标签:++i space log 长度 mis 串匹配 为什么 影响 targe
在竞赛中 KMP 已经考的比较少了,然而习题还是要做的。
KMP 的练习题目一般是围绕着 \(next\) 数组和 \(f\) 数组的不同理解出发的,具体请看例题。
题目链接:Link
题目描述:
给定一个字符串 \(A\) ,\(A\) 是由另一个字符串 \(B\) 不断循环拼接而成的(可能不是整数个 \(B\)),求 \(B\) 可能长度的最小值。
Solution:
这道题目不难,但是如果自己独立思考想出解法,可以极大提升对 KMP 算法 \(next\) 数组的理解。
首先,假设这个字符串最短的长度为 \(k\) ,那么 \(A_{k+1}\rightarrow A_{k+k}\) (假设 \(A\) 长度 \(N\) ,\(N>2k\))一定等于 \(A_1\rightarrow A_k\) 。如果对 \(A\) 进行自我匹配,求出 \(next\) 数组,则 \(next_{k+1}\rightarrow next_{N}\) 应该成首项为 1 ,公差为 1 的等差数列,因为第一个 \(B\) 串一定可以和第二个、第三个、第 \(n\) 个 \(B\) 串完全匹配,如下表:
1 2 3 4 5 6 7 8 9...
a a b a a a b a a...
next 0 1 0 1 1 2 3 4 5...
\(next_5\) 是这个等差数列的第一项,那么这个等差数列的最后一项为 \(next_8=5\) ,根据等差数列的公式得知项数 \(n\) 等于 最后一项 \(next_8\) 的值。又因为答案为这个等差数列第一项的前一项,所以最后答案就是 \(n-next_n\) 。
Code:
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<iostream>
//using namespace std;
const int maxn=1000005;
int n;
char str[maxn];
int next[maxn];
void kmp(){
next[1]=0;
for(int i=2,j=0;i<=n;++i){
while(j>0 && str[i]!=str[j+1]) j=next[j];
if(str[i]==str[j+1]) j++;
next[i]=j;
}
printf("%d\n",n-next[n]);
}
signed main(){
scanf("%d",&n);
scanf("%s",str+1);
kmp();
return 0;
}
题目链接:Link
题目描述:
洛谷上给出的翻译比较简略,这里重新翻译一下题面。(原版英文题面)
给定字符串长度 \(N(N\leq 1e6)\) ,然后给出一个长度为 \(N\) 的字符串 \(A\) 。
如果对于 \(A\) 的前 \(i\) 个字符是严格循环同构的(由一个字符串 \(B\) 首尾相连 \(n(n\geq 2)\) 次构成),输出 \(i,n\) 。
有多组数据,如果 \(N=0\) 表示输入结束。
Solution:
本题和 T1 有异曲同工之处,类似 T1 的思路,先对字符串跑 KMP 求出 \(next\) 数组。
利用上面的结论,如果一个字符串从第一项开始循环同构,那么它的最小循环节为 \(i-next_i\) 。
假设字符串 \(A\) 的某个前缀长度为 \(i\) ,已经求出它的最小循环节,则这个循环节出现的次数应该是 \(\frac{i}{i-next_i}\) 。
根据题目要求,答案应该满足 \(\frac{i}{i-next_i}\geq 2,i\%\frac{i}{i-next_i}=0\) ,于是扫描 \(next\) 数组,输出答案即可。
Code:
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
//using namespace std;
const int maxn=1000005;
char str[maxn];
int next[maxn];
int n=1,cas;
void kmp(){
next[1]=0;
for(int i=2,j=0;i<=n;++i){
while(j>0 && str[i]!=str[j+1]) j=next[j];
if(str[i]==str[j+1]) j++;
next[i]=j;
}
printf("Test case #%d\n",cas);
for(int i=2;i<=n;++i){//扫描、判断答案是否合法
if(next[i]*2>=i && i%(i-next[i])==0)
printf("%d %d\n",i,i/(i-next[i]));
}
puts("");
}
signed main(){
while(n){
scanf("%d",&n);
if(n){
cas++;
scanf("%s",str+1);
kmp();
}
}
return 0;
}
题目链接:Link
题目描述:
给定两个字符串 \(A\) ,\(B\) 要求从 \(A\) 中不断删除找到的第一个 \(B\) ,然后拼接剩下的串,输出删除后的串。
注意:删除之后,两端的 \(A\) 串剩余部分可能会再拼成一个 \(B\) 串
Solution:
设 \(A\) 长度为 \(n\) ,\(B\) 的长度为 \(m\) 。
显然这题是字符串匹配题,要从 \(A\) 中匹配 \(B\) ,可以使用 KMP 查找 \(B\) 的位置。
这里删除操作不影响 \(B\),所以先跑 KMP 的第一阶段,求出 \(B\) 的 \(next\) 数组。
然后,还是一位一位地求解 \(f\) 数组,如果还没和 \(B\) 串匹配上,就把这一位的 \(A\) 加入答案串,答案串长度++。
如果匹配上了,把答案串删掉 \(m\) 位,然后从 \(m\) 位之前重新开始匹配。
注意这个操作需要更新 \(j\) 的值为上一个答案的 \(f\) 值,这样相当于忽略了中间的 \(m\) 个字符继续进行匹配操作。
由于数组不太好操作,这里我使用了 STL stack 来实现记录答案和更新 \(j\) 的操作。
Code:
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
#include<stack>
//using namespace std;
const int maxn=1000005;
char A[maxn],B[maxn];//A原串,B模式串
int lena,lenb;
int next[maxn],f[maxn];
std::stack<char>stk;
std::stack<int>s;
char ans[maxn];
void kmp(){
next[1]=0;
for(int i=2,j=0;i<=lenb;++i){
while(j>0 && B[i]!=B[j+1]) j=next[j];
if(B[i]==B[j+1]) j++;
next[i]=j;
}
s.push(0);//这是为了防止把元素全弹出去后 j=s.top() 操作导致 RE
for(int i=1,j=0;i<=lena;++i){
while(j>0 && A[i]!=B[j+1]) j=next[j];
if(A[i]==B[j+1]) j++;
f[i]=j;
stk.push(A[i]);
s.push(f[i]);//表示这一位答案的 f 值
//其实为了减小常数应该开结构体存,但是因为懒就用两个同步栈代替了
if(f[i]==lenb){
for(int k=1;k<=lenb;++k)
stk.pop(),s.pop();
j=s.top();//弹完后 j 更新为栈顶元素的 f ,也就是 m 个元素之前的那个 f 值
}
}
int num=stk.size();
for(int i=1;i<=num;i++){
ans[i]=stk.top();
stk.pop();
}
for(int i=num;i>=1;--i)
putchar(ans[i]);
}
signed main(){
scanf("%s%s",A+1,B+1);
lena=std::strlen(A+1);
lenb=std::strlen(B+1);
kmp();
return 0;
}
题目链接:Link
题目描述:
给定一个长度为 \(N\) 的字符串 \(A\) ,若一个非 \(A\) 本身的串 \(Q\) 是 \(A\) 的前缀,且 \(A\) 是 \(Q+Q\) 的前缀,则称 \(Q\) 是 \(A\) 的周期( \(Q\) 可以为空),求 \(A\) 的所有前缀的最大周期串长度之和。
Solution:
对于长度为 \(i\) 的串,要满足的条件 \(A_1\rightarrow A_i\) 是 \(Q+Q\) 的前缀。想要满足这个条件,\(next_i\) 必须大于 0 。( \(next_i\) 的另一个定义是:模式串长度为 \(i\) 的前缀,其前缀和后缀相等的最长长度。这个性质可以简单地根据 KMP 的原理得出,这里不再赘述。)
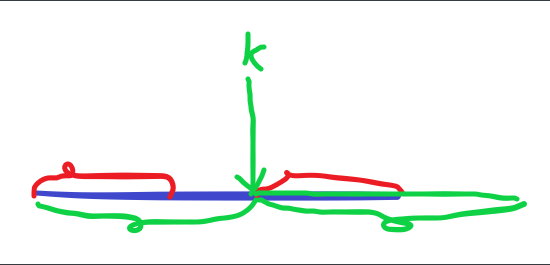
假设蓝色为模式串长度为 \(i\) 的前缀,红色为 \(next_i\) ,如果从前后缀第一个不相等的位置截为 \(Q\) (绿色),那么把 \(Q‘\) 拼在后面正好可以让红色的部分重合,而且使得 \(Q\) 的长度最长。
另外还有一个条件,显然 \(Q\) 的长度至少为 \(\frac i 2\) 。
既然要使得 \(Q\) 的长度最长,那么势必要让 \(next_i\) (红色)部分最短。不巧的是,KMP 算法求出的是最大可能的 \(next_i\) 。记得求 \(next\) 数组时的证明吗?\(next_i\) 所有的可能值是 next[i],next[next[i]],next[nxet[next[i]]]... 我们可以递归访问 \(next\) 数组来得到它的最小值 \(p\),此时 \(Q\) 长度最长,为 \(i-p\) 。
但是有这样一个问题,如果这个字符串全都是同一个字符(比如 ‘a‘ ),那么我们每次递归只能向前跳一个字符,这样导致每找一次长度为 \(i\) 的前缀的“周期”就要递归 \(i-1\) 次,这样总复杂度退化到 \(O(n^2)\) 。
要解决这个问题,就得防止递归次数退化。我联想到了并查集的路径压缩方法,并查集的做法是:在查询到 \(x\) 的父亲时顺便把 \(x\) 及其子树直接挂到它父亲的下面。那么我们为什么不在查询到 \(next_i\) 时直接把它修改为最小值呢?
优化以后,时间复杂度 \(O(n)\) 。
Code:
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<iostream>
//using namespace std;
const int maxn=1000005;
char str[maxn];
int n;
long long ans;//第一次交不开long long见了祖宗
int next[maxn];
void kmp(){
next[1]=0;
for(int i=2,j=0;i<=n;++i){
while(j>0 && str[i]!=str[j+1]) j=next[j];
if(str[i]==str[j+1]) j++;
next[i]=j;
}
for(int i=2,j=2;i<=n;++i,j=i){
while(next[j]) j=next[j];//找最小的next[i]的可能值
if(next[i]) next[i]=j;//类似路径压缩
ans+=i-j;//更新答案
}
printf("%lld\n",ans);
}
signed main(){
//freopen("P3435_13.in","r",stdin);
scanf("%d",&n);
scanf("%s",str+1);
kmp();
return 0;
}
这个题我想了一下午,然而并没有想出怎么优化 \(O(Tn^2)\) 的复杂度到 \(O(Tn)\) ,于是口胡了一个 \(O(Tnlogn)\) 的做法。
吸氧 之后以最慢点 537ms 草过去了(\(nlogn\) 还是快啊)。
题目链接:Link
题目描述:
给定一个长度为 \(N\) 的字符串 \(A\) ,求出 \(num\) 数组。其中 \(num_i\) 表示 \(A\) 的长度为 \(i\) 的前缀 \(P\),满足既是 \(P\) 的前缀又是 \(P\) 的后缀,且长度 \(k\leq \frac i 2\) 的子串 \(Q\) 的个数。
为了避免大量输出,只要求输出:\(\prod\limits_{i=1}^Nnum_i+1 \bmod 1e9+7\) 的值。
Solution:
在叙述解法之前,想问读者一个问题:
显然,\(next\) 数组是一棵以 0 为根的带权树。想想吧,不管我们从哪里开始递归访问,总能访问到 \(next_i=0\) 。
除此之外,\(next\) 树还有一个十分重要的性质:对于每棵非空子树,根节点权值一定小于子节点权值——这是 \(next\) 数组的定义导致的。根据 \(next\) 的定义,不难发现:\(next_i<i\) ,故每个节点的父节点权值一定小于子节点权值。
回到本题,先 KMP 预处理出 \(next\) 数组。很显然,对于每一个 \(i\) ,它的 \(next_i\) 就表示可能的 \(Q\) 的长度(参考 T4 中给出的 \(next\) 数组的另一个定义)。我们不断的递归访问其 \(next\) ,如果这个 \(next\) 值小于 \(\frac i 2\) ,那么说明这个 \(next\) 代表一个合法的 \(Q\) 串,不断递归操作,直到访问到 0 为止,就找出了对于 \(i\) 的所有的合法的 \(Q\) 串。
但是,还是 T4 中的问题,这样做会被全是相同字符的数据把复杂度卡到 \(O(n^2)\) 。
考虑优化:对于每个 \(i\) ,其 \(next\) 的访问顺序都是一条权值单调递增的带权链(第 \(i\) 个节点的权值是 \(next_i\))。这样可以使用 ST 算法在 \(logn\) 的时间内查询权值小于 \(k\) 的第一个节点位置。利用这个性质可以查询权值小于 \(\frac i 2\) 的第一个节点 \(v\),那么 \(v\) 前面的节点权值必然小于 \(\frac i 2\) ,也就是说,\(\forall i\in[1,v],next_i=Q\) ,且这些 \(Q\) 都合法。要统计答案的话,再从 \(v\) 出发,倍增找出它前面有多少个节点,计入答案就行了。
另外,实际操作的时候要把这 \(n\) 条链建成一棵树,不然开不下那么大的空间,预处理也会超时的。
Code:
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<iostream>
//using namespace std;
#define ll long long
#define mod 1000000007
const int maxn=1000005;
int N,n;
char str[maxn];
int next[maxn];
int f[20][maxn];
//f[i][j] 表示 j的2^i 祖先,量小的做第一维,空间连续性更强,会更快!
//2^20=1.4e6 卡满常数,否则可能TLE
ll sum=1;
void kmp(){
next[1]=0;
for(int i=2,j=0;i<=n;++i){
while(j && str[i]!=str[j+1]) j=next[j];
if(str[i]==str[j+1]) j++;
next[i]=j;
f[0][i]=j;
}
for(int i=1;i<20;++i)
for(int j=1;j<=n;++j)
f[i][j]=f[i-1][f[i-1][j]];
sum=1;
for(int i=2;i<=n;++i){
int p=i;
for(int j=19;j>=0;--j)
if(f[j][p]*2>i) //现在的 p 不合法
p=f[j][p];//跳到 p 的 2^j 祖先
ll tot=0;
for(int j=19;j>=0;--j)
if(f[j][p])
tot+=1<<j,p=f[j][p];//这一蹦,蹦过了 2^j 个节点,也就是有 2^j 个合法方案
sum=sum*(tot+1)%mod;//统计答案
}
printf("%lld\n",sum);
}
signed main(){
scanf("%d",&N);
while(N--){
scanf("%s",str+1);
n=std::strlen(str+1);
kmp();
}
return 0;
}
特别鸣谢:
李煜东在《算法竞赛进阶指南》中和 二gou子(徐队) 提供的 KMP 好题。
标签:++i space log 长度 mis 串匹配 为什么 影响 targe
原文地址:https://www.cnblogs.com/zaza-zt/p/14964912.html