标签:大数 某服务 desc eth 采集 类型 director time buffers
采集需求:某服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到HDFS中去
结构示意图:
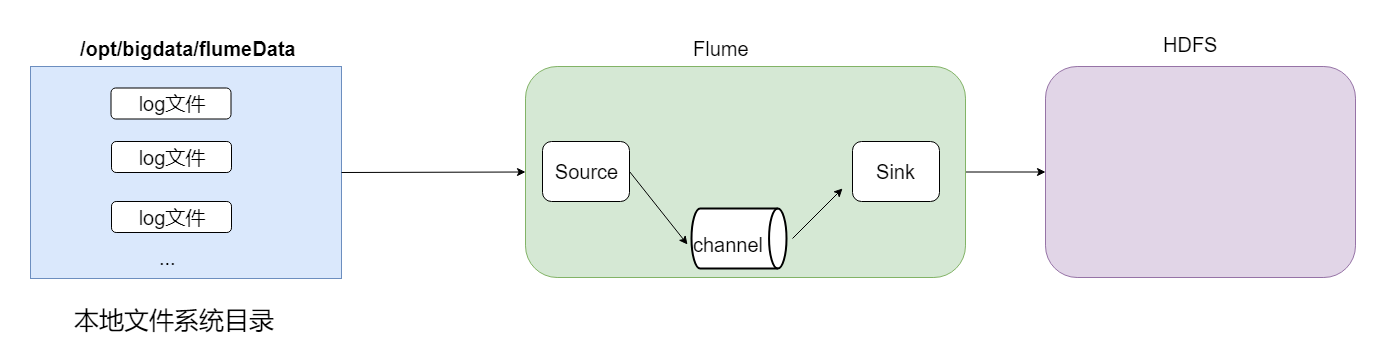
根据需求,首先定义以下3大要素
数据源组件,即source ——监控文件目录 : spooldir
spooldir特性:
1、监视一个目录,只要目录中出现新文件,就会采集文件中的内容
2、采集完成的文件,会被agent自动添加一个后缀:COMPLETED
3、此source可靠,不会丢失数据;即使flume重启或被kill
注意:
所监视的目录中不允许有同名的文件;且文件被放入spooldir后,就不能修改
①如果文件放入spooldir后,又向文件写入数据,会打印错误及停止
②如果有同名的文件出现在spooldir,也会打印错误及停止
下沉组件,即sink——HDFS文件系统 : hdfs sink
通道组件,即channel——可用file channel 也可以用内存channel
配置文件编写:
cd /bigdata/install/flume-1.9.0/conf/
mkdir -p /bigdata/install/mydata/flume/dirfile
vim spooldir.conf
内容如下
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
# 注意:不能往监控目中重复丢同名文件
a1.sources.r1.type = spooldir
# 监控的路径
a1.sources.r1.spoolDir = /bigdata/install/mydata/flume/dirfile
# Whether to add a header storing the absolute path filename
#文件绝对路径放到header
a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
#采集到的数据写入到次路径
a1.sinks.k1.hdfs.path = hdfs://hadoop01:8020/spooldir/files/%y-%m-%d/%H%M/
# 指定在hdfs上生成的文件名前缀
a1.sinks.k1.hdfs.filePrefix = events-
# timestamp向下舍round down
a1.sinks.k1.hdfs.round = true
# 按10分钟,为单位向下取整;如55分,舍成50;38 -> 30
a1.sinks.k1.hdfs.roundValue = 10
# round的单位
a1.sinks.k1.hdfs.roundUnit = minute
# 每3秒滚动生成一个文件;默认30;(0 = never roll based on time interval)
a1.sinks.k1.hdfs.rollInterval = 3
# 每x字节,滚动生成一个文件;默认1024;(0: never roll based on file size)
a1.sinks.k1.hdfs.rollSize = 20
# 每x个event,滚动生成一个文件;默认10; (0 = never roll based on number of events)
a1.sinks.k1.hdfs.rollCount = 5
# 每x个event,flush到hdfs
a1.sinks.k1.hdfs.batchSize = 1
# 使用本地时间
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile;可选DataStream,则为普通文本;可选CompressedStream压缩数据
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# channel中存储的event的最大数目
a1.channels.c1.capacity = 1000
# 每次传输数据,从source最多获得event的数目或向sink发送的event的最大的数目
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
组件官网地址:
Channel参数解释:
cd /bigdata/install/flume-1.9.0
bin/flume-ng agent -c ./conf -f ./conf/spooldir.conf -n a1 -Dflume.root.logger=INFO,console
将不同的文件上传到下面目录里面去,注意文件不能重名
mkdir -p /home/hadoop/datas
cd /home/hadoop/datas
vim a.txt
# 加入如下内容
ab cd ef
english math
hadoop alibaba
再执行;
cp a.txt /bigdata/install/mydata/flume/dirfile
然后观察flume的console动静、hdfs webui生成的文件
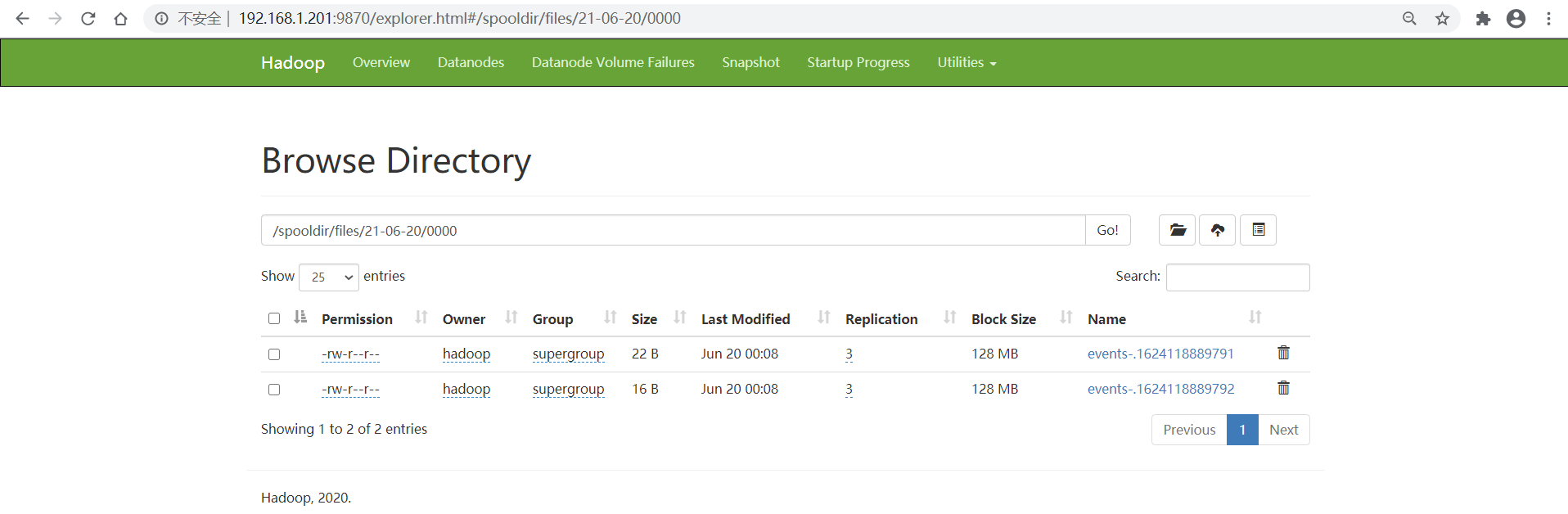
观察spooldir的目标目录

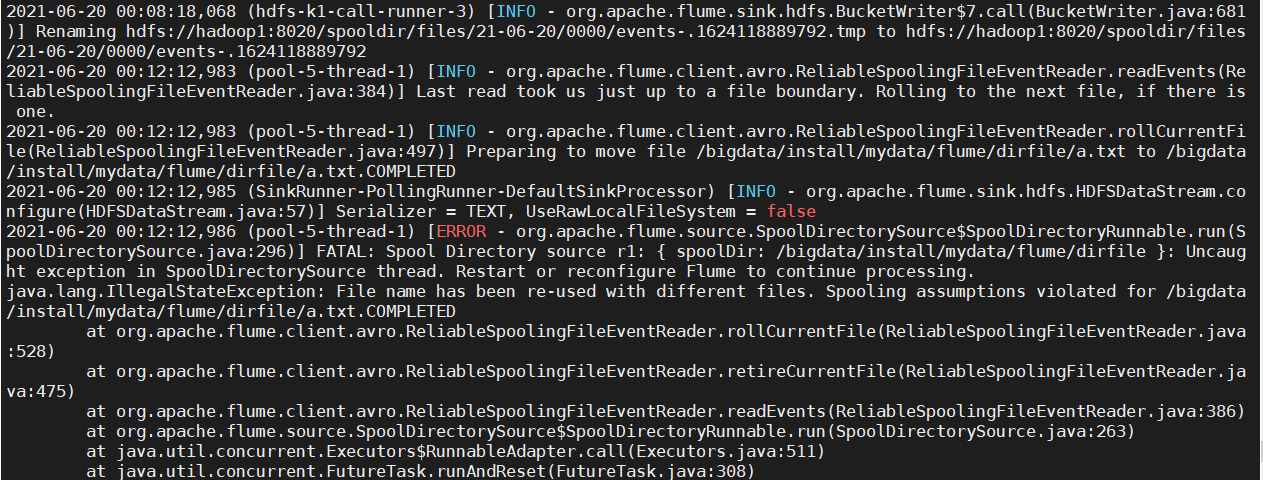
将同名文件再次放到/bigdata/install/mydata/flume/dirfile观察现象:
cp a.txt /bigdata/install/mydata/flume/dirfile
flume控制台报错
标签:大数 某服务 desc eth 采集 类型 director time buffers
原文地址:https://www.cnblogs.com/tenic/p/14905618.html