标签:reads cuda https share eof 运行速度 tar lte manage
共享内存(shared memory)是位于SM上的on-chip(片上)一块内存,每个SM都有,就是内存比较小,早期的GPU只有16K(16384),现在生产的GPU一般都是48K(49152)。
共享内存由于是片上内存,因而带宽高,延迟小(较全局内存而言),合理使用共享内存对程序效率具有很大提升。
下面是使用共享内存对一个数组进行求和,使用全局内存进行归约求和可以浏览https://www.cnblogs.com/xiaoxiaoyibu/p/11397205.html
#pragma once #include "cuda_runtime.h" #include "device_launch_parameters.h" #include "device_functions.h" #include <iostream> using namespace std; const int N = 128; //数组长度 __global__ void d_ParallelTest(double *Para) { int tid = threadIdx.x; //----使用shared memory-------------------------------------------------------------- __shared__ double s_Para[N]; //定义长度为N的共享内存数组 if (tid < N) //循环整个数组,每个线程负责将一个元素从全局内存载入共享内存 s_Para[tid] = Para[tid]; __syncthreads(); //(红色下波浪线提示由于VS不识别,不影响运行)同步,等待所有线程把自己负责的元素载入到共享内存再执行下面代码
for (int index = 1; index < blockDim.x; index *= 2) {
__syncthreads(); //同步,以防止归约过程中某个线程运行速度过快导致计算错误(后面线程计算使用错误的前面线程结果值)
if (tid % (2 * index) == 0)
{
s_Para[tid] += s_Para[tid + index];
}
}
if (tid == 0) //整个数组相加完成后,将共享内存数组0号元素的值赋给全局内存数组0号元素,最后返回CPU端
Para[tid] = s_Para[tid];
}
void ParallelTest()
{
double *Para;
cudaMallocManaged((void **)&Para, sizeof(double) * N); //统一内存寻址,CPU和GPU都可以使用
double ParaSum = 0;
for (int i=0; i<N; i++)
{
Para[i] = (i + 1) * 0.1; //数组赋值
ParaSum += Para[i]; //CPU端数组累加
}
cout << " CPU result = " << ParaSum << endl; //显示CPU端结果
double d_ParaSum;
d_ParallelTest << < 1, N>> > (Para); //调用核函数(一个包含N个线程的线程块)
cudaDeviceSynchronize(); //等待设备端同步
d_ParaSum = Para[0]; //从累加过后数组的0号元素得出结果
cout << " GPU result = " << d_ParaSum << endl; //显示GPU端结果
}
int main()
{
//并行归约
ParallelTest();
system("pause");
return 0;
}
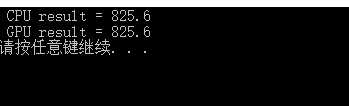
结果如下(CPU和GPU结果一致):
CUDA学习(五)之使用共享内存(shared memory)进行归约求和
标签:reads cuda https share eof 运行速度 tar lte manage
原文地址:https://www.cnblogs.com/xiaoxiaoyibu/p/11402607.html