标签:topic class seve rsa cal max VID dig features
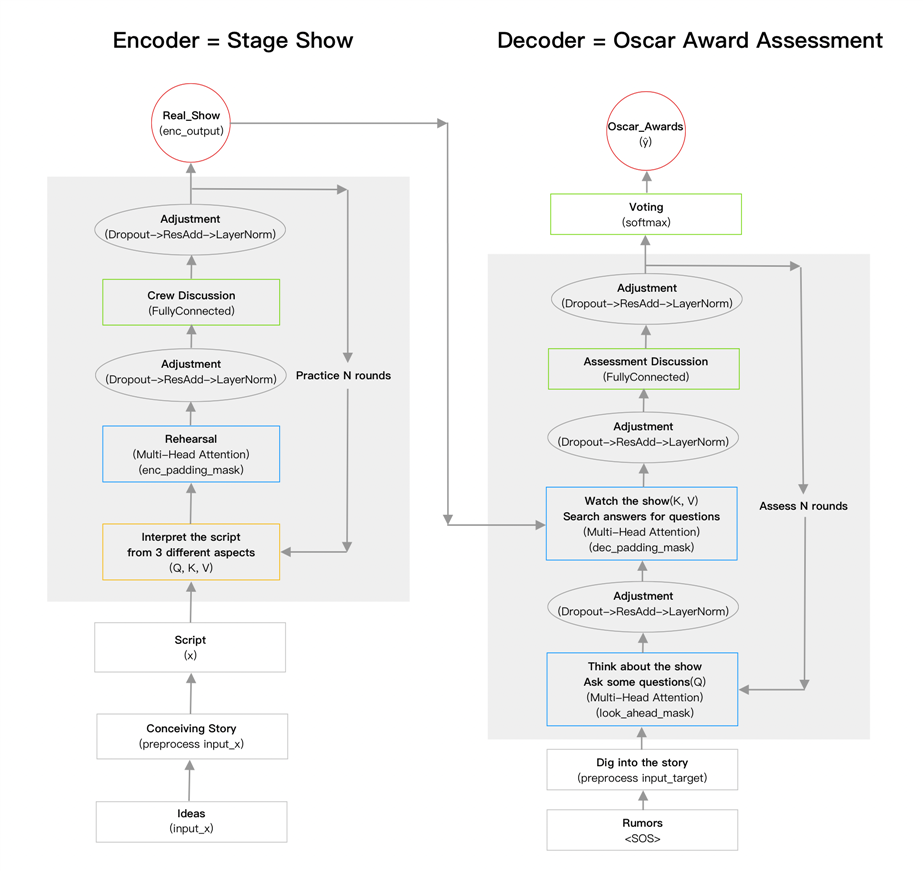
Transformer model is so powerful, and here I try to make it colorful, by interpreting it with a metaphor: Encoder = Stage Show, Decoder = Oscar Award Assessment
In this new perspective, we see the Decoder process as performing a stage show, and the Decoder process is just like the Oscar Award Committee assessing the show.
Below is the graph and interpretation:
Part 1: Encoder = Stage Show
P1. Ideas -> Conceiving_Story -> Script
-
Performing bases on script, script inspires by story, story starts with ideas.
-
Likely, at the beginning of Transformer, we have raw sequence, then we preprocess it to fit the shape of the model.
P2. Script Interpretation -> Rehearsal -> Adjustment
-
Script Interpretation: x is the performing script, can be interpreted from 3 different aspects:
-
Q = plots, K = roles, V = characteristics
-
A script is consisted of a series of plots, each plot is performed by different roles, each role has his own characteristics.
-
In other words, different role performs different characteristic according to the plot, just like different key matches with different query.
-
Further, the same role may perform a different characteristic at different plot, just like the same word may have different meaning at different position of the sequence.
-
If Q=K=V=x, which is plots=roles=characteristics=script, it means s a solo performing, and the actor can perform according to his will to express the theme of the story. In keras Multi-Head Attention API, this is called "self-attention".
-
Rehearsal: Multi-Head attention is interpreted as rehearsal, since it processes script interpretation (Q, K, V), just like actors have a rehearsal after understanding the script.
-
Adjustment: Dropout -> ResAdd -> LayerNorm
-
Dropout: randomly cut some plot of the story, in case of highly depending on some actors’ personal performing or mainly betting on the climax
-
ResAdd: see the connection between each plot, not to isolate them
-
LayerNorm: normalize actors’ performing, in case of actors bringing in too much personal characteristics
P3. Crew Discussion -> Adjustment
P4. Repeat P2 - P3 to practice N rounds
-
P1: input_x -> preprocess(Embedding -> Scale -> Pos_encoding -> Dropout) -> x
-
P2: Query=x, Value=x, Key=x, enc_padding_mask -> Multi_Head_Attention -> adjust(Dropout -> ResAdd -> LayerNorm) -> out1
-
P3: out1 -> FC -> adjust(Dropout -> ResAdd -> LayerNorm) -> out2
-
P4: loop(P2 - P3) -> update(out2)
-
P5: enc_output = out2
Part 2: Decoder = Oscar Award Assessment
P1. Rumors -> Dig into the story
-
At the very beginning, the show is not on, bu rumors (<SOS>) already spread around, attracting people‘s attention, preparing for the premiere.
-
When assessment members hear this rumors, they start to dig into the story, by reading introduction, comments, etc..
-
Likely, we have no real input target but a sign of it <SOS> at the beginning of Decoder, then we do a preprocess for it.
P2. Ask Questions -> Adjustment
P3. Watch the Show & Answer the Questions -> Adjustment
P4. Assessment Discussion -> Adjustment
P5. Repeat P2 - P4 to assess N rounds
P6. Voting -> Oscar Awards Ceremony
-
P1: SOS -> preprocess(Embedding -> Pos_encoding) -> target
-
P2: Query=target, Value=target, Key=target, look_ahead_mask -> Multi-Head Attention -> adjust(Dropout -> ResAdd -> LayerNorm) -> out1
-
P3: Query=out1, Value=enc_output, Key=enc_output, dec_padding_mask -> Multi-Head Attention -> adjust(Dropout -> ResAdd -> LayerNorm) -> out2
-
P4: out2 -> FC -> adjust(Dropout -> ResAdd -> LayerNorm) -> out3
-
P5: loop(P2 - P4) -> update(out3) -> dec_output = out3
-
P6: dec_output -> Dense(‘softmax‘) -> ?
What making the transformer special comparing to other models, is just like the reason why stage show is different with a film:
For stage show, all acts can be performed together at the same time as long as the imagination as well as the stage is big enough, whereas a film is a fixed time sequence that can be only played one screen at a time.
Transformer is like a show, attention is all you need.
Transformer is a show
标签:topic class seve rsa cal max VID dig features
原文地址:https://www.cnblogs.com/DamonLai/p/14922243.html