标签:cross 代码 put oss pandas detail 模型 mod 流式
管道机制在机器学习算法中的应用:参数集在新数据集(比如测试集)上的重复使用。
管道机制实现流式化封装和管理。
主要有两点好处:
import pandas as pd from sklearn.pipeline import Pipeline from sklearn.cross_validation import train_test_split from sklearn.preprocessing import LabelEncoder df = pd.read_csv(‘https://archive.ics.uci.edu/ml/machine-learning-databases/‘ ‘breast-cancer-wisconsin/wdbc.data‘, header=None) X, y = df.values[:, 2:], df.values[:, 1] # y为标签 encoder = LabelEncoder() y = encoder.fit_transform(y) encoder.transform([‘M‘, ‘B‘])
array([1, 0], dtype=int64)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.2, random_state=0) print(y_train)
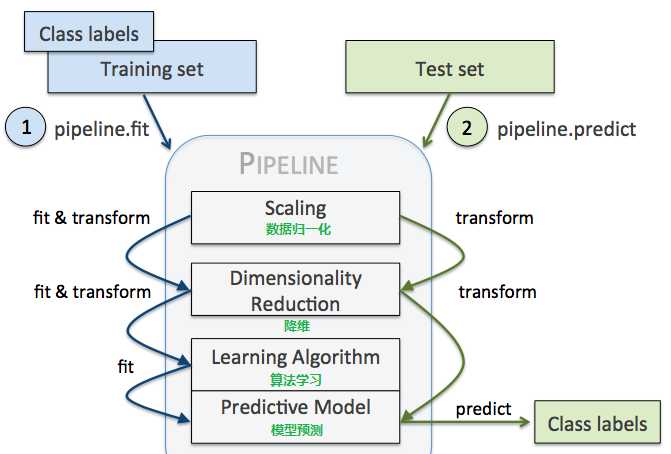
Pipeline中的步骤可能有:
from sklearn.preprocessing import StandardScaler from sklearn.decomposition import PCA from sklearn.linear_model import LogisticRegression from sklearn.pipeline import Pipeline pipe_lr = Pipeline([(‘sc‘, StandardScaler()), #标准定标器 (‘pca‘, PCA(n_components=2)), (‘clf‘, LogisticRegression(random_state=1)) ]) pipe_lr.fit(X_train, y_train) print(‘Test accuracy: %.3f‘ % pipe_lr.score(X_test, y_test))
Pipeline的中间过程由scikit-learn相适配的转换器(transform)构成,最后一步是一个estimator。
比如上述代码,StandardScaler和PCA transformer是中间过度过程,LogisticRegression作为最终的评估器。
当执行pipe_lr.fit(X_train, y_train)时,
首先由StandardScaler在训练集上执行fit和transform方法,
transformed后的数据又被传递给Pipeline对象的下一步,即PCA()
和StandardScaler一样,PCA也执行fit和transform方法,
最后将转换后的数据传递给LosigsticRegression。
来自:https://blog.csdn.net/wsp_1138886114/article/details/81179911
标签:cross 代码 put oss pandas detail 模型 mod 流式
原文地址:https://www.cnblogs.com/keye/p/13365596.html