标签:training ble orm oba 区分 learn 基于 看不见 variable
1. Gradient Descent包含两种方法
a) Batch Gradient Descent
![]()
replace the gradient with the sum of gradient for all sample and continue untill convergence
convergence的意思是??稳定下来
b) Stochastic Gradient Descen
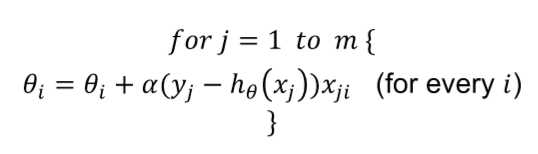
repeat this algorithm until convergence
区别在于第一个对所有项进行计算直至convergence;第二个??在任何样本中均会更新,计算量减少但是有可能找不到minimum
相同处在于可以为参数??i随意选取初始值,但是learning rate ??的选取要非常小心,因为较小的值会使算法过慢,较大的值会使算法无法收敛(??介于0,1之间)
2. gradient descent是一种迭代算法,可用来使成本函数J(??)最小化。也可以通过对(??)求导并将其设置为0从而找到其最小值,这种方法称为exact or closed-form solution
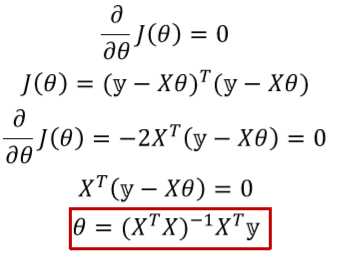

注意一定要在第一列加上一列1,称之为intercept parameter(拦截参数)
3. 将input variable x与output variable y的关系表示为:![]()
其中??j是一个误差项,可能是由于未建模或随机噪音造成的,假设??js是独立的,且根据高斯分布(Gaussian distribution)具有相同的分布(i.i.d.), 如下图所示,p(??j)表示错误发生的概率
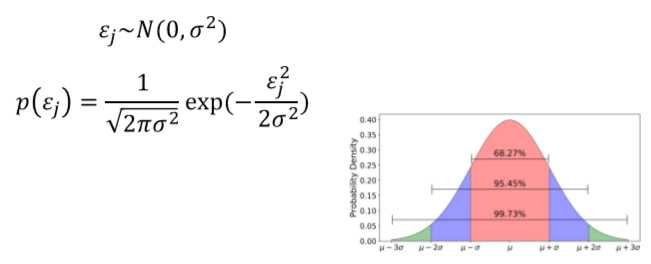
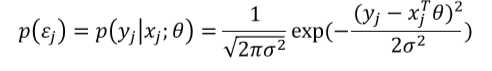
因此我们要估算??以简化,在m个训练样本中最大化在给定input x的情况下得到output y的可能性
![]() 称作likelihood function
称作likelihood function
由于我们假设??具有独立性,故而我们的training samples也是彼此独立的;基于此假设我们可以进一步改写
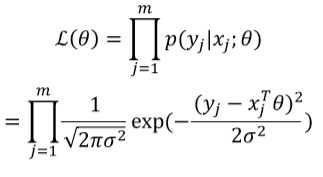
现在我们需要得到使?(??)最大化的??,这被称为maximum likelihood
为找到使?(??)最大的??,我们可以转而计算log?(??)
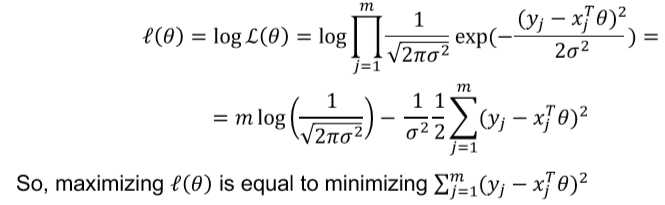
4. linear regression assumptions
linearity: x与the mean of y之间的关系是线性的
homoscedasticity: 残差的方差对于任何值x都是相同的
independence: 观察彼此独立
normality: 对任意固定值x,y呈正态分布(normally distributed)
5. probability与statistics区别
probability: based on whole population,对整体进行分析从而得到个体的可能性(deductive reasoning演绎推理)
statistics:based on samples to predict the whole population(inductive reasoning归纳推理)
6. sampling时需要没有无法计算的误差,同一类型的样本不需要重复选择
7. estimation估算
estimation是指根据从样本中获得的信息推断总体的过程
好的估值:样本的均值等于总体的均值
8. mean即平均值,如果我们可以求得每个数据出现的次数,我们可以将每个数据与其出现频率相乘以简便运算
9. variance即方差,衡量一组随机数与平均值之间的差值

10. covariance and correlation协方差和相关性

11. correlation介于1与-1之间,表示变量x与y之间是否存在关联;仅当x与y大致呈线性关联时,相关才适用。如出现下图中间所示的情况,视为undefined
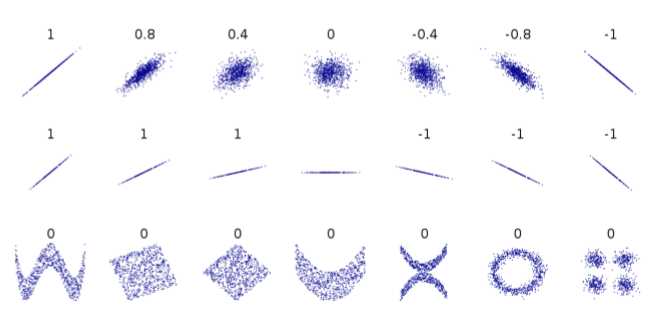
注意correlation仅仅表示相关性,不能说x导致y
12. univariate linear regression单变量线性回归(仅有一个变量)

??1:y的变化伴随着x的变化,若x被设置成随机数,??1可以估算出随着x的改变y的变化;若x不是随机数,则y的变化将包括x的变化以及由于将x改变1个单位而可能发生的任何其他混淆变量
??1=0意味着x y之间没有linear relationship
已知将常量添加到所有x值将仅影响截距,而不影响回归系数;因此我们可以通过减去x使x值位于0,此时截距等于y;或者我们可以从所有y值中减去y使得截距为0(intercept)
13. multiple regression中使用矩阵表示可以更好地表示回归方程的表达式
14. linear regression也可以表示curve shapes

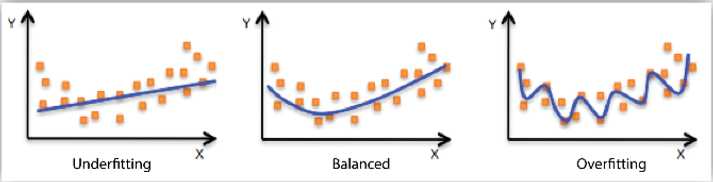
15. regularisation: 正则化是通过对权重向量施加附加约束来避免过度拟合(overfitting)的通用方法;常用方法是确保权重的平均值较小,这被称作shrinkage
结合前文cost minimization中的regression,可以将penalty加入到cost function中,迫使系数缩小到0



16. train data: 用于学习model及其参数的数据,as mush as possible
validation data: 用于调整模型参数时对train data上的模型拟合进行无偏差评估的数据
test data: 用来测试模型的模型,展示模型的generalizes,该模型的标签未知
17. 理性情况下,我们希望在test set上得到与validation set相同的性能,这称作generalization;generalization是指模型适应新的、从前看不见的数据的能力,这些新数据是从用于创建模型的分布相同的分配中提取的
18. 
19. RMSE的绝对值并不能说明模型有多糟糕,它只能用于两个模型之间的比较;adjusted R-squared可以用来说明模型的质量,但是如果只关心预测准确性的话,RMSE是最好的,更易于区分
20. local regression: use kNN to form a local approximation to f for each query point Xq using a linear function of the form

distance function:

标签:training ble orm oba 区分 learn 基于 看不见 variable
原文地址:https://www.cnblogs.com/eleni/p/12341310.html