标签:style blog class code java tar
UNIX 中提供了许多 指令 和 tools,它们具有在文件中 查找(Search)字串或替换(Replace)字串 的功能。像 grep, vi , sed, awk,...
不论是查找字串或替换字串,都得先告诉这些指令所要查找(被替换)的字串为何。若未能预先明确知道所要查找(被替换)的字串为何,只知该字串存在的范围或特征时,例如:
(一)查找 "T0.c", "T1.c", "T2.c".... "T9.c" 当中的任一字串。
(二)查找至少存在一个 "A"的任意字串。
这情況下,如何告知执行查找字串的指令所要查找的字串为何。
例 (一) 中,要查找任一在 "T" 与 ".c" 之间存在一个阿拉伯数字的字串,当然您可以列举的方式,一一把所要查找的字串告诉执行命令的指令。但例 (二) 中合乎该条件的字串有无限种可能,势必无法一一列举。此时,便需要另一种字串表示的方法(协定)。
正则表达式(以下简称 Regexp)是一种字串表达的方式。可用以指定具有某特征的所有字串。
注:为区別于一般字串,本附录中代表 Regexp 的字串之前皆加 "Regexp"。
注:awk 程序中常以 /..../ 括住 Regexp,以区別于一般字串。
普通字符:除了 . * [ ] + ? ( ) \ ^ $ 外的所有字符。
由普通字符所组成的Regexp其意义与原字串字面意义相同。
例如:Regexp "the" 与一般字串的 "the" 代表相同的意义。
. (Meta character):用以代表任意一字符。
须留心 UNIX Shell 中使用 "*"表示 Wild card(通配符),可用以代表任意长度的字串。而 Regexp 中使用 "." 来代表一个任意字符(注意:并非任意长度的字串)。Regexp 中 "*" 另有其它涵意,并不代表任意长度的字串。
^ 表示该字串必须出现于行首。
$ 表示该字串必须出现于行末。
例如:
Regexp /^The/ 用以表示所有 "The"出现于行首 的字串 。
Regexp /The$/ 用以表示所有 "The"出现于行末 的字串。
\ 将特殊字符还原成字面意义的字符(Escape character)。
Regexp 中特殊字符将被解释成特定的意义,若要表示特殊字符的字面(literal meaning)意义时,在特殊字符之前加上"\"即可。
例如:
使用Regexp来表示字串 "a.out"时,不可写成 /a.out/。因为 "."是特殊字符,表示任一字符。可符合 Regexp / a.out/ 的字串将不只 "a.out" 一个;字串 "a2out"、"a3out"、"aaout" ...都符合 Regexp /a.out/ 。正确的用法为:/ a\.out/
[...] 字符集合,用以表示两中括号间所有的字符当中的任一个。
例如:
Regexp /[Tt]/ 可用以表示字符 "T" 或 "t"。故 Regexp /[Tt]he/ 表示 字串 "The" 或 "the"。字符集合 [...] 内不可随意留空白。
例如:
Regexp /[ Tt ]/ 其中括号内有空白字符,除表示"T"、"t" 中任一个字符,也可代表一个 " "(空白字符)。
- 字符集合中可使用 "-" 来指定字符的区间。
例如:
Regexp /[0-9]/ 等于 /[0123456789]/ ,用以表示任意一个阿拉伯数字。
同理 Regexp /[A-Z]/ 用以表示任意一个大写英文字母。
但应留心:
Regexp /[0-9a-z]/ 并不等于 /[0-9][a-z]/ ;前者表示一个字符,后者表示两个字符。
Regexp /[-9]/ 或 /[9-]/ 只代表字符 "9"或 "-"。
[^...] 使用[^..] 产生字符集合[..]的补集(complement set)。
例如:
要指定 "T" 或 "t" 之外的任一个字符,可用 /[^Tt]/ 表示。
同理 Regexp /[^a-zA-Z]/ 表示英文字母之外的任一个字符。
须留心:
"^" 的位置:"^"必须紧接於"["之后,才代表字符集合的补集。
例如:
Regexp /[0-9\^]/ 只是用以表示一个阿拉伯数字或字符"^"。
* 形容字符重复次数的特殊字符。"*" 形容它前方的字符可以不出现,也可以出现 1 次或多次。
例如:
Regexp /T[0-9]*\.c/ 中 * 形容其前 [0-9] (一个阿拉伯数字)出现的次数可为 0次或 多次,故Regexp /T[0-9]*\.c/ 可用以表示"T.c"、"T0.c"、"T1.c"、...、"T19.c"。
+ 形容其前的字符出现一次或一次以上。
例如:
Regexp /[0-9]+/ 用以表示一位或一位以上的数字。
? 形容其前的字符可出现一次或不出现。
例如:
Regexp /[+-]?[0-9]+/ 表示数字(一位以上)之前可出现正负号或不出现正负号。
(...) 用以括住一群字符,且将之视成一个group(见下面说明)。
例如:
Regexp /12+/ 表示字串 "12", "122", "1222", "12222",...
Regexp /(12)+/ 表示字串 "12", "1212", "121212", "12121212"....
上式中 12 以( )括住,故 "+" 所形容的是 12,重复出现的也是 12。
| 表示逻辑上的"或"(or)
例如:
Regexp / Oranges? | apples? | water/ 可用以表示:字串 "Orange", "Oranges" 或 "apple", "apples" 或 "water"
讨论 Regexp 时,经常遇到 "某字串匹配( match )某 Regexp"的字眼。其意思为:"这个 Regexp 可被解释成该字串"。
例如:
字串 "the" 匹配(match) Regexp /[Tt]he/。
因为 Regexp /[Tt]he/ 可解释成字串 "the" 或 "The",故字串 "the" 或 "The"都匹配(match) Regexp /[Th]he/。
它们也称之为 match、not match。但函义与一般常称的 match 略有不同。
其定义如下:
A 表示一字串,B 表示一 Regular Expression
只要 A 字串中存在有子字串可 match( 一般定义的 match) Regexp B,则 A ~ B 就算成立,其值为 true,反之则为 false。
! ~ 的定义与 ~ 恰好相反。
例如:
"another" 中含有子字串 "the" 可 match Regexp /[Tt]he/ ,所以 "another" ~ /[Tt]he/ 的值为 true。
注一:有些论著不把这两个运算符( ~, !~)与 Relational Operators 归为一类。
下面列出一些应用 Regular Expression 的简例,部分范例中会更改$0 的值,若您使用的 awk不允许用户更改 $0时 请改用 gawk。
例1:
将文件中所有的字串 "Regular Expression" 或 "Regular expression" 换成 "Regexp"

awk ‘
{
gsub( /Regular[ \t]+[Ee]xpression/, "Regexp")
print
}
‘ $*
例2:
去除文件中的空白行(或仅含空白字符或tab的行)
awk ‘
$0 !~ /^[ \t]*$/ { print }
‘ $*
例3:
在文件中具有 ddd-dddd (电话号码型态,d 表示digital)的字串前加上"TEL : "
awk ‘
{
gsub( /[0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]/, "TEL : &" )
print
}
‘ $*
例4:
从文件的 Fullname 中分离出 路径 与 文件名
awk ‘
BEGIN{
Fullname = "/usr/local/bin/xdvi"
match( Fullname, /.*\//)
path = substr(Fullname, 1, RLENGTH-1)
name = substr(Fullname, RLENGTH+1)
print "path :", path," name :",name
}
‘ $*
结果打印:
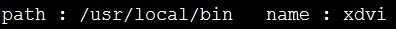
例5:
将某一数值改以现金表示法表示(整数部分每三位加一撇,且含二位小数)
awk ‘
BEGIN {
Number = 123456789
Number = sprintf("$%.2f",Number)
while( match(Number,/[0-9][0-9][0-9][0-9]/ ) )
sub(/[0-9][0-9][0-9][.,]/, ",&", Number)
print Number
}
‘ $*
结果输出

例6:
把文件中所有具 "program数字.f"形态的字串改为"[Ref : program数字.c]"
awk ‘
{
while( match( $0, /program[0-9]+\.f/ ) ){
Replace = "[Ref : " substr( $0, RSTART, RLENGTH-2) ".c]"
sub( /program[0-9]+\.f/, Replace)
}
print
}
‘ $*
【译】 AWK教程指南 附录E-正则表达式,布布扣,bubuko.com
标签:style blog class code java tar
原文地址:http://www.cnblogs.com/qieerbushejinshikelou/p/3705569.html