标签:x64 encoding class append gen strip div word alt
1.打开网站:http://top.baidu.com/buzz?b=341&c=513&fr=topbuzz_b42
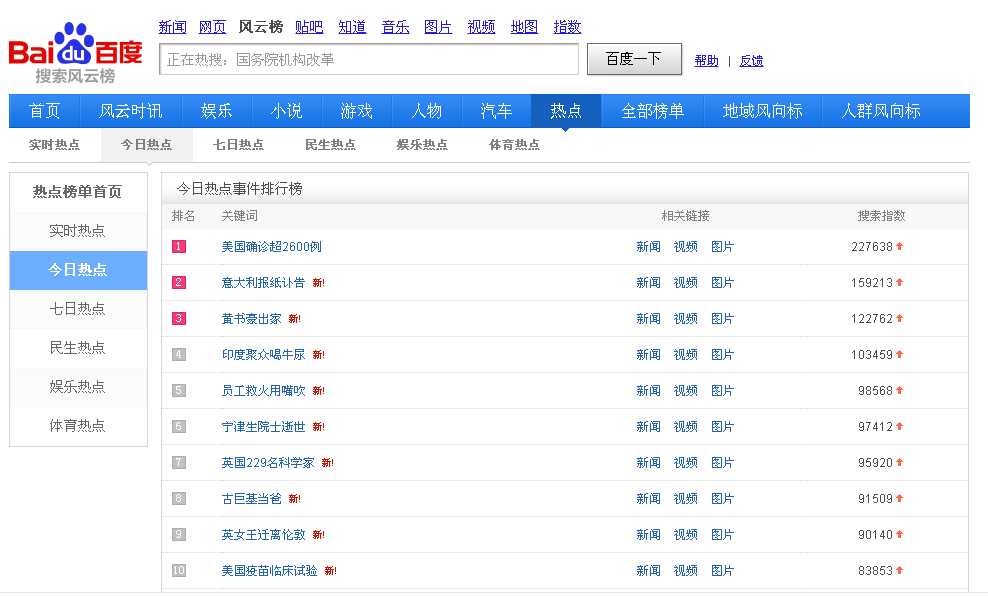
2.按Ctrl+u查看网页源代码
3.招到要爬取的数据

4.
import requests from bs4 import BeautifulSoup import pandas as pd url = ‘http://top.baidu.com/buzz?b=341&c=513&fr=topbuzz_b341_c513‘ headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/69.0.3497.100 Safari/537.36‘} #伪装爬虫 r=requests.get(url)#请求网站 r.encoding=r.apparent_encoding html=r.text#获取源代码 soup=BeautifulSoup(x,‘lxml‘)#构造Soup的对象 a=[] b=[] for m in soup.find_all(class_="keyword"): a.append(m.get_text().strip()) for n in soup.find_all(class_="list"): b.append(n.get_text().strip()) h=pd.DataFrame(data,index=["关键词","热度"]) print("爬取百度热搜榜前十:","\n") print(data.iloc[0:10])
5.爬取的数据为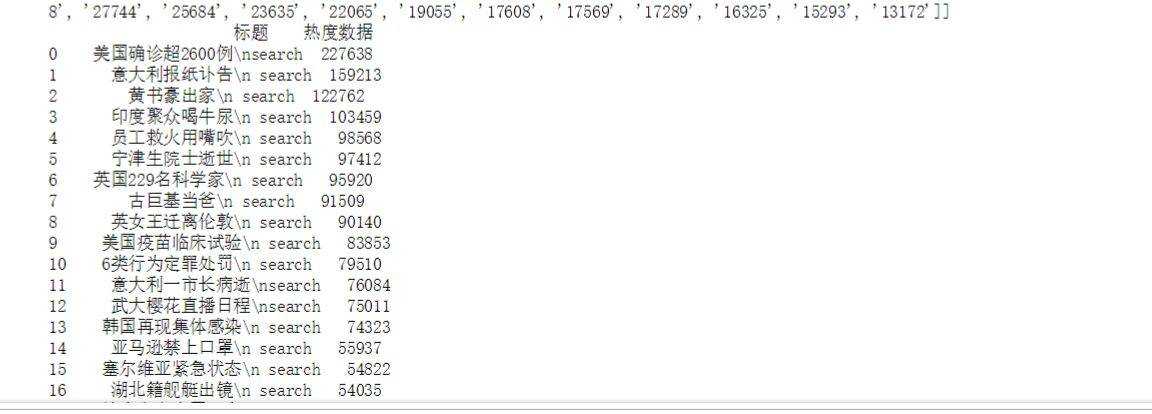
标签:x64 encoding class append gen strip div word alt
原文地址:https://www.cnblogs.com/huangguowei/p/12521081.html