标签:strong node 最好 open 文件 工业 可视化 需要 业务逻辑
在微服务架构中,一次请求往往涉及到多个模块,多个中间件,多台机器的相互协作才能完成。这一系列调用请求中,有些是串行的,有些是并行的,那么如何确定这个请求背后调用了哪些应用,哪些模块,哪些节点及调用的先后顺序?如何定位每个模块的性能问题?本文将为你揭晓答案。
本文将会从以下几个方面来阐述
如何衡量一个接口的性能好坏,一般我们至少会关注以下三个指标
在初期,公司刚起步的时候,可能多会采用如下单体架构,对于单体架构我们该用什么方式来计算以上三个指标呢?
最容易想到的显然是用 AOP

使用 AOP 在调用具体的业务逻辑前后分别打印一下时间即可计算出整体的调用时间,使用 AOP 来 catch 住异常也可知道是哪里的调用导致的异常。
在单体架构中由于所有的服务,组件都在一台机器上,所以相对来说这些监控指标比较容易实现,不过随着业务的快速发展,单体架构必然会朝微服务架构发展:如下

如图示:一个稍微复杂的微服务架构
如果有用户反馈某个页面很慢,我们知道这个页面的请求调用链是 A -----> C -----> B -----> D,此时如何定位可能是哪个模块引起的问题。每个服务 Service A,B,C,D 都有好几台机器。怎么知道某个请求调用了服务的具体哪台机器呢?

可以明显看到,由于无法准确定位每个请求经过的确切路径,在微服务这种架构下有以下几个痛点
分布式调用链就是为了解决以上几个问题而生,它主要的作用如下
通过分布式追踪系统能很好地定位如下请求的每条具体请求链路,从而轻易地实现请求链路追踪,每个模块的性能瓶颈定位与分析。

知道了分布式调用链的作用,那我们来看下如何实现分布式调用链的实现及原理, 首先为了解决不同的分布式追踪系统 API 不兼容的问题,诞生了 OpenTracing 规范,OpenTracing 是一个轻量级的标准化层,它位于应用程序/类库和追踪或日志分析程序之间。

这样 OpenTracing 通过提供平台无关,厂商无关的 API,使得开发人员能否方便地添加追踪系统的实现。
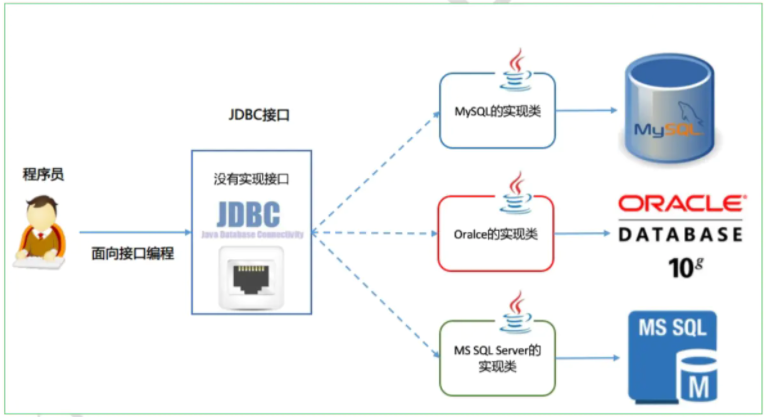
说到这大家是否想过 Java 中类似的实现?还记得 JDBC 吧,通过提供一套标准的接口让各个厂商去实现,程序员即可面对接口编程,不用关心具体的实现。这里的接口其实就是标准,所以制定一套标准非常重要,可以实现组件的可插拔。
接下来我们来看 OpenTracing 的数据模型,主要有以下三个
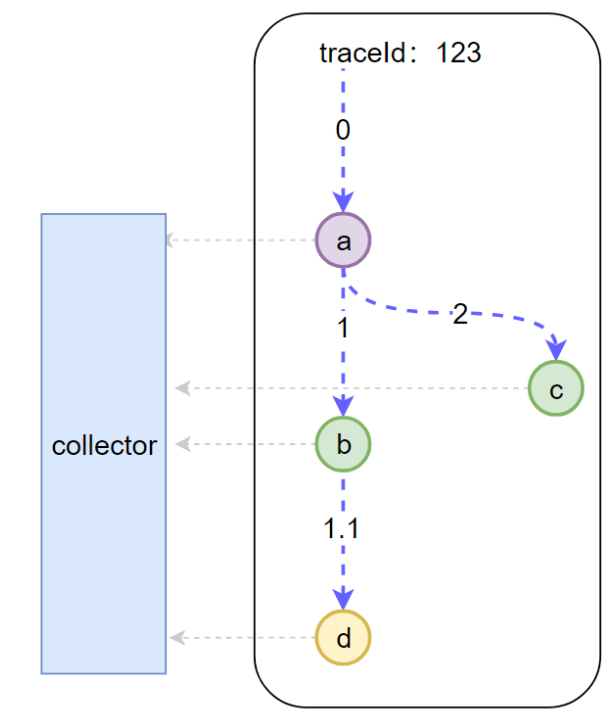
理解这三个概念非常重要,为了让大家更好地理解这三个概念,我特意画了一张图

如图示,一次下单的完整请求完整就是一个 Trace, 显然对于这个请求来说,必须要有一个全局标识来标识这一个请求,每一次调用就称为一个 Span,每一次调用都要带上全局的 TraceId, 这样才可把全局 TraceId 与每个调用关联起来,这个 TraceId 就是通过 SpanContext 传输的,既然要传输显然都要遵循协议来调用。如图示,我们把传输协议比作车,把 SpanContext 比作货,把 Span 比作路应该会更好理解一些。
理解了这三个概念,接下来我看看分布式追踪系统如何采集统一图中的微服务调用链
我们可以看到底层有一个 Collector 一直在默默无闻地收集数据,那么每一次调用 Collector 会收集哪些信息呢。
有了这些信息,Collector 收集的每次调用的信息如下

根据这些图表信息显然可以据此来画出调用链的可视化视图如下
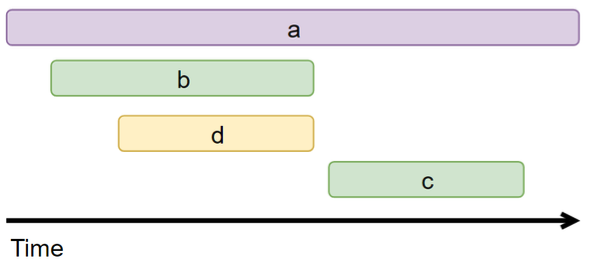
于是一个完整的分布式追踪系统就实现了。
以上实现看起来确实简单,但有以下几个问题需要我们仔细思考一下
接下我来看看 SkyWalking 是如何解决以上四人问题的
SkyWalking 采用了插件化 + javaagent 的形式来实现了 span 数据的自动采集,这样可以做到对代码的 无侵入性,插件化意味着可插拔,扩展性好(后文会介绍如何定义自己的插件)

我们知道数据一般分为 header 和 body, 就像 http 有 header 和 body, RocketMQ 也有 MessageHeader,Message Body, body 一般放着业务数据,所以不宜在 body 中传递 context,应该在 header 中传递 context,如图示

dubbo 中的 attachment 就相当于 header ,所以我们把 context 放在 attachment 中,这样就解决了 context 的传递问题。

小提示:这里的传递 context 流程均是在 dubbo plugin 处理的,业务无感知,这个 plugin 是怎么实现的呢,下文会分析
要保证全局唯一 ,我们可以采用分布式或者本地生成的 ID,使用分布式话需要有一个发号器,每次请求都要先请求一下发号器,会有一次网络调用的开销,所以 SkyWalking 最终采用了本地生成 ID 的方式,它采用了大名鼎鼎的 snowflow 算法,性能很高。

图示: snowflake 算法生成的 id
不过 snowflake 算法有一个众所周知的问题:时间回拨,这个问题可能会导致生成的 id 重复。那么 SkyWalking 是如何解决时间回拨问题的呢。

每生成一个 id,都会记录一下生成 id 的时间(lastTimestamp),如果发现当前时间比上一次生成 id 的时间(lastTimestamp)还小,那说明发生了时间回拨,此时会生成一个随机数来作为 traceId。这里可能就有同学要较真了,可能会觉得生成的这个随机数也会和已生成的全局 id 重复,是否再加一层校验会好点。
这里要说一下系统设计上的方案取舍问题了,首先如果针对产生的这个随机数作唯一性校验无疑会多一层调用,会有一定的性能损耗,但其实时间回拨发生的概率很小(发生之后由于机器时间紊乱,业务会受到很大影响,所以机器时间的调整必然要慎之又慎),再加上生成的随机数重合的概率也很小,综合考虑这里确实没有必要再加一层全局惟一性校验。对于技术方案的选型,一定要避免过度设计,过犹不及。
如果对每个请求调用都采集,那毫无疑问数据量会非常大,但反过来想一下,是否真的有必要对每个请求都采集呢,其实没有必要,我们可以设置采样频率,只采样部分数据,SkyWalking 默认设置了 3 秒采样 3 次,其余请求不采样,如图示

这样的采样频率其实足够我们分析组件的性能了,按 3 秒采样 3 次这样的频率来采样数据会有啥问题呢。理想情况下,每个服务调用都在同一个时间点(如下图示)这样的话每次都在同一时间点采样确实没问题
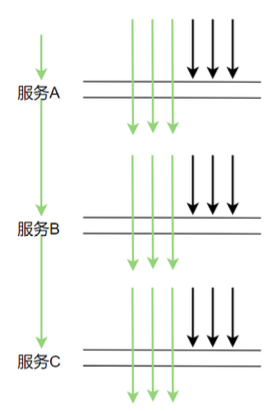
但在生产上,每次服务调用基本不可能都在同一时间点调用,因为期间有网络调用延时等,实际调用情况很可能是下图这样
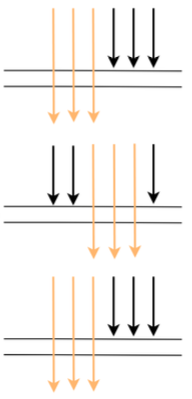 这样的话就会导致某些调用在服务 A 上被采样了,在服务 B,C 上不被采样,也就没法分析调用链的性能,那么 SkyWalking 是如何解决的呢。
这样的话就会导致某些调用在服务 A 上被采样了,在服务 B,C 上不被采样,也就没法分析调用链的性能,那么 SkyWalking 是如何解决的呢。
它是这样解决的:如果上游有携带 Context 过来(说明上游采样了),则下游强制采集数据。这样可以保证链路完整。
SkyWalking 的基础如下架构,可以说几乎所有的的分布式调用都是由以下几个组件组成的

首先当然是节点数据的定时采样,采样后将数据定时上报,将其存储到 ES, MySQL 等持久化层,有了数据自然而然可根据数据做可视化分析。
接下来大家肯定比较关心 SkyWalking 的性能,那我们来看下官方的测评数据
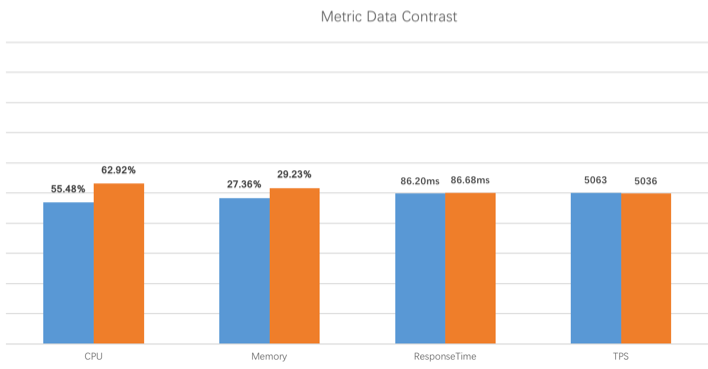
图中蓝色代表未使用 SkyWalking 的表现,橙色代表使用了 SkyWalking 的表现,以上是在 TPS 为 5000 的情况下测出的数据,可以看出,不论是 CPU,内存,还是响应时间,使用 SkyWalking 带来的性能损耗几乎可以忽略不计。
接下来我们再来看 SkyWalking 与另一款业界比较知名的分布式追踪工具 Zipkin, Pinpoint 的对比(在采样率为 1 秒 1 个,线程数 500,请求总数为 5000 的情况下做的对比),可以看到在关键的响应时间上, Zipkin(117ms),PinPoint(201ms)远逊色于 SkyWalking(22ms)!

从性能损耗这个指标上看,SkyWalking 完胜!
再看下另一个指标:对代码的侵入性如何,ZipKin 是需要在应用程序中埋点的,对代码的侵入强,而 SkyWalking 采用 javaagent + 插件化这种修改字节码的方式可以做到对代码无任何侵入,除了性能和对代码的侵入性上 SkyWaking 表现不错外,它还有以下优势几个优势
对多语言的支持,组件丰富:目前其支持 Java, .Net Core, PHP, NodeJS, Golang, LUA 语言,组件上也支持dubbo, mysql 等常见组件,大部分能满足我们的需求。
扩展性:对于不满足的插件,我们按照 SkyWalking 的规则手动写一个即可,新实现的插件对代码无入侵。
由上文可知 SkyWalking 有很多优点,那么是不是我们用了它的全部组件了呢,其实不然,来看下其在我司的应用架构
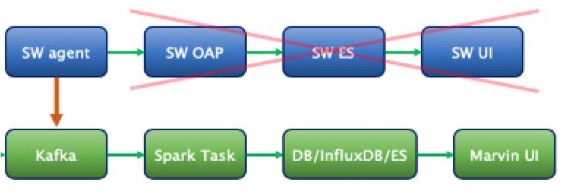
从图中可以看出我们只采用了 SkyWalking 的 agent 来进行采样,放弃了另外的「数据上报及分析」,「数据存储」,「数据可视化」三大组件,那为啥不直接采用 SkyWalking 的整套解决方案呢,因为在接入 SkyWalking 之前我们的 Marvin 监控生态体系已经相对比较完善了,如果把其整个替换成 SkyWalking,一来没有必要,Marvin 在大多数场景下都能满足我们的需求,二来系统替换成本高,三来如果重新接入用户学习成本很高。
这也给我们一个启示:任何产品抢占先机很重要,后续产品的替换成本会很高,抢占先机,也就是抢占了用户的心智,这就像微信虽然 UI,功能上制作精良,但在国外照样干不过 Whatsapp 一样,因为先机已经没了。
从另一方面来看,对架构来说,没有最好的,最有最合适的,结合当前业务场景去平衡折中才是架构设计的本质
我司主要作了以下改造和实践
从上文分析可知 Collector 是在后台定时采样的,这不挺好的吗,为啥要实现强制采样呢。还是为了排查定位问题,有时线上出现问题,我们希望在预发上能重现,希望能看到这个请求的完整调用链,所以在预发上实现强制采样很有必要。所以我们对 Skywalking 的 dubbo 插件进行了改造,实现强制采样
我们在请求的 Cookie 上带上一个类似 force_flag = true 这样的键值对来表示我们希望强制采样,在网关收到这个 Cookie 后,就会在 dubbo 的 attachment 里带上force_flag = true 这个键值对,然后 skywalking 的 dubbo 插件就可以据此来判断是否是强制采样了,如果有这个值即强制采样,如果没有这个值,则走正常的定时采样。

哈叫更细粒度的采样。先来看下 skywalking 默认的采样方式 ,即统一采样

我们知道这种方式默认是 3 秒采样前 3 次,其他请求都丢弃,这样的话有个问题,假设在这台机器上在 3 秒内有多个 dubbo,mysql,redis 调用,但在如果前三次都是 dubbo 调用的话,其他像 mysql, redis 等调用就采样不到了,所以我们对 skywalking 进行了改造,实现了分组采样,如下

就是说 3 秒内进行 3 次 redis, dubbo, mysql 等的采样,也就避免了此问题
输出日志中嵌入 traceId 便于我们排查问题,所以打出出 traceId 非常有必要,该怎么在日志中嵌入 traceId 呢? 我们用的是 log4j,这里就要了解一下 log4j 的插件机制了,log4j 允许我们自定义插件来输出日志的格式,首先我们需要定义日志的格式,在自定义的日志格式中嵌入 %traceId, 作为占位符,如下

然后我们再实现一个 log4j 的插件,如下

首先 log4j 的插件要定义一个类,这个类要继承 LogEventPatternConverter 这个类,并且用标准 Plugin 将其自身声明为 Plugin,通过 @ConverterKeys 这个注解指定了要替换的占位符,然后在 format 方法里将其替换掉。这样在日志中就会出现我们想要的 TraceId ,如下

SkyWalking 实现了很多插件,不过未提供 memcached 和 druid 的插件,所以我们根据其规范自研了这两者的插件

插件如何实现呢,可以看到它主要由三个部分组成
可能大家看了还是不懂,那我们以 dubbo plugin 来简单讲解一下,我们知道在 dubbo 服务中,每个请求从 netty 接收到消息,递交给业务线程池处理开始,到真正调用到业务方法结束,中间经过了十几个 Filter 的处理

而 MonitorFilter 可以拦截所有客户端发出请求或者服务端处理请求,所以我们可以对 MonitorFilter 作增强,在其调用 invoke 方法前,将全局 traceId 注入到其 Invocation 的 attachment 中,这样就可以确保在请求到达真正的业务逻辑前就已经存在全局 traceId。
所以显然我们需要在插件中指定我们要增强的类(MonitorFilter),对其方法(invoke)做增强,要对这个方法做哪些增强呢,这就是拦截器(Inteceptor)要做的事,来看看 Dubbo 插件中的 instrumentation(DubboInstrumentation)

我们再看看下代码中描写的拦截器(Inteceptor)干了什么事,以下列出关键步骤

首先这个这个 beforeMethod 代表在执行 MonitorFilter 的 invoke 方法前会调用这里的方法,与之对应的是 afterMethod,代表在执行 invoke 方法后作增强逻辑。
其次我们从第 2,3点可以看到,不管是 consumer 还是 provider, 都对其全局 ID 作了相应处理,这样确保到达真正的业务层的时候保证有了此全局 traceid,定义好 Instrumentation 和 Interceptor 后,最后一步就是在 skywalking.def 里指定定义的类
// skywalking-plugin.def 文件
dubbo=org.apache.skywalking.apm.plugin.asf.dubbo.DubboInstrumentation
这样打包出来的插件就会对 MonitorFilter 的 invoke 方法进行增强,在 invoke 方法执行前对期 attachment 作注入全局 traceId 等操作,这一切都是静默的,对代码无侵入的。
本文由浅入深地介绍了分布式追踪系统的原理,相信大家对其作用及工作机制有了比较深的理解,特别需要注意的是,引入某项技巧,一定要结合现有的技术架构作出最合理的选择,就像 SkyWalking 有四个模块,我司只采用其 agent 采样功能一样,没有最好的技术,只有最合适的技术,通过此文,相信大家应该对 SkyWalking 的实现机制有了比较清晰的认识,文中只是介绍了一下 SkyWalking 的插件实现方式,不过其毕竟是工业级软件,要了解其博大精深,还要多读源码哦。
最后欢迎大家关注我的公号,加我好友:「geekoftaste」,一起交流,共同进步!

标签:strong node 最好 open 文件 工业 可视化 需要 业务逻辑
原文地址:https://www.cnblogs.com/xiekun/p/13638076.html