标签:没有 inline class 插入 梯度下降法 min 应用 rac 复杂度
机器学习模型面临的两个主要问题是欠拟合与过拟合。欠拟合,即模型具有较高的偏差,说明模型没有从数据中学到什么,如下左图所示。而过拟合,即模型具有较高的方差,意味着模型的经验误差低而泛化误差高,对新数据的泛化能力差,如下右图所示。
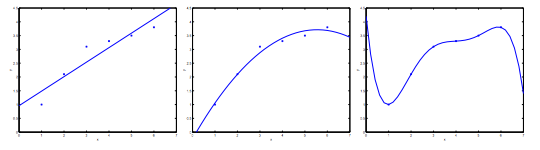
通常,欠拟合是由于模型过于简单或使用数据集的特征较少导致的。相反,过拟合则是模型过于复杂或特征过多引起的。欠拟合的问题比较容易解决,而过拟合的问题则有些棘手。一般而言,解决过拟合的方法包括降维和正则化。
正则化是通过向损失函数中添加惩罚项以限制参数大小的一种方法。假设我们有如下多项式线性回归模型:
\[
h_\theta(x)\theta_0 + \theta_1x+\theta_2x^2+\theta_3x^3+\theta_4x^4
\]
为了避免模型过于复杂,我们需要削弱\(\theta_3x^3\)和\(\theta_4x^4\)对模型的影响。因此,我们需要对这两项进行“惩罚”,避免它们过大。所以,我们把这两个参数乘以一个较大的系数,加到损失函数中:
\[
\min_{\theta} \frac{1}{2n}\sum_{i=1}^n\left(h_\theta(x^{(i)})-y^{(i)}\right) + 1000 \cdot \theta_3^2+ 1000 \cdot \theta_4^2
\]
这样一来,为了求解损失函数的最小值,式中\(\theta_3\)和\(\theta_4\)的值就不能过大,也就限制了模型的复杂度。如果要限制所有的参数,那么损失函数就是下面这种形式:
\[
\min_{\theta} \frac{1}{2n}\sum_{i=1}^n\left(h_\theta(x^{(i)})-y^{(i)}\right) + \lambda\sum_{j=1}^d\theta_j^2
\]
其中\(\lambda \gt 0\)是正则化参数。下面,我们将正则化应用到之前所学的线性回归和对数几率回归中。
损失函数:
\[
J(\theta) = \frac {1}{2n}\left[ \sum_{i=1}^n \left( h_\theta (x^{(i)}) - y^{(i)} \right)^2 + \lambda\sum_{j=1}^d\theta_j^2\right]
\]
今天懒得推导了(其实这个和不带正则化项的推导差不多),直接写更新方程吧:
\[
\begin{aligned} & \text{Repeat}\ \lbrace \\ & \ \ \ \ \theta_0 := \theta_0 - \alpha\ \frac{1}{n}\ \sum_{i=1}^n (h_\theta(x^{(i)}) - y^{(i)})x_0^{(i)} \\ & \ \ \ \ \theta_j := \theta_j - \alpha\ \left[ \left( \frac{1}{n}\ \sum_{i=1}^n (h_\theta(x^{(i)}) - y^{(i)})x_j^{(i)} \right) + \frac{\lambda}{n}\theta_j \right] &\ \ \ \ \ \ \ \ \ \ j \in \lbrace 1,2...d\rbrace\\ & \rbrace \end{aligned}
\]
\[
\begin{aligned}
& \theta = \left( X^TX + \lambda \cdot L \right)^{-1} X^Ty \text{, where}\ \ L = \begin{bmatrix} 0 & & & & \\ & 1 & & & \\ & & 1 & & \\ & & & \ddots & \\ & & & & 1 \\ \end{bmatrix}_{(d+1)\times(d+1)}
\end{aligned}
\]
\(X^TX + \lambda \cdot L\)这个东西必定可逆。
首先,因为\(\vec{u}^TA^TA\vec{u}=\|A\vec{u}\|^2 \ge0\),所以\(A^TA\)是半正定矩阵,即\(A^TA\)的所有特征值\(\mu_i\ge 0\)。由\(A^TA\vec{u}=\mu_i \vec{u}\)可以推出\((A^TA+\lambda I)\vec{u}=(\mu_i+\lambda)\vec{u}\),因此\(A^TA+\lambda I\)的特征值为\(\mu_i+\lambda\)。又因为\(\lambda \gt 0\),所以\(\mu_i+\lambda\gt0\)。由于\(A^TA+\lambda I\)的所有特征值都是大于\(0\)的,因此矩阵\(A^TA+\lambda I\)一定可逆。
损失函数:
\[
J(\theta) = -\frac{1}{n} \sum _{i=1}^n \left[ y^{(i)} \log h_\theta(x^{(i)}) + (1-y^{(i)})\log(1 - h_\theta(x^{(i)})) +\frac{\lambda}{2}\sum_{j=1}^d\theta_j^2\right ]
\]
更新方程与线性回归类似,这里就不写了。
标签:没有 inline class 插入 梯度下降法 min 应用 rac 复杂度
原文地址:https://www.cnblogs.com/littleorange/p/12231342.html