标签:必须 ram 矩阵 %s tran 出错 mode att log
本章是对应用系统负载和磁盘容量进行分析和预测,涉及到的数据为时间序列数据,因此最后是用ARMA模型去拟合。
本文主要包含以下部分:
关于ARMA模型,具体可看 [ 时间序列中的ARMA模型
](http://www.morefund.com/a/duichongshidian/2011/0422/327.html) 和 [ ARMA百度百科
](https://baike.baidu.com/item/ARMA模型/8048415?fr=aladdin) 。
本文摘录其主要部分:
模型基本原理
将预测指标随时间推移而形成的数据序列看作是一个随机序列,这组随机变量所具有的依存关系体现着原始数据在时间上的延续性。一方面,影响因素的影响,另一方面,又有自身变动规律,假定影响因素为
x 1 , x 2 ,…, x k ,由回归分析,

其中Y是预测对象的观测值,Z为误差。作为预测对象Yt受到自身变化的影响,其规律可由下式体现,

误差项在不同时期具有依存关系,由下式表示,

由此,获得ARMA模型表达式:

其他的模型定义:

ARIMA模型运用的流程
按照上文所述,在进行时间序列模型选择之前需要对数据平稳性进行检验,接下来本文将对平稳性的定义和检验方法进行概述,主要内容参考自 [ 时间序列的平稳性及其检验
](https://wenku.baidu.com/view/75479e2ff8c75fbfc67db218.html) 。
时间序列的平稳性定义
定义:假定某个时间序列是由某一随机过程(stochastic process)生成的,如果满足下列条件:
则称该随机时间序列是 平稳 的(stationary),而该随机过程是一 平稳随机过程 (stationary stochastic
process)。
平稳性检验的图示判断
首先,可通过该序列的 时间路径图 来粗略地判断它是否是平稳的。
具体如图:
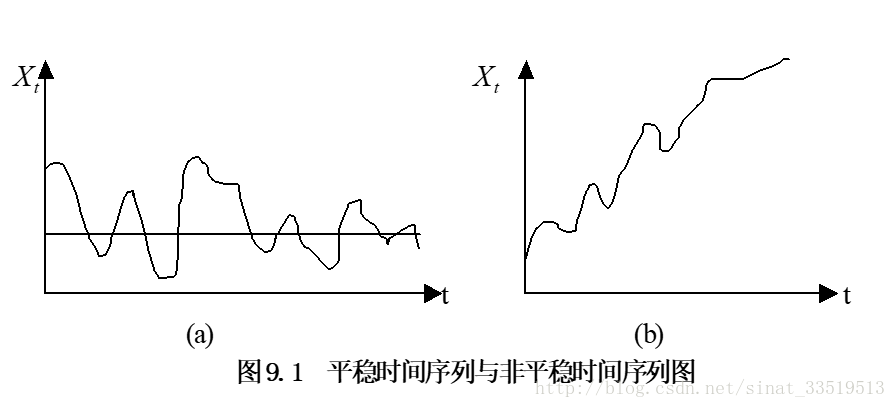
进一步,可通过 检验样本自相关函数及其图形 来判断。
定义随机时间序列的自相关函数(autocorrelation function, ACF)如下:
ρ k = γ k / γ 0
自相关函数是关于滞后期k的递减函数。
实际上,对一个随机过程只有一个实现(样本),因此,只能计算 样本自相关函数 (Sample autocorrelation function)。
一个时间序列的样本自相关函数定义为 :

随着k的增加,样本自相关函数下降且趋于零。但从下降速度来看,平稳序列要比非平稳序列快得多。
具体如下图:

根据书上内容,平稳性检验较为常用的方法还有 单位根检验(ADF)
。单位根检验是指检验序列中是否存在单位根,如果存在单位根就是非平稳时间序列了。单位根就是指单位根过程,可以证明,序列中存在单位根过程就不平稳,会使回归分析中存在伪回归。具体可看
[ 单位根检验
](https://baike.baidu.com/item/单位根检验/5574482?fr=aladdin)
和 时间序列数据的平稳性检验
。
由书中内容可知,为了验证序列中有用的信息是否已被提取完毕,需要对序列进行白噪声检验,如果是白噪声序列,则说明序列中有用的信息已经被提取完毕,剩下的全是随机扰动,无法进行预测和使用。接下来本文将对白噪声序列的定义和检验方法进行概述。
白噪声序列定义
白噪声(对一系列的 ε 1 , ε 2 , ε 3 ….. ε t )定义就三个条件:
白噪声检验方法
按照书中所说,可以用LB统计量进行检验,具体过程如下:
可检验对所有k>0,自相关系数都为0的联合假设,这可通过如下QLB统计量进行:

该统计量近似地服从自由度为m的 χ 2 分布(m为滞后长度)。
因此:如果计算的Q值大于显著性水平为α的临界值,则有1-α的把握拒绝所有 ρ k (k>0)同时为0(该序列是白噪声序列)的假设。
注:上述平稳定检验的链接里,这一段也在平稳性检验里,但通过其他资料的查看,本人认为这一段应该算是在检验白噪声了,其实不管是平稳性检验(主要方法是ACF)还是白噪声检验(LB统计量)都是
对时间序列是否存在滞后相关的一种统计检验 。
接下来,本文对书中应用系统负载分析与磁盘容量预测的实战过程做一个记录。
首先,导入数据,并对数据中C盘和D盘的使用情况做一个 探索性分析 。
代码如下:
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series,DataFrame
import numpy as np
import matplotlib.pyplot as plt
###探索性分析
#设置字体
plt.rcParams[‘font.sans-serif‘] = [‘simHei‘]
plt.rcParams[‘axes.unicode_minus‘] = False
#读取数据
data=pd.read_excel("D:/ProgramData/PythonDataAnalysiscode/chapter11/demo/data/discdata.xls")
#根据C盘和D盘分列数据
data_C=data[(data[‘ENTITY‘]==‘C:\\‘)&(data[‘DESCRIPTION‘]==u‘磁盘已使用大小‘)]
data_D=data[(data[‘ENTITY‘]==‘D:\\‘)&(data[‘DESCRIPTION‘]==u‘磁盘已使用大小‘)]
fig=plt.figure(figsize=(20,20))
ax1=fig.add_subplot(2,1,1)
ax2=fig.add_subplot(2,1,2)
ax1.plot(data_C[‘VALUE‘],‘o-‘)
ax1.set_xlim([0,185])
ax1.set_ylim([33000000,36000000])
ax1.set_title(u‘C盘使用情况‘)
data_C[‘VALUE‘].plot()
ax2.plot(data_D[‘VALUE‘],‘o-‘)
ax2.set_xlim([0,185])
ax2.set_ylim([78000000,92000000])
ax2.set_title(u‘D盘使用情况‘)
plt.show()
结果如下图:
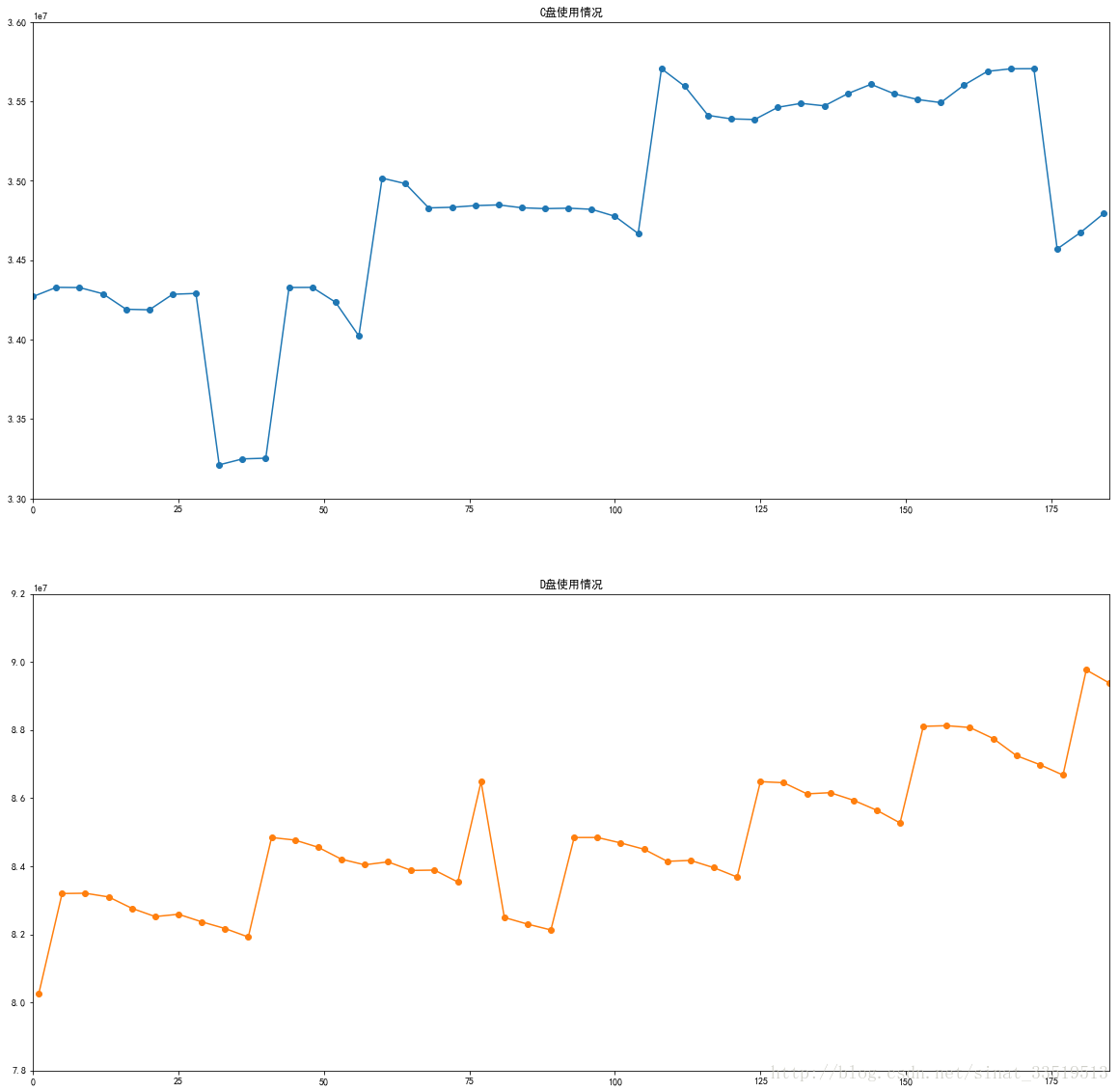
由图可以看出,不管是C盘还是D盘,其使用情况都不具备周期性,表现出缓慢性地增长,呈现趋势性。因此,可初步判断数据是非平稳的。
然后,对 数据进行数据预处理
,主要包括数据清洗和属性转换。其中,数据清洗主要是将磁盘容量的重复值删除,而属性转换则是将代表磁盘属性的三个不变属性进行合并作为一个新的变量,并将C盘和D盘的数据分成两个属性。
代码如下:
# -*- coding: utf-8 -*-
import pandas as pd
from pandas import Series,DataFrame
import numpy as np
#读取数据
data=pd.read_excel("D:/ProgramData/PythonDataAnalysiscode/chapter11/demo/data/discdata.xls")
###数据预处理
#数据清洗,删除重复值(磁盘容量)
data=data.drop_duplicates([‘DESCRIPTION‘,‘VALUE‘])
data_size=data[data[‘DESCRIPTION‘]==u‘磁盘容量‘]
#磁盘容量数据行可以不要
data=data[data[‘DESCRIPTION‘]!=u‘磁盘容量‘]
data_size.to_excel("D:/ProgramData/PythonDataAnalysiscode/chapter11/demo/data/discdata_orsize.xls")
#属性构造
data_group=data.groupby(‘COLLECTTIME‘)
def attr_trans(x):
result=pd.Series(index=[‘SYS_NAME‘,‘CWXT_DB:184:C:\\‘,‘CWXT_DB:184:D:\\‘,‘COLLECTTIME‘])
result[‘SYS_NAME‘]=x[‘SYS_NAME‘].iloc[0]
result[‘CWXT_DB:184:C:\\‘]=x[‘VALUE‘].iloc[0]
result[‘CWXT_DB:184:D:\\‘]=x[‘VALUE‘].iloc[1]
result[‘COLLECTTIME‘]=x[‘COLLECTTIME‘].iloc[0]
return result
data_processed=data_group.apply(attr_trans)
[/code]
最后得到的部分数据结果如下:
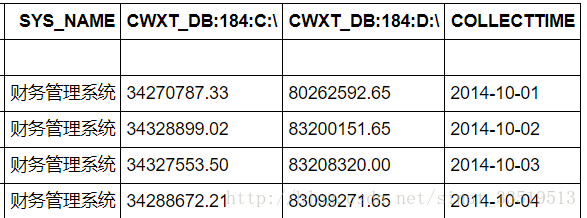
最后,进行模型构建。如上文所说,模型构建之前需要先对数据进行平稳性检验和白噪声检验。
**利用单位根检验(ADF)进行平稳性检验** 和平稳化处理的代码如下:
```code
import pandas as pd
#读取数据
#必须要加index_col,否则后面模型识别时会因为没有时间数据而出错
df=pd.read_excel("D:/ProgramData/PythonDataAnalysiscode/chapter11/demo/data/discdata_processed.xls",index_col=‘COLLECTTIME‘)
#用单位根检验(ADF)进行平稳性检验
data=df.iloc[:(len(df)-5)]
from statsmodels.tsa.stattools import adfuller as ADF
diff=0
adf=ADF(data[‘CWXT_DB:184:D:\\‘])
if adf[1]>0.05:
print (u‘原始序列经检验不平稳,p值为:%s‘%(adf[1]))
else:
print (u‘原始序列经检验平稳,p值为:%s‘%(adf[1]))
while adf[1]>=0.05:#adf[1]为p值,p值小于0.05认为是平稳的
diff=diff+1
adf=ADF(data[‘CWXT_DB:184:D:\\‘].diff(diff).dropna())
print (u‘原始序列经过%s阶差分后归于平稳,p值为%s‘%(diff,adf[1]))
[/code]
输出结果为:
【原始序列经检验不平稳,p值为:0.0838488963412
原始序列经过1阶差分后归于平稳,p值为4.79259126339e-07】
**采用LB统计量的方法进行白噪声检验** 的代码如下:
```code
#采用LB统计量的方法进行白噪声检验
from statsmodels.stats.diagnostic import acorr_ljungbox
[[lb],[p]]=acorr_ljungbox(data[‘CWXT_DB:184:D:\\‘],lags=1)
if p<0.05:
print (u‘原始序列为非白噪声序列,p值为:%s‘%p)
else:
print (u‘原始序列为白噪声序列,p值为:%s‘%p)
[[lb],[p]]=acorr_ljungbox(data[‘CWXT_DB:184:D:\\‘].diff().dropna(),lags=1)
if p<0.05:
print (u‘一阶差分序列为非白噪声序列,p值为:%s‘%p)
else:
print (u‘一阶差分序列为白噪声序列,p值为:%s‘%p)
[/code]
输出结果为:
【原始序列为非白噪声序列,p值为:9.95850372977e-06
一阶差分序列为白噪声序列,p值为:0.114330259776】
最后 **ARMA模型构建** 的代码如下:
```code
#模型识别
#确定最佳p,d,q值
xdata=data[‘CWXT_DB:184:D:\\‘]
from statsmodels.tsa.arima_model import ARIMA
#定阶
pmax = int(len(xdata)/10) #一般阶数不超过length/10
qmax = int(len(xdata)/10) #一般阶数不超过length/10
bic_matrix = [] #bic矩阵
for p in range(pmax+1):
tmp = []
for q in range(qmax+1):
try: #存在部分报错,所以用try来跳过报错。
tmp.append(ARIMA(xdata, (p,1,q)).fit().bic)
except:
tmp.append(None)
bic_matrix.append(tmp)
bic_matrix = pd.DataFrame(bic_matrix) #从中可以找出最小值
p,q = bic_matrix.stack().astype(‘float64‘).idxmin() #先用stack展平,然后用idxmin找出最小值位置。
print (u‘BIC最小的p值和q值为:%s、%s‘ %(p,q))
输出结果为:
【BIC最小的p值和q值为:1、1】
模型确立后,还需检验其 残差序列是否为白噪声 ,如果不是白噪声,说明残差中还存在有用的信息,需要修改模型或进一步提取。
检验代码如下:
#模型检验:模型确立后,检验其残差序列是否为白噪声
lagnum=12#残差延迟个数
from statsmodels.tsa.arima_model import ARIMA #建立ARIMA(p,1,q)模型
arima = ARIMA(xdata, (p, 1, q)).fit() #建立并训练模型
xdata_pred = arima.predict(typ = ‘levels‘) #预测
pred_error = (xdata_pred - xdata).dropna() #计算残差
from statsmodels.stats.diagnostic import acorr_ljungbox #白噪声检验
lb, p_l= acorr_ljungbox(pred_error, lags = lagnum)
h = (p_l < 0.05).sum() #p值小于0.05,认为是非白噪声。
if h > 0:
print (u‘模型ARIMA(%s,1,%s)不符合白噪声检验‘%(p,q))
else:
print (u‘模型ARIMA(%s,1,%s)符合白噪声检验‘ %(p,q))
输出结果为:
【模型ARIMA(1,1,1)符合白噪声检验】。
通过检验之后,进行 预测 。
#模型预测
test_predict=arima.forecast(5)[0]
print (test_predict)
#预测对比
test_data=pd.DataFrame(columns=[u‘实际容量‘,u‘预测容量‘])
test_data[u‘实际容量‘]=df[(len(df)-5):][‘CWXT_DB:184:D:\\‘]
test_data[u‘预测容量‘]=test_predict
[/code]
最后的结果为:
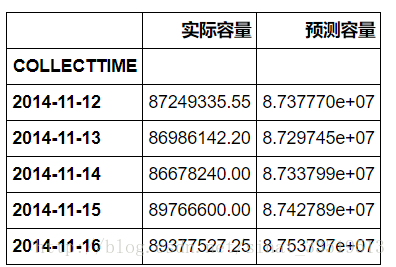
误差绝对值为:
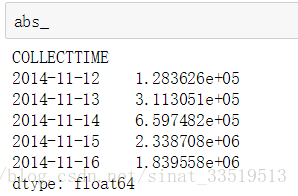
出来的差距有点大,与书上不符,且上文中最后的模型是ARIMA(1,1,1),也与书上的ARIMA(0,1,1)不一样,不知是哪里出了问题。
## 总结
第十章学习到此结束,虽然最后结果不太一样,但这个过程中对时间序列模型、平稳性检验、白噪声检验等都有了一定了解,还是获益匪浅。

标签:必须 ram 矩阵 %s tran 出错 mode att log
原文地址:https://www.cnblogs.com/lj-C/p/14944505.html