标签:有一个 核心 att hashmap node 结束 class hash llb
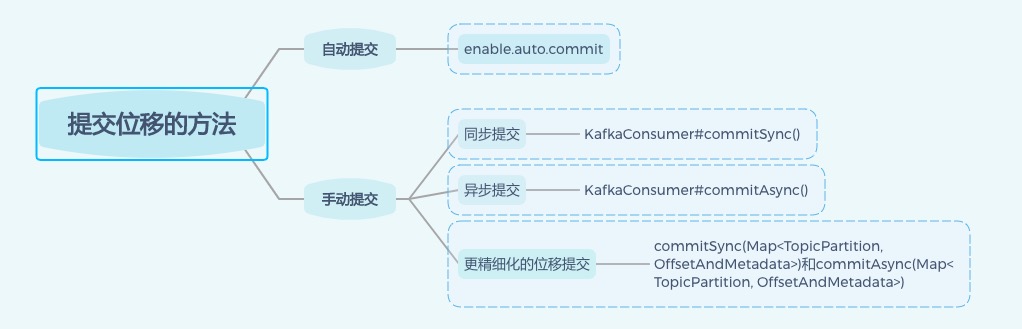
Kafka核心技术与实战——18 | Kafka中位移提交那些事儿
原文地址:https://www.cnblogs.com/minimalist/p/12931121.html