标签:space commit acea standard 更新 文本过滤 ace 需要 并且
ES官网:www.elastic.co
ES可视化工具:ElasticHD
快速学习文档:https://learnku.com/docs/elasticsearch73
概念扫盲:https://juejin.cn/post/6844904051994263559;https://juejin.cn/post/6844903894342959117
Elasticsearch是专门做搜索的
安装问题:JDK版本有问题的时候,使用elasticSerach中自带的JDK,修改env.bat中有关JDK部分的命令
概念:
Elasticsearch 是一个分布式文档储存中间件,它不会将信息储存为列数据行,而是储存已序列化为 JSON 文档的复杂数据结构。当你在一个集群中有多个节点时,储存的文档分布在整个集群里面,并且立刻可以从任意节点去访问。
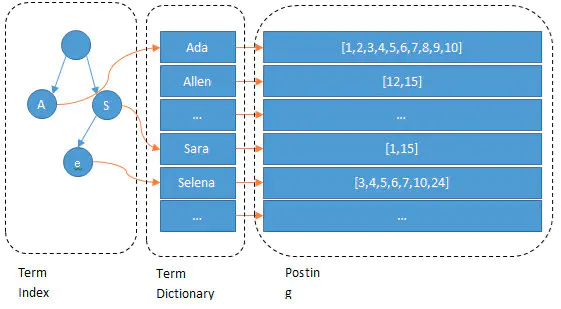
使用倒序索引的数据结构来作为ES的基础。文本字段在倒排索引里,数值和地理字段被储存在 BKD 树中。
Elasticsearch 具备默认模式的能力,这意味着文档建立索引的时候无需明确指定每个字段的数据类型。当启用动态映射时,Elasticsearch 自动检测并将新字段添加到索引。该默认行为使索引和浏览数据变得容易,只要文档开始建立索引, Elasticsearch 就会检测布尔值,浮点数和整数值,日期和字符串,并将其映射到对应的数据类型中。Elasticsearch 提供了一个简单、连贯的REST API用于管理集群、索引和搜索数据。
实际上,Elasticsearch 索引只是一个或多个物理碎片的逻辑分组,其中每个碎片都是一个独立的索引。通过将索引中的文档分布在多个碎片上,并将这些碎片分布到多个节点上,Elasticsearch 就可以实现冗余功能,这即可以防止硬件故障,又可以在添加节点到集群时,增加查询能力。随着集群的增长(或收缩),Elasticsearch 会自动迁移碎片以重新平衡集群。
分片有两种类型:主分片和副本分片。索引中的每个文档都有一个主分片,副本分片是主分片的副本,副本分片可提供数据的冗余副本,以防止硬件故障并增加处理读取请求(如搜索或检索文档)的能力。创建索引时,索引中主分片的数量是固定的,但副本分片数是随时可更改的,其更改操作不会中断索引或者查询。
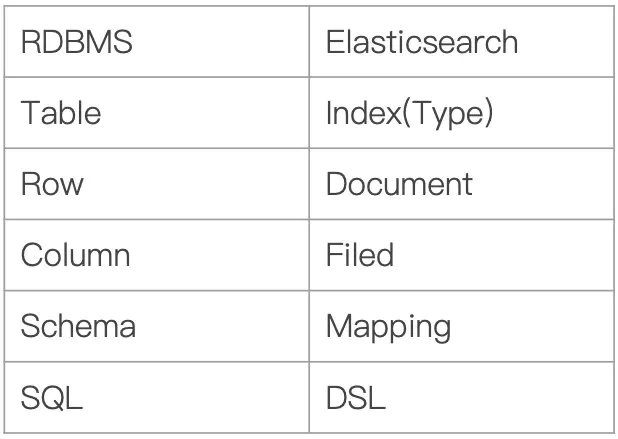
对比关系型数据库
映射:
2.动态映射:字段和属性不需要预先事先定义。在你添加文档的时候,就会自动添加到索引,这个过程不需要事先在索引进行字段数据类型匹配之类,他会自己推断数据类型,动态映射是可以配置的。
3.显示映射:显示映射需要我们在索引映射中进行预先定义
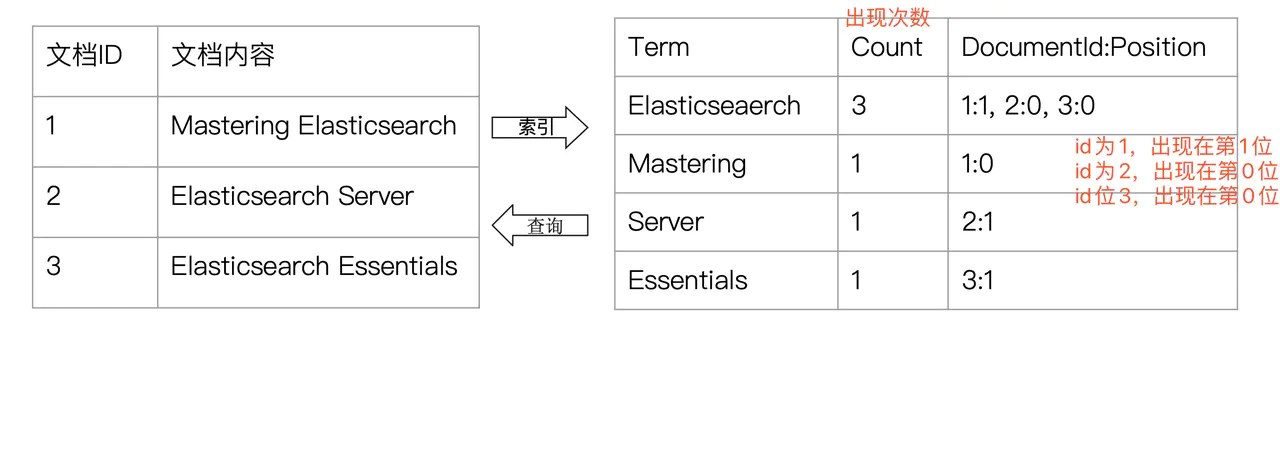
索引:
1.从非结构化数据中提取出的然后重新组织的信息,我们称之索引。这种方式的主要工作量在前期索引的创建,但是对于后期搜索却是快速高效的。
2.正向索引:例如书本,通过章节就可以获取到对应的内容
3.倒排索引:例如书本的章节里面的关键字,可以知道对应在哪些章里面,知道大概的页数
分词器:
ES内置了一些分词器,Standard Analyzer 。按词切分,将词小写,Simple Analyzer。按非字母过滤(符号被过滤掉),将词小写,WhitespaceAnalyzer。按照空格切分,不转小写。
组成:文本过滤器,规则切分,分词后进行处理
写入:
简单过程:客户端写入一条数据,到Elasticsearch集群里边就是由节点来处理这次请求,集群上的每个节点都是coordinating node(协调节点),协调节点表明这个节点可以做路由。比如节点1接收到了请求,但发现这个请求的数据应该是由节点2处理(因为主分片在节点2上),所以会把请求转发到节点2上(找到具体的需要处理的分片)
flush index到磁盘中。更新和删除:
给对应的doc记录打上.del标识,如果是删除操作就打上delete状态,如果是更新操作就把原来的doc标志为delete,然后重新新写入一条数据。
前面提到了,每隔1s会生成一个segement 文件,那segement文件会越来越多越来越多。Elasticsearch会有一个merge任务,会将多个segement文件合并成一个segement文件。在合并的过程中,会把带有delete状态的doc给物理删除掉。
查询:
标签:space commit acea standard 更新 文本过滤 ace 需要 并且
原文地址:https://www.cnblogs.com/SmartCat994/p/15055387.html