标签:nsf mat alt appear 很多 贝叶斯公式 存在 索引 tf-idf
本文提出一种用于大规模的长期回环检测,基于一种内存管理方法:限制用于回环检测的位置数目,以满足实时性要求。
大场景存在的最关键问题:随着场景增大,回环检测处理的数据量增大,可能会产生延时。该论文的研究重心在于设计一种在线的基于外观回环检测方法。为了限制搜索之前经过位置的时间,在贝叶斯框架下采用动态管理用于闭环检测的位置。Working Memory的大小取决于需要处理实时获得图片的时间,保留最近且最常观测到的位置,将其他的位置放入Long Term Memory。当找出当前位置和WM中某个位置的匹配 (即检测到了回环),则LTM中该与WM中该位置相邻的位置也将被唤醒。
词袋模型,讲特征量化为词典,量化方法:Vocabulary Tree、Approximate K-Means、K-D Tree,比较方法:TF-IDF
词典可以离线构建(导入数据集),也可实时构建(根据之前获取的图片)。
随着场景增大,词典规模增大,修剪或聚类方法可用于合并超过空间密度阈值的地图部分。
当地图中的位置数量使得查找匹配的处理时间大于时间阈值时,将WM中的位置移到LTM中,不进行闭环检测,然而当闭环检测到时,将闭环的相邻位置从LTM恢复到WM中,用于之后的闭环检测。
所有的位置都可以用一张图表示
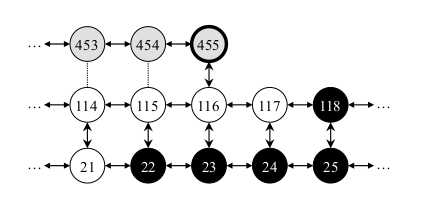
如图所示,当前获得的位置为455,垂直箭头为闭环检测连接,水平箭头为相邻位置连接,虚线为还未检测到的闭环,白色为WM中的位置,灰色为STM中的位置,黑色为LTM中的位置。
LTM中的位置不进行闭环检测,因为有很多相邻帧,如何选择哪些位置放到LTM中呢?
FIFO(先进先出)是一种简单的方法,但是不好,为什么不好?因此采用尽量保留被再次观测到的概率较大的位置,这些位置更可能会检测出回环。因此将每个位置能被连续观测到的次数作为权值,当必须将MW中的位置转移到LTM中时,选择权值最小的,如果不只一个,选择最早的位置。
如图所示为内存管理模型
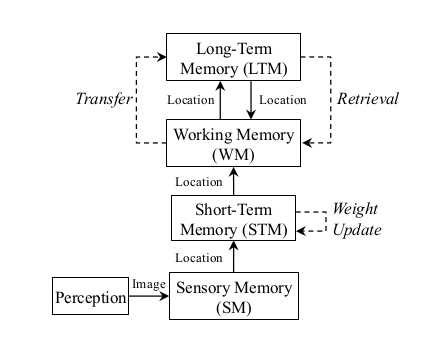
感知模块获取图像后将其发至WM,WM负责提取特征并将其送至STM,STM如果发现该图像和STM中的上一帧相似性较大,则将这两个位置进行融合成一个,并增大新位置的权值。而WM负责闭环检测,而STM中的帧不进行闭环检测,因为相邻帧相似度很高,STM的大小取决于机器人速度和图像获取速度。最终STM中最旧的位置则进入WM。
RTAB-Map使用离散贝叶斯滤波评估回环检测,通过检测最新的位置与WM中的位置。如果WM中最新的位置和旧的位置闭环概率较高则认为可能检测出回环。还需要关键的两步:Retrieval:将闭环检测出的位置的周围的位置从STM放入WM中,使得将来使用周围的位置进行闭环检测,确定闭环。Transfer:如果闭环检测处理时间超过$T_{time}$,则将权值最低的放入LTM。
A. Location Creation
本文使用递增式的词典而非预先训练好的词典。采用SURF算子构造视觉单词。词典中的每个视觉单词为64维的向量。为了避免特征不明显的图片用于回环检测(如一面白墙),只选用特征响应超过一定阈值的$\T_{response}$特征才被提取用于构建字典。
构建词典之后如何查找呢?SURF特征之间使用最近邻距离NNDR来比较其相关性,NNDR指距离特征最近的和第二近的邻居之间的距离之比。如果两个特征的$\T_{NNDR}$足够小,则认为可以使用同一个单词描述。由于SURF算子维度太高,使用FLANN进行查询,当新的特征与字典进行匹配时,可以提高最近邻查找的效率。kd-tree的叶子代表了每个单词。选择随机的kdtree是因为比分层的k-means建树时间短,FLANN不提供对其搜索索引进行增量更改的接口(例如随机化的kd-tree或分层的k-means树),因此需要在每次迭代时在线重新构建词汇表。kd-tree通过单词中的surf描述子建树。随后每个图像中的每个描述子在kd-tree中进行查找最近的两个邻居。当$\T_{NNDR}$大于阈值时,建立一个新的单词。

B. Weight Update
更新权值主要是将当前的位置$\L_t$与STM中的最后一个位置进行比较,使用相似度s评估
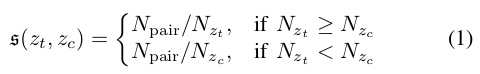
$N_{pair}$指这两个位置匹配的单词对,$N_{z_{t}}$和$N_{z_c}$分别指这两个位置时的单词总数,如果相似度大于一个阈值$T_{similarity}$,则将位置$L_c$合并至$L_t$,仅仅$L_c$中的词典被保留,而$L_t$中的新单词被移除。为什么移除$L_t$的词典呢因为它的描述子还没有在插入kd-tree?(不懂)合并后$L_t$的权重变为$L_t+L_c+1$。$L_c$的周围连接和回环连接都和设为和$L_t$连接。$L_c$从STM中删除。
C. Bayesian Filter Update
离散贝叶斯滤波通过估计当前位置$L_t$与WM中已经存在的一个位置匹配的概率来跟踪闭环假设。设$S_t$为一个随机变量,表示回环检测在时间t时的假设,$S_t=i$表示$L_t$和过去的位置$L_i$构成了回环,$S_t=-1$表示$L_t$是一个新的位置。滤波器估计后验概率p(S_{t}|L^t)$,对于所有$i=-1,...t_n},$t_n$指与WM中最新位置ed时间间隔,根据贝叶斯公式和马尔科夫假设:
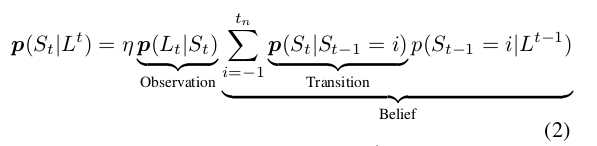
其中$L^t=L_{-1},...,L_t$。$L_t$仅仅包括WM和STM中的位置,因此$L^t$一直在改变。
其中,观测模型$p(L_t|S_t)$的计算方式如下:
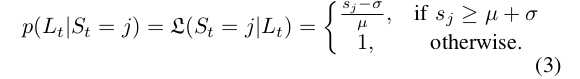
对于新的位置:
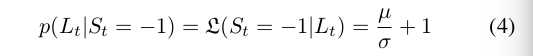
转换模型$p(S_t|S_{t-1}=i)$用于预测$S_t$的分布,
1)$p(S_t=-1|S_{t-1}=-1)=0.9$
2)$p(S_t=i|S_{t-1}=-1)=0.1/N_{WM},i\in[0:t_n]$
3)$p(S_t=-1|S_{t-1}=j)=0.1,j\in[0:t_n]$
4) $p(S_t=i|S_{t-1}=j)=0.1,j\in[0:t_n]$,该概率使用高斯概率曲线(\sigma=1.6)定义,该曲线中心为j,左右各取16个值:$i=j-16,...,j+16$。在图中,一个位置可能有多个邻居(如果存在回环检测),高斯值从i=j到最后一个邻居进行迭代(最多为16),其中$p(S_t>=0|S_{t-1}=j)$归一化和为0.9。
D. Loop Closure Hypothesis Selection
上一节计算出$p(S_t|L_t)$后,设最高的回环检测假设为$p(S_t=i)$时,取值为$p(S_t|l^t),如果假设t时刻的位置为新位置的概率$p(S_t=-1|L^t)$比回环阈值$T_{loop}$小,则认为该位置和i位置构成回环。将$L_t$和$L_i$相连,更新$L_t$位置的权值,$L_i$位置的权值设为0。此处不进行两个位置的合并,便于进行假设估计。
E. Retrieval
再检测到回环后,检测到的之前位置$L_i$不在WM中的相邻位置,将其从WM移动到LTM中。LTM使用SQLite3实现,如下所示:
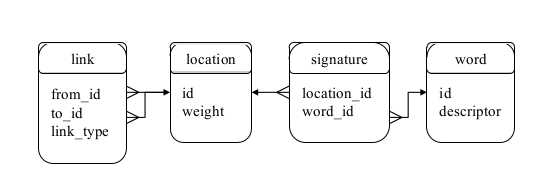
这里还要更新什么?
由于从数据库中取位置耗时长,每次最多Retrieval两个位置,时间优先于空间,前者相对于更加准确。

F. Transfer
当一幅图像的处理时间大于$T_time$ 时,WM中权重最低中最早的位置将被移动到LTM。其中最大回环检测估计位置的相邻位置不放到LTM中。$T_time$决定了WM的大小,由计算机处理能力以及环境地图决定。由于在kd-tree上进行搜索时耗时最长,因此通过改变词典规模来间接影响WM大小。下图表示如何动态改变词典规模:

NNDR有什么意义
Appearance-Based Loop Closure Detection for Online Large-Scale and Long-Term Operation
标签:nsf mat alt appear 很多 贝叶斯公式 存在 索引 tf-idf
原文地址:https://www.cnblogs.com/dlutjwh/p/11668581.html