标签:seo amp body title char port 打码平台 query 简单的
自上一篇 Node 爬虫心得来,有爬虫自然也会有反爬虫,爬虫这事就如道高一尺魔高一丈。
常用的有几种手段
Referer 最常用于防盗链,但若有需要,也可以去 Nginx 配置只允许自身网站的域名访问。
User-Agent 这个就常用了,像是搜索引擎的机器人常常是带着 spider、robot 等说明,而一些拙劣的爬虫脚本,连这个也不带。比方说去请求妹子图网,会直接被 403 拒绝就是这种防御
$ curl https://www.mzitu.com/230184
<html>
<head><title>403 Forbidden</title></head>
<body>
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx</center>
</body>
</html>
这时候加上 UA 就搞定了
$ curl --location --request GET ‘https://www.mzitu.com/230184‘ > --header ‘User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36‘
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title>性感妹子 - 妹子图</title>
<meta name="keywords" content="" />
<meta name="description" content="妹子图每日分享最新最全的高清性感美女图片" />
<script type="text/javascript" src="https://ip.ws.126.net/ipquery?"></script>
<script type="text/javascript" src="https://www.mzitu.com/static/mb/u.js?0211"></script>
<link rel="canonical" href="https://www.mzitu.com/230184" />
<link rel="alternate" media="only screen and(max-width: 640px)" href="https://m.mzitu.com/230184" >
<meta name="mobile-agent" content="format=html5;url=https://m.mzitu.com/230184" />
<meta name="applicable-device" content="pc">
......
请求头的防御手段,反爬虫手段肯定得加上,然太容易被绕过,篡改请求头成本太低。
这个比较难操控,本人以前用一台机器爬取时,就遭到过被封 IP 的问题。
防御方可以对 IP 的请求资源限速,判定在若干时间内流量超过某个阈值就拦截此 IP 的请求一段时间,若此有关联的用户账号的话,也可以对账号进行封禁。
对 IP 处理,如果阈值调低点,可能会误伤到用户,因为总有许多用户用的一个网络。并且对于攻击者,想绕过出现了一些成本,但做起来却也没那么难,可以使用代理 IP 池,用多个 IP 去抓取。
大多数的爬虫请求它都只是抓去 HTML 并解析获取想要的资源,极少数会去执行目标网站的 JS 脚本。基于这点,就有一些防御策略可以做,这些策略都可以被归为 JS 来渲染页面,让攻击者拿到的 HTML 并非真正的用户能看到的内容。
比如目前最常见的是单页应用,举个例子,除了拿到一堆脚本,其他啥也拿不到。
$ curl https://zhiyun.souche.com/welcome
<!DOCTYPE html><html><head><meta charset=utf-8><link href=/public/favicon.ico rel=mask-icon color=#ff571a></head><body><div id=root></div><div style=display:none><a href=https://www.dasouche.com/zh/ rel=nofollow>大搜车</a> <a href=https://www.souche.com/index>大搜车家选</a> <a href=https://www.chehang168.com/ rel=nofollow>车行168</a> <a href=https://www.tangeche.com/ rel=nofollow>弹个车</a> <a href=https://www.24che.com/ >24车汽车资讯</a> <a href=https://www.cheyipai.com/ rel=nofollow>车易拍</a></div><script>(function () {
var src = "https://jspassport.ssl.qhimg.com/11.0.1.js?d182b3f28525f2db83acfaaf6e696dba";
document.write(‘<script src="‘ + src + ‘" id="sozz"><\/script>‘);
})();
var _hmt = _hmt || [];
(function () {
var hm = document.createElement("script");
hm.src = "https://hm.baidu.com/hm.js?4f39064ba41b08e411d9c9f60a3303ea";
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();</script><script>(function () {
var bp = document.createElement(‘script‘);
var curProtocol = window.location.protocol.split(‘:‘)[0];
if (curProtocol === ‘https‘) {
bp.src = ‘https://zz.bdstatic.com/linksubmit/push.js'‘;
}
else {
bp.src = ‘http://push.zhanzhang.baidu.com/push.js'‘;
}
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();</script><script src=https://assets.souche.com/projects/bdc_group/disp-fe-wf/js/chunk-vendors.69b2172d.js></script><script src=https://assets.souche.com/projects/bdc_group/disp-fe-wf/js/app.75e4cd5b.js></script></body></html>
插嘴说一句,单页应用天然带这个问题,这也导致 SEO 困难的麻烦,不过这个处理起来简单。可以抽离一个服务出来,专门处理 user-agent 为 spider 或者 robot 的搜索引擎机器人,给他们看另外一个静态的页面就好了,当然你可以做一些处理屏蔽掉数字之类的可能敏感的数据再输出。
还有一个典型解法是使用 font 做字体反爬,把 123 和一二三之类的常用字符放入自定义的字体库中,爬虫收集到的是“猎豹以时速?公里/小时的速度奔跑在非洲的大草原上”,关键的那个时速因为用的是自定义字体,而使得爬虫爬页面是无法直接得出结果的。
对此有一篇文章讲的不错 反爬终极方案总结—字体反爬,下图出自这篇文章。
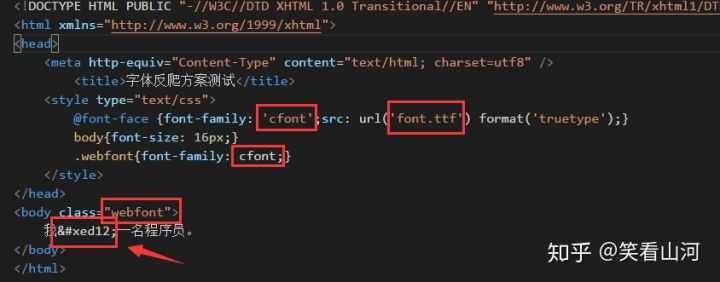
当然还有故意喂爬虫方假数据的做法,笔者就遇到过,爬下来的 HTML 解析得某商品价格为 1234 元,然而真的用浏览器访问这个页面得到的商品价格数据明明是 5678 元。这其实是 HTML 里写着 1234,但 JS 里有着某个变量,执行后会计算重写那个价格。
这一层也是花样最多的地方,但谷歌出的无头浏览器是个大杀器,参照下Headless Chrome
超频的访问可以弹出验证码输入,要求输入,若来者没有输入那自然就会被判定成机器人了。
通常验证码是一张图片,文本自然抓不出是什么,这一度难倒了大多数的攻击方,直到 OCR 的出现,JS 已经有许多开源的库了,就如 tesseract,只要调用一次 API,就能破解简单的验证码。
围绕验证码的攻防也是一个巨大的话题。防御方发觉验证码轻松被破,那么就要上难度更高的验证码,可以是更扭曲变形的文字,加入干扰线,混淆背景和文字的图片。越来越难的验证码,机器人自然很难识别,但是人类也是不堪其苦,笔者见到过最变态的验证码是 NGA 论坛的登陆验证码。


NGA 似乎调整过了,原先的更加变态。它让笔者每次都得定睛看个好几秒才能认出,而且还经常可能输错。可能会换成滑动的验证码,但其实滑动验证码破解起来并没有复杂的图形验证码困难。
攻击方发觉单单的 OCR 已经无法拿取到图片内容了,新的玩法就产生了,上机器学习+OCR的模式了,或者打码平台,但这里不多说。
不计成本的说,防方最后还是搞不过攻方。虽然如此,我们也可以极力提升攻击方的成本,拦住那些低级的爬虫脚本。
标签:seo amp body title char port 打码平台 query 简单的
原文地址:https://www.cnblogs.com/everlose/p/12837836.html