标签:class 通过 ssi googl report 介绍 print pip stc
作者|Rebecca Vickery
编译|VK
来源|Towards Datas Science

scikit-learn是2007年作为Googles Summer代码项目开发的,现在被广泛认为是最流行的机器学习Python库。
为什么这个库被认为是机器学习项目的最佳选择之一,特别是在生产系统中,有许多原因。这些包括但不限于以下内容。
它对库的开发有很高的支持和严格的管理,这意味着它是一个非常健壮的工具。
有一个清晰、一致的代码风格,确保机器学习代码易于理解和可复制,同时也大大降低了编写机器学习模型的门槛。
它受到第三方工具的广泛支持,因此可以丰富功能以适应各种用例。
如果你正在学习机器学习,那么Scikit learn可能是开始学习的最佳库。它的简单性意味着它相当容易掌握,通过学习如何使用它,你还可以很好地掌握典型的机器学习工作流中的关键步骤。
下面这篇文章是对该工具的初学者友好的介绍,应该能让你对开发一个简单的机器学习模型有足够的了解。
要安装Scikit的最新版本,请运行以下命令。
pip install scikit-learn
本文中的代码示例运行在可以直接从Scikit-learn api导入的经典wine数据集上。
from sklearn.datasets import load_wine
X,y = load_wine(return_X_y=True)
Scitkit学习库提供了大量的预构建算法来执行有监督和无监督的机器学习。它们通常被称为Estimators。
你为你的项目选择的Estimators将取决于你拥有的数据集和你试图解决的问题。Scikit学习文档提供了如下所示的图表,帮助你确定哪种算法适合你的任务。
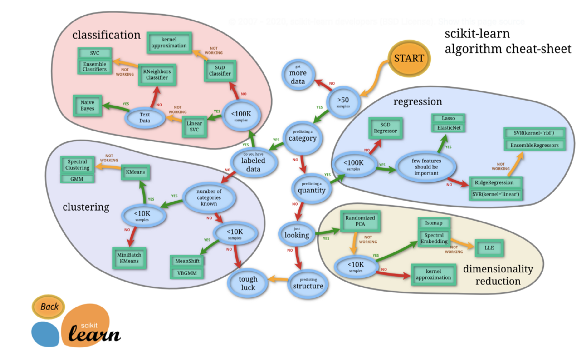
Scikit learn之所以能如此直接地使用,是因为无论你使用的模型或算法是什么,用于模型训练和预测的代码结构都是相同的。
为了说明这一点,让我们通过一个例子。
假设你正在处理一个回归问题,并希望训练一个线性回归算法,并使用得到的模型进行预测。使用Scikit learn的第一步是调用logistic回归Estimator并将其另存为对象。下面的示例调用该算法并将其保存为一个名为lr的对象。
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
下一步是根据一些训练数据拟合模型。这是使用fit()方法执行的。我们在特征和目标数据调用lr.fit(),并将生成的模型另存为名为model的对象。在下面的例子中,我也用train方法将数据集分割成测试集。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
model = lr.fit(X_train, y_train)
下一步,我们使用模型和predict()方法来预测以前看不到的数据。
predictions = model.predict(X_test)
如果我们现在要使用Scitkit learn执行不同的任务,比如说,我们想训练一个随机森林分类器。代码看起来非常相似,并且具有相同的步骤数。
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier()
rf_model = rf.fit(X_train, y_train)
rf_predictions = rf_model.predict(X_test)
这种一致的代码结构使得开发机器学习模型非常直接,而且生成的代码具有很高的可读性和可重复性。
在大多数实际的机器学习项目中,你使用的数据不一定准备好训练模型。你很可能首先需要执行一些数据预处理和转换步骤,例如处理缺失值、将类别数据转换为数值或应用特征缩放。
scikitlearn有内置的方法来执行这些预处理步骤。例如,SimpleImputer()使用你选择的方法填充缺少的值。
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy=‘mean‘)
X_train_clean = imputer.fit(X_train)
Scikit学习文档在这里列出了数据预处理的完整选项。
一旦一个模型被训练过,你需要衡量这个模型在预测新数据方面有多好。此步骤称为模型评估,你选择的度量将由你尝试解决的任务确定。例如,通常在回归问题中,你可以选择RMSE,而对于分类,你可以选择F1分数。
所有Estimator都包含一个score()方法,该方法返回与所执行的机器学习任务最相关的默认度量。
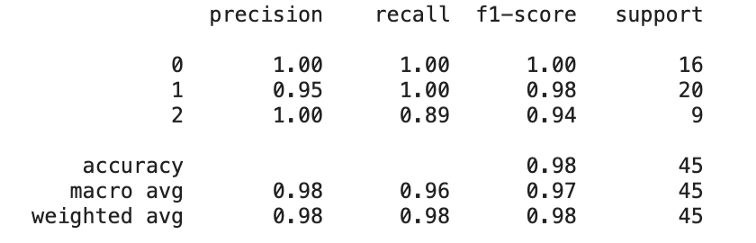
Scikit learn还提供了一组度量函数,这些函数为模型提供了更详细的评估。例如,对于分类任务,库有一个分类报告,它提供精度、召回率、F1分数和总体准确度。
分类报告代码和输出如下所示。
from sklearn.metrics import classification_report
print(classification_report(rf_predictions, y_test))
Scikit学习库中的所有Estimator都包含一系列参数,其中有多个选项。为特定算法选择的值将影响最终模型的性能。例如,使用RandomForestClassifier,可以将树的最大深度设置为可能的任何值,并且根据你的数据和任务,此参数的不同值将产生不同的结果。
这种尝试不同参数组合以找到最佳组合的过程称为超参数优化。
Scikit learn提供了两个工具来自动执行此任务,GridSearchCV实现了一种称为穷举网格搜索的技术,RandomizedSearchCV执行随机参数优化。
下面的示例使用GridSearchCV为RandomForestClassifier查找最佳参数。输出显示在代码下面。
param_grid = {
‘n_estimators‘: [200, 500],
‘max_features‘: [‘auto‘, ‘sqrt‘, ‘log2‘],
‘max_depth‘ : [4,5,6,7,8],
‘criterion‘ :[‘gini‘, ‘entropy‘]
}
from sklearn.model_selection import GridSearchCV
CV = GridSearchCV(rf, param_grid, n_jobs= 1)
CV.fit(X_train, y_train)
print(CV.best_params_)
print(CV.best_score_)
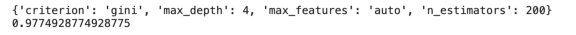
Scikit-learn包以管道的形式提供了更方便的代码封装形式。此工具使所有预处理任务都可以与分类器步骤链接在一起,因此只需对单个管道对象调用fit()或predict()即可执行工作流中的所有步骤。
这使得代码具有很高的可读性,并减少了机器学习工作流中的重复步骤。
为了创建管道,我们首先在下面的代码中定义我称为pipe的对象中的步骤。然后我们可以简单地调用这个对象的fit来训练模型。管道对象还可以用于对新数据进行预测。
from sklearn.pipeline import Pipeline
pipe = Pipeline([(‘imputer‘, SimpleImputer()), (‘rf‘, RandomForestClassifier())])
pipeline_model = pipe.fit(X_train, y_train)
pipeline_model.score(X_test, y_test)
原文链接:https://towardsdatascience.com/a-beginners-guide-to-scikit-learn-14b7e51d71a4
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
标签:class 通过 ssi googl report 介绍 print pip stc
原文地址:https://www.cnblogs.com/panchuangai/p/13866971.html