标签:c style class blog code java
声明:
1)本文由我bitpeach原创撰写,转载时请注明出处,侵权必究。
2)本小实验工作环境为Windows系统下的百度云(联网),和Ubuntu系统的hadoop1-2-1(自己提前配好)。如不清楚配置可看《Hadoop之词频统计小实验初步配置》
3)本文由于过长,无法一次性上传。其相邻相关的博文,可参见《Hadoop的改进实验(中文分词词频统计及英文词频统计) 博文目录结构》,以阅览其余三篇剩余内容文档。
背景:中文TXT文本在Windows可以读取,因为Windows编码库注册编辑表完备缘故。有时候TXT文本在Ubuntu下可能无法正常,原因是编码问题。可是Ubuntu的编码配置我也配置过,貌似还是有问题,现在重新解决这个问题。
临时命令打开的方法:用gedit -h看一下可以知道gedit命令参数里面有一个选项是encoding,在终端中运行gedit –encoding=gbk filename,这时打开文件看到的中文就不是乱码了。
先打开gedit,然后在打开文件时,在Character Coding下拉菜单里选择GBK或GB18030就可以了;(我找过了,没有这两个编码,可能是gedit版本问题)
在终端运行gconf-editor,在apps/gedit-2/preference/encodings里面有个auto-detect,在它的前面加上GBK或GB18030就OK了。
值得一提, Ubuntu12.04版本为新版本,无法实现上述方法,低于这个版本可以使用。Ubuntu首先没有gconf-editor,即使使用apt-get install命令安装以后,也找不到apps/gedit的参数。
神操作来了!
#gsettings set org.gnome.gedit.preferences.encodings auto-detected "[‘UTF-8‘,‘GB18030‘,‘GB2312‘,‘GBK‘,‘BIG5‘,‘CURRENT‘,‘UTF-16‘]"
或者小小改动一下,添加Unicode也是可以的。
经验证,适合Ubuntu12.04版本,绝对神操作。原理大概就是相当等效于在Windows建了一个注册表。
背景:我在上面gedit配置过程之后,使用hadoop cat指令读取中文文本,发现读取出来是乱码,说明此乱码现象是hadoop的不识别造成的。究其原因仍然是hadoop的shell继承java,而java默认的编码是UTF8格式。网上有很多解决方法,但是都不实际,也不是特别适用于hadoop的环境条件。这里仅提供一种方便的方法。(下图为统计中文文本时,产生的结果带有乱码。说明一开始的统计文本的编码需要处理。)
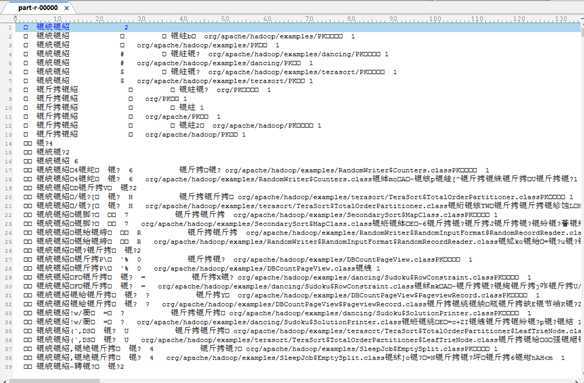
既然我们做的是中文文本实验,那么如果在改变hadoop本身的读取码方式上,非常难以做到(我试了几种方法,都不能从根本上改动),那么我们就改变适应的方式,既然不能改变世界,我们要先改造自己。
思路就是,我们把各类的文本转换成为UTF8格式。值得敬佩的是,ubuntu对此提供了一系列的指令,而且这些指令效率之高,速度之快,令人惊叹。
我们使用incov指令,指令格式如下
iconv -f [encoding] -t [encoding] inputfile
例如,我们要转换某TXT文本,TXT文本原本是GBK,现需要转换至UTF8,指令可以写成如下
iconv -f gbk -t utf8 /路径/*.txt
如果要保存至新的文本里,则指令完整如下
iconv -f gbk -t utf8 /路径/*.txt > newfile_utf8.txt
并且非常值得注意的是,如果出现第某某行读取错误的时候,一般来说是你要转换的文本中间出现了异常的编码,意思就是,当文本内的编码出现多种,iconv可能就会读取错误,因为指令中默认是转换一种编码。其中一种解决办法就是,一般来说,由于文本编码较为纯净一致,出现异常字符的数量较少,我们根据iconv的返回错误行数,找到文本内的对应行,删除掉异常字符既可。除此外仍然有其他应对策略,就是假设文本内有两种编码A与B,我们可以先转换A编码,忽略B编码,然后再忽略A编码转换B编码,最后合起来便可,这类操作因为不常常涉及到,故详细操作不再列出,可自行查询。
那么有一个问题,iconv不支持无源转换,意思就是不支持缺少源编码参数的命令。而有时我们又不知道文本的编码格式怎么办?我们的思路就是利用vim指令。
利用vim指令的前提是vim可以读取文本,并且正常显示,如果连vim都没有正常显示,则不能往下操作,我们为了可以使用vim正常显示,故需要配置vim的编码调用环境。
既可以使用gedit修改vim的环境变量文件,也可以使用vim修改自身的环境变量文件。二者路径如下图所示。
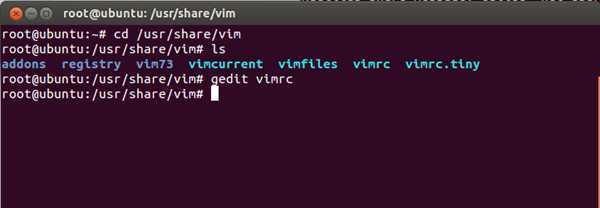

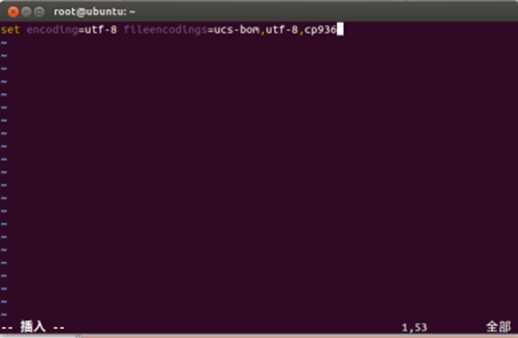
我以vim修改本身环境变量文件为例,通过vim修改本身环境变量文件,并加入一句指令如下:
set encoding=utf-8 fileencodings=ucs-bom,utf-8,cp936
最后按Esc,进入vim shell,输入wq,保存退出。
vim查看文本的编码的原理实际上就是:给vim配置很多种编码库,然后让它自动查询,直至查询到符合条件的编码,然后显示出编码格式。如果vim本身没有此编码库,则也无法返回文本的编码格式,故建议将vim的文本编码调用库配置多一些,加入的调用编码丰富一些,以便查询。
对于gedit修改的话,配置指令内容大概如下(仅供参考):
set fileencodings=utf-8,gb2312,gbk,gb18030
set termencoding=utf-8
set fileformats=unix
set encoding=prc
我们配置好vim,进入下一步操作。
我们使用vim打开所要查询文本编码方式的TXT文本,指令例如如下:
vim /路径/file.txt
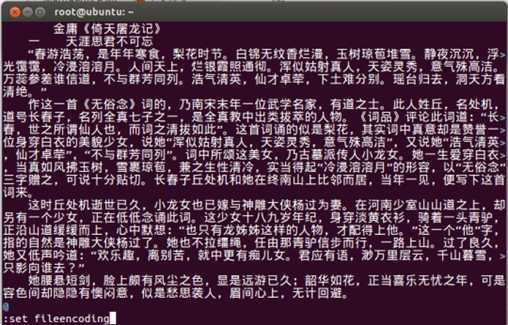
打开文本后,按ESC按键进入vim shell(文本显示的最后一行就是shell输入的地方),然后输入冒号,再输入指令"set fileencoding",回车后vim会自动返回文本编码方式,如下图返回"fileencoding=cp936",实际上cp936就是GBK。
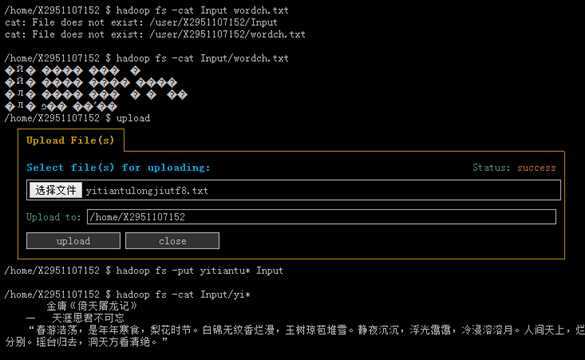
以我为例,我转换的是《倚天屠龙记.txt》,然后使用iconv指令转成utf8格式的文本,命名为《yitiantulongjiutf8.txt》。不论是单机的hadoop,还是百度开放云的hadoop,都可以正常显示读取,如下图所示。
值得一提是,下图为百度开放云的hadoop平台,从图中也可以看到我想显示另一个中文文本《wordch.txt》,编码GBK,结果输出是乱码。而输出utf8格式的倚天屠龙记文本,则可以正常显示。(由于全部显示太多,我只转换了倚天屠龙记的第一个段落。)
本实验不方便在百度开放云上操作,但可以在本机Ubuntu上操作。
我们采用传统的java程序模式,进行中文文本的词频统计。
采取的分词策略来源于IKAnalyzer开源中文分词工具,其提供的lib库使用"正向迭代最细粒度切分算法"进行中文分词与词频统计。
MapReduce下的API允许非Java语言来编写map和reduce函数。这就是hadoop的streaming模式,我们可以使用Python语言编写脚本,然后使用streaming模式接口,运行中文分词统计词频程序
Hadoop的改进实验(中文分词词频统计及英文词频统计)(2/4),布布扣,bubuko.com
Hadoop的改进实验(中文分词词频统计及英文词频统计)(2/4)
标签:c style class blog code java
原文地址:http://www.cnblogs.com/bitpeach/p/3756164.html