标签:ble while different let rev only choice input 模型
2018-ICML-Understanding and Simplifying One-Shot Architecture Search
One promising direction is sharing weights between models: rather than training thousands of separate models from scratch, one can train a single large network capable of emulating any architecture in the search space.
权重共享是一个有潜力的方向,因为不必从头训练许多网络,只需要训练一个大网络,就可以从中抽样出不同的网络结构(进行评估)。
A simple example is shown in Figure 1, where we have the option of applying either a 3x3 convolution, a 5x5 convolution, or a max-pooling layer at a particular position in the network.
Instead of training three separate models, we can train a single model containing all three operations (the one-shot model).
如果图1所示的一个网络block,训练时3个操作都启用,但评估(抽样)时,只启用其中一个。
这样就不用训练3个不同的模型,只需要训练一个包含3个操作的模型。训练时会给3个不同的操作都学习各自的权重。
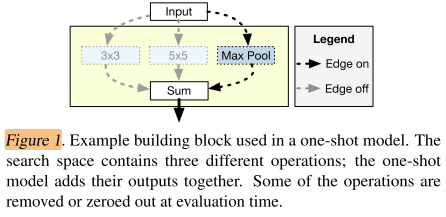
The size of the search space grows exponentially with the number of choices, while the size of the one-shot model grows only linearly.
当搜索空间增加时,传统的子网络数量会指数增加,而one-shot model只会线性增加。
The same weights are used to evaluate many different architectures, reducing the resources required to run an architecture search by orders of magnitude.
(训练完大模型以后)从大模型中抽取不同的子模型进行评估时,如果不同的子网络中有重叠的部分,这些重叠部分的操作权重是共享的。
One-shot models are typically only used to rank architectures in the search space; the best-performing architectures are retrained from scratch after the search is completed.
当评估完多个结构以后,选取在评估阶段表现最好的子模型,train from scratch
previous works remain complex, requiring hypernetworks or reinforcement learning controllers.
之前的工作使用复杂的超网,强化学习等。
With careful experimental analysis, we show that it is possible to efficiently identify promising architectures from a complex search space without either hypernetworks or RL.
提出无需超网或强化学习,就可以从
The proposed approach for one-shot architecture search consists of four steps:
(1) Design a search space that allows us to represent a wide variety of architectures using a single one-shot model.
(2) Train the one-shot model to make it predictive of the validation accuracies of the architectures.
(3) Evaluate candidate architectures on the validation set using the pre-trained one shot model.
(4) Re-train the most promising architectures from scratch and evaluate their performance on the test set.
one-shot 结构搜索包含4个步骤:
1)搜索空间足够大,可以用一个one-shot 大网络(抽样)出足够多的结构
2)训练one-shot网络,使得one-shot 网络可以预测子网络的性能。
3)在验证集上用训练好的one-shot 大网络抽样出不同的候选子网络,评估子网络的性能。
4)re-train 最有潜力的网络,并在测试集上得到子网络的性能
1)the search space should be large and expressive enough to capture a diverse set of interesting candidate architectures.
2)the validation set accuracies produced by the one-shot model must be predictive of the accuracies produced by stand-alone model training.
3)the one-shot model must be small enough to train using limited compute resources (i.e., memory and time)
one-shot search space需要满足以下条件:
1)search space需要足够large和expressive,这样才能探索更丰富多样的候选网络架构
2)one-shot模型在验证集上的准确率必须与stand-alone模型的准确率高度相关。也就是说相比于其他候选模型,A模型在验证集上准确率高,那么对A模型retrain的之后,它在测试集上的准确率也要是最高,或者是靠前的。
3)在资源有限的情况下,one-shot模型不能太大
This approach is applied to a much larger model as shown in Figure 3. Each cell is divided into a fixed number of choice blocks.
The inputs to a given choice block come from (1) outputs of previous cells, and (2) outputs of previous choice blocks within the same cell.
The number of choice blocks within each cell, Nchoice, is a hyper-parameter of the search space. In our experiments, we set Nchoice =4.
Each choice block can consume the outputs of the two most recent cells in the network. This means that each choice block can select from up to five possible inputs: two from previous cells and up to three from previous choice blocks within the same cell.
Each choice block can select up to two operations from a menu of seven possible options: (1) identity,
(2) a pair of depthwise separable 3x3 convolutions,
(3) a pair of depthwise separable 5x5 convolutions,
(4) a pair of depthwise separable 7x7 convolutions,
(5) a 1x7 convolution followed by a 7x1 convolution,
(6) a max pooling layer, and
(7) an average pooling layer.
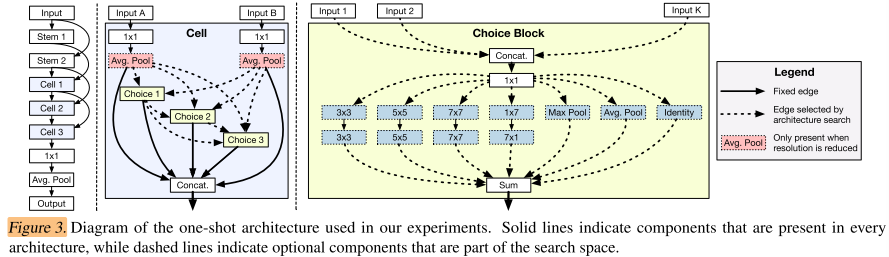
搜索空间如图3,每个cell中包含固定数量的choice blcok。
每个choice block的input来自 1)之前的2个的cell的output,2)同一个cell中之前的choice block的output
每个cell中的choice block数量是超参,这里取4
每个choice block至少有2个input(之前2个cell的output),至多5个input(之前2个cell的output+当前cell之前3个choice block的output)
每个choice block至多从以下7中操作中,选择2个操作:
(1) identity,
(2) a pair of depthwise separable 3x3 convolutions,
(3) a pair of depthwise separable 5x5 convolutions,
(4) a pair of depthwise separable 7x7 convolutions,
(5) a 1x7 convolution followed by a 7x1 convolution,
(6) a max pooling layer, and
(7) an average pooling layer.
- 互相适应的鲁棒性(Robustness of co-adaptation):如果只是简单地直接训练整个one-shot模型,那么模型内各部分是高度耦合的,即使移除一些不重要的部分,也可能使得模型预测准确率大打折扣。所以文章引入path dropout策略来提高训练稳定性。具体做法就是最开始啥都不drop,而后每个batch都随机drop,而且drop的概率也线性增加。drop的概率计算公式为\(r^{1/k}\),r是一个超参数,k表示操作数量。
- 训练模型的稳定性(Stabilizing Model Training):
- 虽然Relu-BN-Conv效果也差不多,实验使用更常用的BN-Relu-Conv顺序。另外我们知道在评估阶段我们会从one-shot模型里选择一个子模型来评估,也就是说我们会剔除一些操作,但是模型里的BN操作的统计量只是基于one-shot模型计算得到的,所以在评估阶段BN的统计量每个batch都要重新计算。
- 另外在训练one-shot模型的时候,对于一个batch里的数据,我们dropout的操作都是一样的。换句话说这批数据都是在同一个子模型下训练的。文章称这种方式也会导致训练不稳定,所以他们将一个大小为1024的batch数据进一步划分成多个子batch,称作ghost batch。比如1024批数据可以划分成32个大小为32的ghost batch,然后每个ghost batch应用不同的path dropout操作(即对应不同的子模型)。
- 避免过度正则化:在训练模型时,我们经常会用L2正则化。但是在这里只是对选择的子模型做正则化。不然一些没有被选择过的操作也被正则化的话就过分了啊~~
下面只介绍一个比较有意思的实验结果,即 Dropout rate对结果的影响:
结果如下图示:
- 设置的概率值太小的话(最左),可以看到one-shot模型的整体准确率都不高,但是retrain之后的stand-alone模型性能好像都还可以。但是这样one-shot的准确率并不能很好的反映最后模型的性能。
- 设置的概率值太高的话(最右),虽然one-shot模型的准确率提高了,但是可以看到准确率的范围分布在了0.6~0.8之间,也就是说概率值过大使得模型可能把更多机会给到了一些表现可能
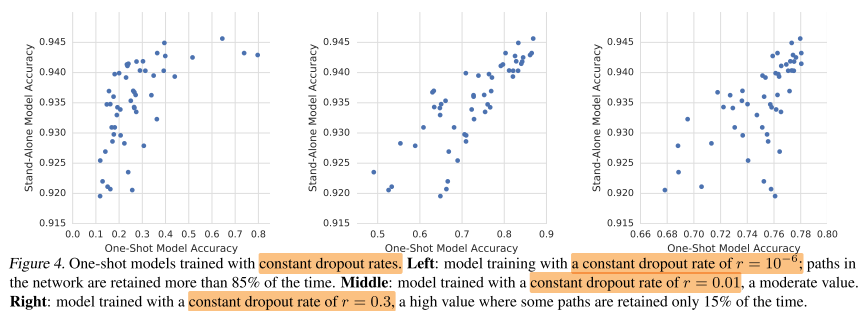
由上图我们可以看到(以最左图为例),one-shot模型的准确率从0.1~0.8, 而stand-alone(即retrain之后的子模型)的准确率范围却只是0.92~0.945。为什么one-shot模型之间的准确率差别会更大呢?
文章对此给出了一个猜想:one-shot模型会学习哪一个操作对模型更加有用,而且最终的准确率也是依赖于这些操作的。换句话说:
- 在移除一些不太重要的操作时,可能会使one-shot模型准确率有所降低,但是最后对stand-alone模型性能的预测影响不大。
- 而如果把一些最重要的操作移除之后,不仅对one-shot模型影响很大,对最后的stand-alone模型性能影响不大。
我理解是这个意思
状态 one-shot 模型准确率 stand-alone模型准确率 移除操作之前 80% 92% 移除不太重要的操作 78% 91% 移除重要的操作 56% 90% 为了验证这一猜想,文章做了如下实验:
首先将几乎保留了所有操作的(dropout概率是\(r=10^{?8}\))模型叫做reference architectures,注意这里用的是复数,也就是说这个reference architectures有很多种,即有的是移除了不太重要的操作后的结构,有的时移除了非常重要的操作候的结构,那么不同结构的准确率应该是不一样的。不过在没有retrain的情况下,什么操作都没有移除的one-shot模型(All on)应该是最好的(或者是表现靠前的,这里我们认为是最好的)。
注意这里的移除某些操作后得到的模型还是One-shot模型,而不是采样后的模型。采样后的模型是指从这个完整的one-shot中按照某种策略得到的模型。文中把这种模型叫做candidate architectures。
我们以分类任务为例,假设reference architectures对某个样本的预测输出是(p1,p2,...,pn),其中n表示类别数量;而candidate architectures的输出为(q1,q2,...,qn)。注意candidate architecture的输出应该是没有retrain的结果。
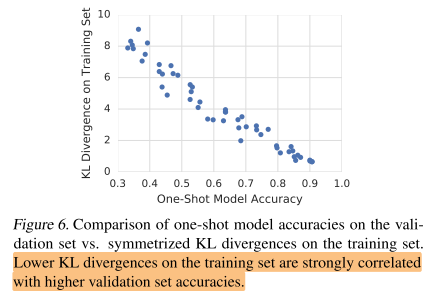
所以如果上面的猜想是正确的,那么表现最好的candidate architecture的预测应该要和所有操作都保留的one-shot模型的预测结果要十分接近。文中使用对称散度来判断相似性,对称散度结果是在64个随机样本上得到的平均值,散度值越接近于0,表示二者输出越相近。
最后的结果如图示,可以看到在训练集上散度值低的模型(即预测值和保留大多数操作的完整模型很接近),在验证集上的准确率也相对高一些。
【【论文笔记系列】- Understanding and Simplifying One-Shot Architecture Search】https://www.cnblogs.com/marsggbo/p/13195496.html
【【NAS-005】2018.07.11- One-Shot -ICML 2018】https://zhuanlan.zhihu.com/p/73539339
【NAS 学习笔记(四)- One-Shot Architecture Search】https://chengfeng96.com/blog/2019/11/28/One-Shot-Architecture-Search笔记/
【AutoDL论文解读(七):基于one-shot的NAS】https://blog.csdn.net/u014157632/java/article/details/102600575
标签:ble while different let rev only choice input 模型
原文地址:https://www.cnblogs.com/chenbong/p/13284493.html