标签:百度翻译 还原 pos ann str 如何 世界 class tps
import csv import nltk import re from nltk.corpus import stopwords from nltk.stem import WordNetLemmatizer import pandas as pd #返回类别 def getLb(data): if data.startswith("J"): return nltk.corpus.wordnet.ADJ elif data.startswith("V"): return nltk.corpus.wordnet.VERB elif data.startswith("N"): return nltk.corpus.wordnet.NOUN elif data.startswith("R"): return nltk.corpus.wordnet.ADV else: return ""; def preprocessing(data): newdata=[] punctuation = ‘!,;:?"\‘‘ data=re.sub(r‘[{}]+‘.format(punctuation), ‘‘, data).strip().lower();#去标点和转小写 for i in nltk.sent_tokenize(data, "english"): # 对文本按照句子进行分割 for j in nltk.word_tokenize(i): # 对句子进行分词 newdata.append(j) stops = stopwords.words(‘english‘) newdata= [i for i in newdata if i not in stops]#去停用词 newdata = nltk.pos_tag(newdata)#词性标注 lem = WordNetLemmatizer() for i, j in enumerate(newdata):#还原词 y = getLb(j[1]) if y: newdata[i] = lem.lemmatize(j[0], y) else: newdata[i] = j[0] return newdata if __name__ == "__main__": file_path = r‘C:\Users\ASUS\Desktop\机器学习\贝叶斯垃圾邮件分类\SMSSpamCollection‘ sms = open(file_path, ‘r‘, encoding=‘utf-8‘) sms_data = [] sms_label = [] csv_reader = csv.reader(sms, delimiter=‘\t‘) for line in csv_reader: sms_label.append(line[0]) sms_data.append(preprocessing(line[1])) sms.close() result=pd.DataFrame({"类别":sms_label,"特征":sms_data}) result.to_csv("./data/result.csv")

from sklearn.model_selection import train_test_split
x_train,x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=0, stratify=y_train)
from sklearn.model_selection import train_test_split import pandas as pd import numpy as np data=pd.read_csv("./data/result.csv") x_train,x_test, y_train, y_test = train_test_split(data.iloc[:,2], data.iloc[:,1], test_size=0.2, random_state=0)
sklearn.feature_extraction.text.CountVectorizer
sklearn.feature_extraction.text.TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf2 = TfidfVectorizer()
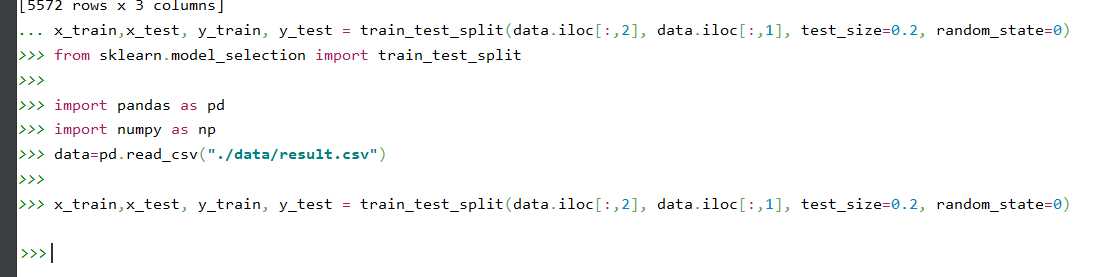
观察邮件与向量的关系
向量还原为邮件
#特征提取 from sklearn.feature_extraction.text import TfidfVectorizer tfidf2 = TfidfVectorizer() X_train=tfidf2.fit_transform(x_train.values.astype(‘U‘)) X_text=tfidf2.transform(x_test.values.astype(‘U‘)) #向量还原成邮件 X_train X_train.toarray() X_train.toarray().shape tfidf2.fit_transform(x_test).toarray().shape tfidf2.vocabulary_#(单词,位置) a=np.flatnonzero(X_train.toarray()[0]) a X_train.toarray()[0][a] b=tfidf2.vocabulary_ key_list=[] for key,value in b.items(): if value in a: key_list.append(key) key_list x_train.iloc[0]
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
说明为什么选择这个模型?
根据特征特点来选。
GaussianNB:高斯贝叶斯(适用于特征正态分布)
MultinomialNB:离散型朴素贝叶斯(适用于特征离散分布)√
from sklearn.naive_bayes import MultinomialNB mnb=MultinomialNB() mnb.fit(X_train,y_train) y_mnb=mnb.predict(X_text)
from sklearn.metrics import confusion_matrix
confusion_matrix = confusion_matrix(y_test, y_predict)
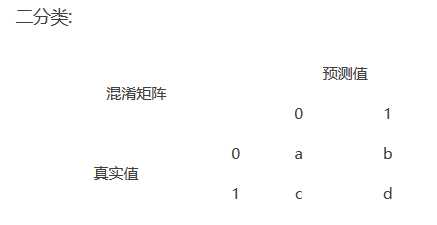
TP(True Positive):将正类预测为正类数,真实为0,预测也为0
FN(False Negative):将正类预测为负类数,真实为0,预测为1
FP(False Positive):将负类预测为正类数, 真实为1,预测为0
TN(True Negative):将负类预测为负类数,真实为1,预测也为1
说明混淆矩阵的含义:
混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总。其中矩阵的行表示真实值,矩阵的列表示预测值。
矩阵的表现形式:
from sklearn.metrics import classification_report
说明准确率、精确率、召回率、F值分别代表的意义
分类准确率Accuracy:
所有样本中被预测正确的样本的比率
分类模型总体判断的准确率 (包括了所有 class 的总体准确率)
(Accuracy = (TP +TN)/(TP + FP + TN + FN)): 在所有样本中,预测为真的比例
精确率Precision:
(Precision = TP /(TP + FP)):预测结果为正例样本中真实为正例的比例(查得准)
召回率Recall:
(Recall = TP /(TP + FN)):真实为正例的样本中预测结果为正例的比例(查得全,对正样本的区分能力)
F值 = 正确率 * 召回率 * 2 / (正确率 + 召回率) (F 值即为正确率和召回率的调和平均值)
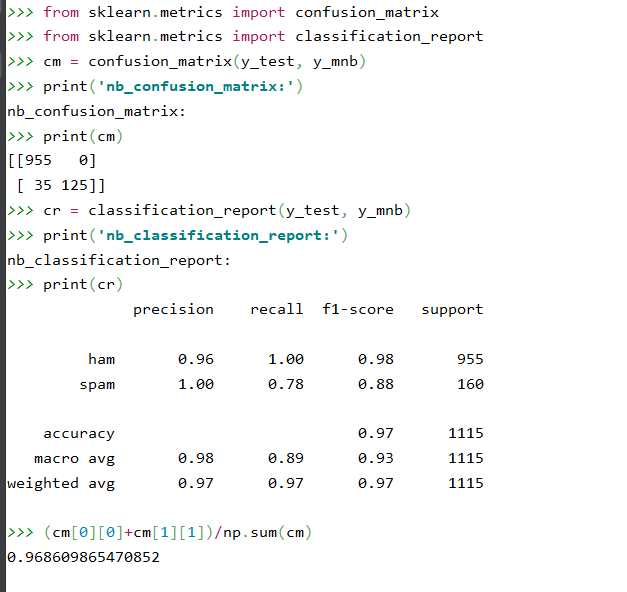
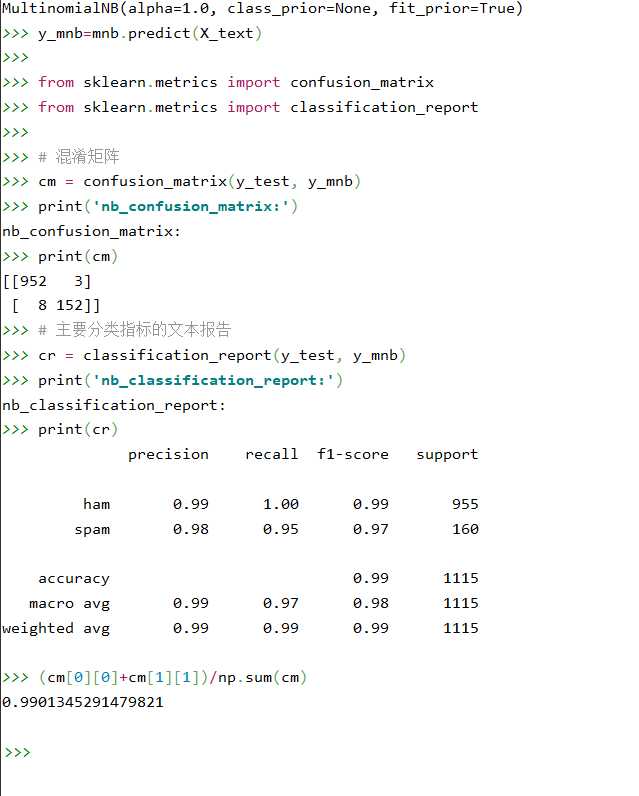
from sklearn.metrics import confusion_matrix from sklearn.metrics import classification_report # 混淆矩阵 cm = confusion_matrix(y_test, y_mnb) print(‘nb_confusion_matrix:‘) print(cm) # 主要分类指标的文本报告 cr = classification_report(y_test, y_mnb) print(‘nb_classification_report:‘) print(cr) (cm[0][0]+cm[1][1])/np.sum(cm)
如果用CountVectorizer进行文本特征生成,与TfidfVectorizer相比,效果如何?
#CountVectirizer from sklearn.feature_extraction.text import CountVectorizer tfidf2 = CountVectorizer() X_train=tfidf2.fit_transform(x_train.values.astype(‘U‘)) X_text=tfidf2.transform(x_test.values.astype(‘U‘)) #向量还原成邮件 X_train X_train.toarray() X_train.toarray().shape tfidf2.fit_transform(x_test).toarray().shape tfidf2.vocabulary_#(单词,位置) a=np.flatnonzero(X_train.toarray()[0]) a X_train.toarray()[0][a] b=tfidf2.vocabulary_ key_list=[] for key,value in b.items(): if value in a: key_list.append(key) key_list x_train.iloc[0] from sklearn.naive_bayes import MultinomialNB mnb=MultinomialNB() mnb.fit(X_train,y_train) y_mnb=mnb.predict(X_text) from sklearn.metrics import confusion_matrix from sklearn.metrics import classification_report # 混淆矩阵 cm = confusion_matrix(y_test, y_mnb) print(‘nb_confusion_matrix:‘) print(cm) # 主要分类指标的文本报告 cr = classification_report(y_test, y_mnb) print(‘nb_classification_report:‘) print(cr) (cm[0][0]+cm[1][1])/np.sum(cm)
TfidfVectorizer除了统计在本文的单词出现频率之外,还关注包含这个词汇的所有文本的数量,能够削减高频没有意义的词汇出现带来的影响, 挖掘更有意义的特征;
而CountVectorizer只考虑单词在本文中出现的频率。相较于CountVectorizer,TfidfVectorizer所选取的特征更有意义。
翻译 朗读 复制 正在查询,请稍候…… 重试 朗读 复制 复制 朗读 复制 via 谷歌翻译(国内) 译
标签:百度翻译 还原 pos ann str 如何 世界 class tps
原文地址:https://www.cnblogs.com/moxiaomo/p/12943852.html