对于识别对的个数
negative nums是指每个数字对应识别错的个数
准确率达到0.99214...
效果看起来不错
//====================================================================
然后就是集成上面的代码
#-*- encoding: utf-8 -*- ‘‘‘ Created on 2014??5??15?? @author: jsy ‘‘‘ import os from numpy import * import cv2 import segment_numbers import kNN if __name__ == ‘__main__‘: path = ‘valid_code‘ filenames = os.listdir(path) trainingGroup = loadtxt(‘trainingGroup.txt‘) trainingLabels = loadtxt(‘trainingLabels.txt‘) for f in filenames: gray = cv2.imread(path + ‘/‘ + f, 0) num_rects = segment_numbers.segment_num(gray) num_rects = sorted(num_rects) result = ‘‘ for r in num_rects: sub_gray = gray[r[1] : r[1] + r[3], r[0] : r[0] + r[2]] sub_gray_norm = kNN.autoNorm2(sub_gray) rr = kNN.kNN(sub_gray_norm, trainingGroup, trainingLabels, 10) rr = int(rr) result += str(rr) cv2.imshow(‘sample‘, gray) print result cv2.waitKey(1000)
整个识别验证码的效果如下:
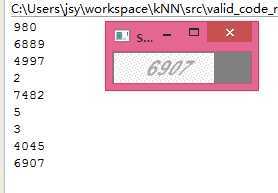
//================================================
打包代码:http://pan.baidu.com/s/1qWx0Nm8
标签:style blog class code java c
原文地址:http://www.cnblogs.com/zjwzcnjsy/p/3729077.html