标签:分析 color com use 节点 rtu body 代码结构 sum
SupportYun当前状况:
博主的SupportYun系统基本已经完成第一阶段预期的底层服务开发啦~~~自己小嘚瑟一下。
有对该系统历史背景与功能等不明白的可先看该系列的第1/2篇文章:
2.记一次企业级爬虫系统升级改造(二):基于AngleSharp实现的抓取服务
再贴一次博主对这个系统的简要整体规划图:
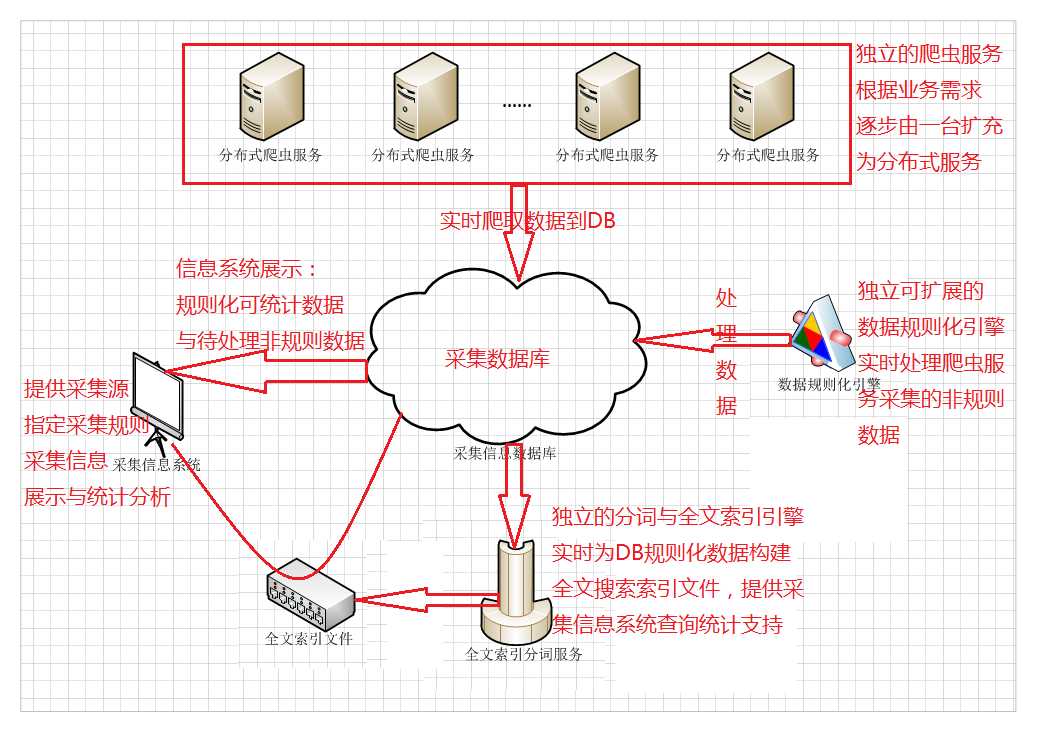
博主第一阶段主要会做独立的爬虫服务+数据规则化引擎以及内容归类处理这一块。
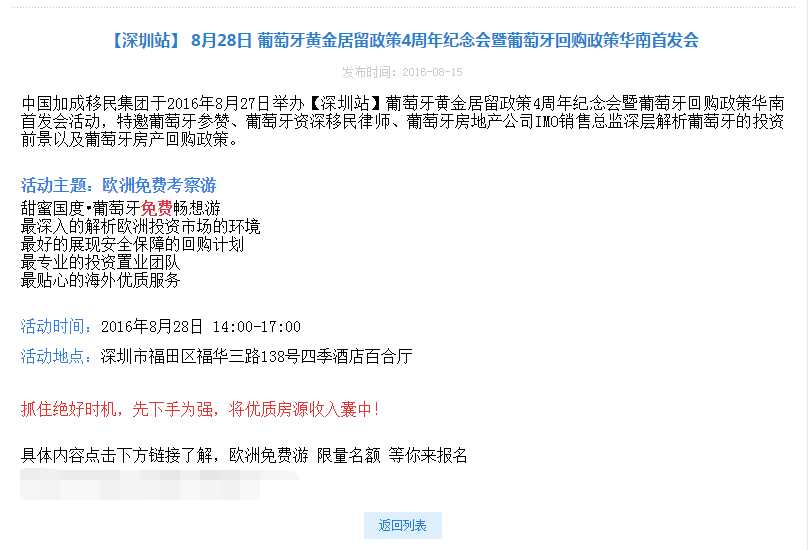
再简单粗暴一点就是把大量类似下图的网页抓取,然后分析数据,得到活动城市、活动地址、热线、活动日期、活动分类以及内容纯文本的数据提供给业务部门。
本篇文章将主要讲博主是怎么在抓取到网页数据后做通用数据规则处理的。
先来看看当前的项目代码结构图:
不错,你没有看错,短短三周时间,博主一个人已经写了这么多代码了~~想想手都累啊!心也累~
其实,每一天的生活状态,就决定了五年甚至十年后的状态,日子是一天一天过的,积累的多了,就是一生。
唯美的偶遇:JieBa.Net
博主首先想实现的一个功能是,分析文章或活动文本的内容语义,将其按我们设定的几大模块分类。
具体怎么从抓取的html片段中提取纯文本,博主将在下面讲到。
比如说这么一篇文章:为什么美国精英中学距离中国孩子越来越远?
我们一读或者只看title,基本就能确定,它应该属于【海外教育】这个大类,当然,也可以牵强的给他一个【海外生活】的标签。这是我们人工很容易处理的逻辑。那么要是爬取到大量的这种网页数据,我们的代码应该怎么准确的来进行归类处理呢?
来看看博主的多番思考后的最终实现方案:
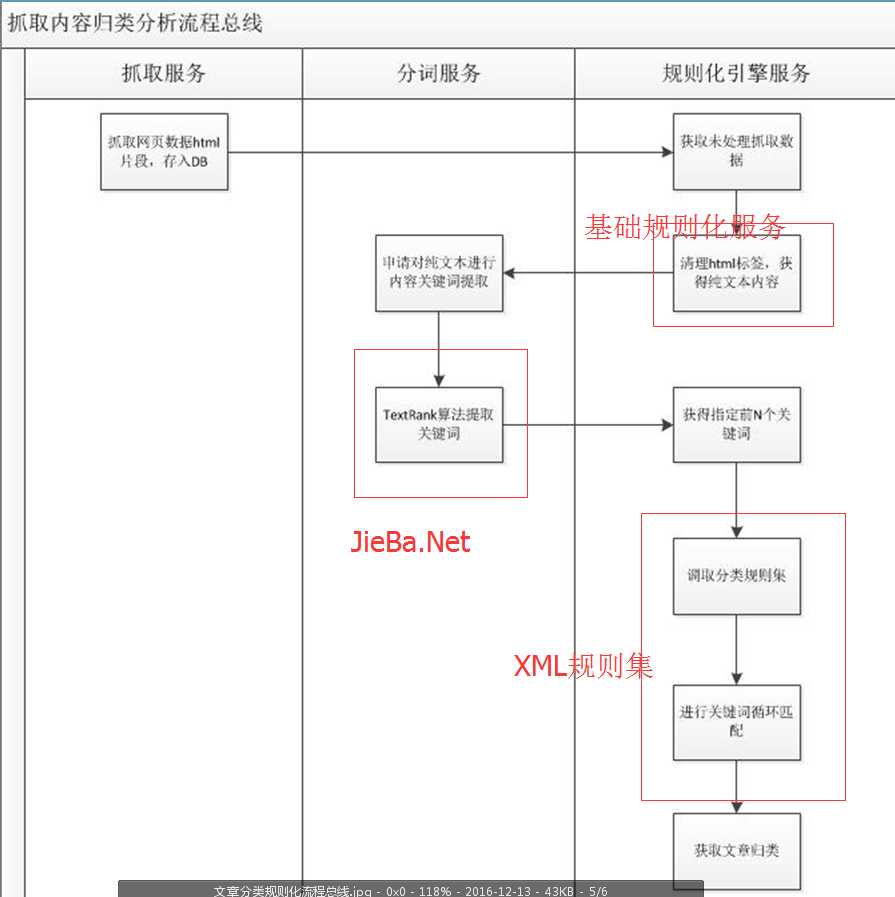
1.基础规则化服务涉及到数据清理等内容,后面介绍。
2.xml规则集是楼主找业务部门以及自己整理的一个数据集,存储各大类别的主要热门、经典关键词。
3.关键词提取算法,这儿博主分析了TF-IDF算法与TextRank算法,最终采用的TextRank算法,基于JieBa.Net实现。
先来说说为什么要是用JieBa分词吧。
博主的下一阶段就会涉及到全文索引,必然会引用分词技术,以前都是轻车熟路的使用Lucene.Net+盘古分词,代码都不用多写...毕竟存货多多!
早说了,这一次打算吃点素的,不能老啃老本...我们是软件工程师,不是码农!!!
鬼使神差的就搜到了JieBa.Net,还发现几个bug,提了GitHub...说来也是心累,但是作者开源也是多辛苦的,得多多支持!
由于当时作者不能及时的更新NuGet上的包,所以自己本机改了一些就开始用了。
1 /// <summary> 2 /// 关键词提取 3 /// </summary> 4 public class KeyWordExtractor 5 { 6 /// <summary> 7 /// TF-IDF算法 关键词提取 8 /// </summary> 9 /// <returns></returns> 10 public List<string> TFIDFExtractor(string content, int count = 10) 11 { 12 var extractor = new TFIDFKeywordExtractor(); 13 var keywords = extractor.ExtractTags(content, count, Constants.NounAndVerbPos); 14 return keywords.ToList(); 15 } 16 17 /// <summary> 18 /// TextRank算法 关键词提取 19 /// </summary> 20 /// <returns></returns> 21 public List<string> TextRankExtractor(string content, int count = 10) 22 { 23 var extractor = new TextRankKeywordExtractor(); 24 var keywords = extractor.ExtractTags(content, count, Constants.NounAndVerbPos); 25 return keywords.ToList(); 26 } 27 }
第12与23行本来直接使用JieBa封装的方法就可以的,上面说了由于NuGet未能及时更新,自己把有bug的逻辑实现了一遍:
1 /// <summary> 2 /// TF-IDF算法 关键词提取器 3 /// </summary> 4 public class TFIDFKeywordExtractor : BaseKeywordExtractor 5 { 6 private static readonly string DefaultIdfFile = Path.Combine(ConfigurationManager.AppSettings["JiebaConfigFileDir"] ?? HttpContext.Current.Server.MapPath("/Resources/"), "idf.txt"); 7 private static readonly int DefaultWordCount = 20; 8 9 private JiebaSegmenter Segmenter { get; set; } 10 private PosSegmenter PosSegmenter { get; set; } 11 private IDFLoader Loader { get; set; } 12 13 private IDictionary<string, double> IdfFreq { get; set; } 14 private double MedianIdf { get; set; } 15 16 public TFIDFKeywordExtractor(JiebaSegmenter segmenter = null) 17 { 18 Segmenter = segmenter.IsNull() ? new JiebaSegmenter() : segmenter; 19 PosSegmenter = new PosSegmenter(Segmenter); 20 SetStopWords(StopWordsIdfFile); 21 if (StopWords.IsEmpty()) 22 { 23 StopWords.UnionWith(DefaultStopWords); 24 } 25 26 Loader = new IDFLoader(DefaultIdfFile); 27 IdfFreq = Loader.IdfFreq; 28 MedianIdf = Loader.MedianIdf; 29 } 30 31 public void SetIdfPath(string idfPath) 32 { 33 Loader.SetNewPath(idfPath); 34 IdfFreq = Loader.IdfFreq; 35 MedianIdf = Loader.MedianIdf; 36 } 37 38 private IEnumerable<string> FilterCutByPos(string text, IEnumerable<string> allowPos) 39 { 40 var posTags = PosSegmenter.Cut(text).Where(p => allowPos.Contains(p.Flag)); 41 return posTags.Select(p => p.Word); 42 } 43 44 private IDictionary<string, double> GetWordIfidf(string text, IEnumerable<string> allowPos) 45 { 46 IEnumerable<string> words = null; 47 if (allowPos.IsNotEmpty()) 48 { 49 words = FilterCutByPos(text, allowPos); 50 } 51 else 52 { 53 words = Segmenter.Cut(text); 54 } 55 56 var freq = new Dictionary<string, double>(); 57 foreach (var word in words) 58 { 59 var w = word; 60 if (string.IsNullOrEmpty(w) || w.Trim().Length < 2 || StopWords.Contains(w.ToLower())) 61 { 62 continue; 63 } 64 freq[w] = freq.GetDefault(w, 0.0) + 1.0; 65 } 66 var total = freq.Values.Sum(); 67 foreach (var k in freq.Keys.ToList()) 68 { 69 freq[k] *= IdfFreq.GetDefault(k, MedianIdf) / total; 70 } 71 72 return freq; 73 } 74 75 public override IEnumerable<string> ExtractTags(string text, int count = 20, IEnumerable<string> allowPos = null) 76 { 77 if (count <= 0) { count = DefaultWordCount; } 78 79 var freq = GetWordIfidf(text, allowPos); 80 return freq.OrderByDescending(p => p.Value).Select(p => p.Key).Take(count); 81 } 82 83 public override IEnumerable<WordWeightPair> ExtractTagsWithWeight(string text, int count = 20, IEnumerable<string> allowPos = null) 84 { 85 if (count <= 0) { count = DefaultWordCount; } 86 87 var freq = GetWordIfidf(text, allowPos); 88 return freq.OrderByDescending(p => p.Value).Select(p => new WordWeightPair() 89 { 90 Word = p.Key, 91 Weight = p.Value 92 }).Take(count); 93 } 94 }
1 /// <summary> 2 /// TextRank算法 关键词提取器 3 /// </summary> 4 public class TextRankKeywordExtractor : BaseKeywordExtractor 5 { 6 private static readonly IEnumerable<string> DefaultPosFilter = new List<string>() 7 { 8 "n", "ng", "nr", "nrfg", "nrt", "ns", "nt", "nz", "v", "vd", "vg", "vi", "vn", "vq" 9 }; 10 11 private JiebaSegmenter Segmenter { get; set; } 12 private PosSegmenter PosSegmenter { get; set; } 13 14 public int Span { get; set; } 15 16 public bool PairFilter(Pair wp) 17 { 18 return DefaultPosFilter.Contains(wp.Flag) 19 && wp.Word.Trim().Length >= 2 20 && !StopWords.Contains(wp.Word.ToLower()); 21 } 22 23 public TextRankKeywordExtractor() 24 { 25 Span = 5; 26 27 Segmenter = new JiebaSegmenter(); 28 PosSegmenter = new PosSegmenter(Segmenter); 29 SetStopWords(StopWordsIdfFile); 30 if (StopWords.IsEmpty()) 31 { 32 StopWords.UnionWith(DefaultStopWords); 33 } 34 } 35 36 public override IEnumerable<string> ExtractTags(string text, int count = 20, IEnumerable<string> allowPos = null) 37 { 38 var rank = ExtractTagRank(text, allowPos); 39 if (count <= 0) { count = 20; } 40 return rank.OrderByDescending(p => p.Value).Select(p => p.Key).Take(count); 41 } 42 43 public override IEnumerable<WordWeightPair> ExtractTagsWithWeight(string text, int count = 20, IEnumerable<string> allowPos = null) 44 { 45 var rank = ExtractTagRank(text, allowPos); 46 if (count <= 0) { count = 20; } 47 return rank.OrderByDescending(p => p.Value).Select(p => new WordWeightPair() 48 { 49 Word = p.Key, Weight = p.Value 50 }).Take(count); 51 } 52 53 #region Private Helpers 54 55 private IDictionary<string, double> ExtractTagRank(string text, IEnumerable<string> allowPos) 56 { 57 if (allowPos.IsEmpty()) 58 { 59 allowPos = DefaultPosFilter; 60 } 61 62 var g = new UndirectWeightedGraph(); 63 var cm = new Dictionary<string, int>(); 64 var words = PosSegmenter.Cut(text).ToList(); 65 66 for (var i = 0; i < words.Count(); i++) 67 { 68 var wp = words[i]; 69 if (PairFilter(wp)) 70 { 71 for (var j = i + 1; j < i + Span; j++) 72 { 73 if (j >= words.Count) 74 { 75 break; 76 } 77 if (!PairFilter(words[j])) 78 { 79 continue; 80 } 81 82 var key = wp.Word + "$" + words[j].Word; 83 if (!cm.ContainsKey(key)) 84 { 85 cm[key] = 0; 86 } 87 cm[key] += 1; 88 } 89 } 90 } 91 92 foreach (var p in cm) 93 { 94 var terms = p.Key.Split(‘$‘); 95 g.AddEdge(terms[0], terms[1], p.Value); 96 } 97 98 return g.Rank(); 99 } 100 101 #endregion 102 }
1 /// <summary> 2 /// 关键词提取器基类 3 /// 基于JieBa分词 4 /// </summary> 5 public abstract class BaseKeywordExtractor 6 { 7 protected static readonly string StopWordsIdfFile = Path.Combine(ConfigurationManager.AppSettings["JiebaConfigFileDir"] ?? HttpContext.Current.Server.MapPath("/Resources/"), "stopwords.txt"); 8 9 protected static readonly List<string> DefaultStopWords = new List<string>() 10 { 11 "the", "of", "is", "and", "to", "in", "that", "we", "for", "an", "are", 12 "by", "be", "as", "on", "with", "can", "if", "from", "which", "you", "it", 13 "this", "then", "at", "have", "all", "not", "one", "has", "or", "that" 14 }; 15 16 protected virtual ISet<string> StopWords { get; set; } 17 18 public void SetStopWords(string stopWordsFile) 19 { 20 StopWords = new HashSet<string>(); 21 var path = Path.GetFullPath(stopWordsFile); 22 if (File.Exists(path)) 23 { 24 var lines = File.ReadAllLines(path); 25 foreach (var line in lines) 26 { 27 StopWords.Add(line.Trim()); 28 } 29 } 30 } 31 32 public abstract IEnumerable<string> ExtractTags(string text, int count = 20, IEnumerable<string> allowPos = null); 33 public abstract IEnumerable<WordWeightPair> ExtractTagsWithWeight(string text, int count = 20, IEnumerable<string> allowPos = null); 34 }
绝大部分都是JieBa.NET的源码,大家也可以去github支持一下作者~~~
作为一枚北漂,如果要选择平平淡淡的生活,确实不如早点回老家谋求一份稳定的饭碗,还能常伴家人左右。
细说数据规则化引擎服务:
1.创建一个windows服务,设置5分钟自动轮询启动执行数据规则化引擎。
1 public partial class Service1 : ServiceBase 2 { 3 private RuleEngineService.RuleEngineService ruleEngineService = new RuleEngineService.RuleEngineService(); 4 5 public Service1() 6 { 7 InitializeComponent(); 8 } 9 10 protected override void OnStart(string[] args) 11 { 12 try 13 { 14 EventLog.WriteEntry("【Support云数据规则化引擎服务启动】"); 15 CommonTools.WriteLog("【Support云数据规则化引擎服务启动】"); 16 17 XmlConfigurator.Configure(); 18 19 Timer timer = new Timer(); 20 // 循环间隔时间(默认5分钟) 21 timer.Interval = StringHelper.StrToInt(ConfigurationManager.AppSettings["TimerInterval"].ToString(), 300) * 1000; 22 // 允许Timer执行 23 timer.Enabled = true; 24 // 定义回调 25 timer.Elapsed += new ElapsedEventHandler(TimedTask); 26 // 定义多次循环 27 timer.AutoReset = true; 28 } 29 catch (Exception ex) 30 { 31 CommonTools.WriteLog("【服务运行 OnStart:Error" + ex + "】"); 32 } 33 } 34 35 private void TimedTask(object source, ElapsedEventArgs e) 36 { 37 System.Threading.ThreadPool.QueueUserWorkItem(delegate 38 { 39 ruleEngineService.Main(); 40 }); 41 } 42 43 protected override void OnStop() 44 { 45 CommonTools.WriteLog(("【Support云数据规则化引擎服务停止】")); 46 EventLog.WriteEntry("【Support云数据规则化引擎服务停止】"); 47 } 48 }
具体部署方案不多说,很多园友都有发相关文章。
2.数据规则化解析服务引擎RuleEngineService,主要是分类别(文章、活动)判断是否有未处理数据,如有则调取相应服务开始处理。
1 /// <summary> 2 /// 数据规则化解析服务引擎 3 /// </summary> 4 public class RuleEngineService 5 { 6 private readonly ArticleRuleEngineService articleRuleEngineService = new ArticleRuleEngineService(); 7 private readonly ActivityRuleEngineService activityRuleEngineService = new ActivityRuleEngineService(); 8 9 public void Main() 10 { 11 try 12 { 13 HandleArticleData(); 14 HandleActivityData(); 15 } 16 catch (Exception ex) 17 { 18 LogUtils.ErrorLog(ex); 19 } 20 } 21 22 /// <summary> 23 /// 处理文章类别数据 24 /// </summary> 25 private void HandleArticleData() 26 { 27 using (var context = new SupportYunDBContext()) 28 { 29 if ( 30 context.CollectionInitialData.Any( 31 t => 32 !t.IsDelete && t.ProcessingProgress != ProcessingProgress.已处理 && 33 t.CollectionType == CollectionType.文章)) 34 { 35 var articleDatas = context.CollectionInitialData.Where( 36 t => 37 !t.IsDelete && t.ProcessingProgress != ProcessingProgress.已处理 && 38 t.CollectionType == CollectionType.文章).ToList(); 39 foreach (var article in articleDatas) 40 { 41 articleRuleEngineService.RuleArticle(article.Id); 42 } 43 } 44 } 45 } 46 47 /// <summary> 48 /// 处理活动类别数据 49 /// </summary> 50 private void HandleActivityData() 51 { 52 using (var context = new SupportYunDBContext()) 53 { 54 if ( 55 context.CollectionInitialData.Any( 56 t => 57 !t.IsDelete && t.ProcessingProgress != ProcessingProgress.已处理 && 58 t.CollectionType == CollectionType.活动)) 59 { 60 var activityDatas = context.CollectionInitialData.Where( 61 t => 62 !t.IsDelete && t.ProcessingProgress != ProcessingProgress.已处理 && 63 t.CollectionType == CollectionType.活动).ToList(); 64 foreach (var activity in activityDatas) 65 { 66 activityRuleEngineService.RuleActivity(activity.Id); 67 } 68 } 69 } 70 } 71 }
3.我们首先来看文章的规则化处理类ArticleRuleEngineService,核心逻辑就是:
a)查询未处理的抓取数据(此时内容还是html片段)
b)清洗内容中的html标签,获得纯文本数据(博主特喜欢xml配置文件的方式,看过博主前面几个系列的都知道,所以博主的方案是:配置一个xml文件,分html常用标签节点、常用分隔符节点、特殊如style/script等不规则节点的枚举正则表达式集合,然后代码获取xml内容,正则表达式一匹配替换,就能得到纯文本数据。如果后期发现有未配置的节点,直接在xml添加就ok,简单又方便)。
1 <?xml version="1.0" encoding="utf-8" ?> 2 <filterStr> 3 <HtmlLabels> 4 <element><![CDATA[&#[^>]*;]]></element> 5 <element><![CDATA[</?marquee[^>]*>]]></element> 6 <element><![CDATA[</?object[^>]*>]]></element> 7 <element><![CDATA[</?param[^>]*>]]></element> 8 <element><![CDATA[</?embed[^>]*>]]></element> 9 <element><![CDATA[</?table[^>]*>]]></element> 10 <element><![CDATA[</?tbody[^>]*>]]></element> 11 <element><![CDATA[</?tr[^>]*>]]></element> 12 <element><![CDATA[</?th[^>]*>]]></element> 13 <element><![CDATA[</?td[^>]*>]]></element> 14 <element><![CDATA[</?h1[^>]*>]]></element> 15 <element><![CDATA[</?h2[^>]*>]]></element> 16 <element><![CDATA[</?h3[^>]*>]]></element> 17 <element><![CDATA[</?h4[^>]*>]]></element> 18 <element><![CDATA[</?h5[^>]*>]]></element> 19 <element><![CDATA[</?h6[^>]*>]]></element> 20 <element><![CDATA[</?p[^>]*>]]></element> 21 <element><![CDATA[</?a[^>]*>]]></element> 22 <element><![CDATA[</?img[^>]*>]]></element> 23 <element><![CDATA[</?li[^>]*>]]></element> 24 <element><![CDATA[</?span[^>]*>]]></element> 25 <element><![CDATA[</?div[^>]*>]]></element> 26 <element><![CDATA[</?font[^>]*>]]></element> 27 <element><![CDATA[</?b[^>]*>]]></element> 28 <element><![CDATA[</?u[^>]*>]]></element> 29 <element><![CDATA[</?i[^>]*>]]></element> 30 <element><![CDATA[</?strong[^>]*>]]></element> 31 <element><![CDATA[</?hr[^>]*>]]></element> 32 <element><![CDATA[</?title[^>]*>]]></element> 33 <element><![CDATA[</?form[^>]*>]]></element> 34 <element><![CDATA[</?em[^>]*>]]></element> 35 <element><![CDATA[</?dfn[^>]*>]]></element> 36 <element><![CDATA[</?ins[^>]*>]]></element> 37 <element><![CDATA[</?strike[^>]*>]]></element> 38 <element><![CDATA[</?s[^>]*>]]></element> 39 <element><![CDATA[</?del[^>]*>]]></element> 40 <element><![CDATA[</?tt[^>]*>]]></element> 41 <element><![CDATA[</?xmp[^>]*>]]></element> 42 <element><![CDATA[</?plaintext[^>]*>]]></element> 43 <element><![CDATA[</?listing[^>]*>]]></element> 44 <element><![CDATA[</?center[^>]*>]]></element> 45 <element><![CDATA[</?base[^>]*>]]></element> 46 <element><![CDATA[</?bgsound[^>]*>]]></element> 47 <element><![CDATA[</?frameset[^>]*>]]></element> 48 <element><![CDATA[</?body[^>]*>]]></element> 49 <element><![CDATA[</?dd[^>]*>]]></element> 50 <element><![CDATA[</?dl[^>]*>]]></element> 51 <element><![CDATA[</?dt[^>]*>]]></element> 52 <element><![CDATA[</?frame[^>]*>]]></element> 53 <element><![CDATA[</?input[^>]*>]]></element> 54 <element><![CDATA[</?ol[^>]*>]]></element> 55 <element><![CDATA[</?select[^>]*>]]></element> 56 <element><![CDATA[</?option[^>]*>]]></element> 57 <element><![CDATA[</?pre[^>]*>]]></element> 58 <element><![CDATA[</?small[^>]*>]]></element> 59 <element><![CDATA[</?textarea[^>]*>]]></element> 60 <element><![CDATA[</?button[^>]*>]]></element> 61 <element><![CDATA[</?o:p[^>]*>]]></element> 62 </HtmlLabels> 63 <Separators> 64 <element><![CDATA[ ]]></element> 65 <element><![CDATA["]]></element> 66 <element><![CDATA[&]]></element> 67 <element><![CDATA[<]]></element> 68 <element><![CDATA[>]]></element> 69 <element><![CDATA[\n]]></element> 70 <element><![CDATA[\t]]></element> 71 <element><![CDATA[\r]]></element> 72 <element><![CDATA[<br />]]></element> 73 <element><![CDATA[<br/>]]></element> 74 <element><![CDATA[<br>]]></element> 75 <element><![CDATA[<header>]]></element> 76 </Separators> 77 <Other> 78 <element><![CDATA[</?script[^>]*>]]></element> 79 <element><![CDATA[(javascript|jscript|vbscript|vbs):]]></element> 80 <element><![CDATA[on(mouse|exit|error|click|key)]]></element> 81 <element><![CDATA[<\\?xml[^>]*>]]></element> 82 <element><![CDATA[<\\/?[a-z]+:[^>]*>]]></element> 83 <element><![CDATA[<(style)>.*?</\1>]]></element> 84 <element><![CDATA[<!--.*?-->]]></element> 85 </Other> 86 </filterStr>
这是博主整理的清理html标签获取纯文本的xml文件,目前对博主来说抓取的网页都是可以完美清理的。
博主在系统中大量使用了xml配置文件的方式,由于xml文件一般改动较小,故为他们的读取数据做了缓存处理。
c)先来看博主的通用缓存类
1 public class MemoryCache<TK, TV> 2 { 3 private readonly ObjectCache _memoryCache; 4 public static MemoryCache<TK, TV> Instance 5 { 6 get { return SingletonCacheProvider<MemoryCache<TK, TV>>.Instance; } 7 } 8 9 public MemoryCache() : this(null) { } 10 public MemoryCache(string name) 11 { 12 _memoryCache = new MemoryCache(string.Format("{0}_{1}_{2}", typeof(TK).Name, typeof(TV).Name, name)); 13 } 14 15 public TV Get(TK cacheKey) 16 { 17 if (_memoryCache.Contains(ParseKey(cacheKey))) 18 { 19 return (TV)_memoryCache[ParseKey(cacheKey)]; 20 } 21 else 22 { 23 return default(TV); 24 } 25 } 26 27 public void Set(TK cacheKey, TV cacheValues, TimeSpan timeSpan) 28 { 29 _memoryCache.Set(ParseKey(cacheKey), cacheValues, new DateTimeOffset(DateTime.UtcNow + timeSpan)); 30 } 31 32 public void Remove(TK cacheKey) 33 { 34 _memoryCache.Remove(ParseKey(cacheKey)); 35 } 36 37 private string ParseKey(TK key) 38 { 39 return key.GetHashCode().ToString(); 40 } 41 }
所有需要使用缓存的模板,需要继承实现下面的缓存接口:
1 /// <summary> 2 /// 缓存接口 3 /// 所有具象缓存类继承 4 /// </summary> 5 /// <typeparam name="TK">缓存键 类别</typeparam> 6 /// <typeparam name="TV">缓存值 类别</typeparam> 7 public interface ICache<TK, TV> 8 { 9 /// <summary> 10 /// 获得缓存值 11 /// </summary> 12 /// <typeparam name="TV">值类别</typeparam> 13 /// <param name="cacheKey">缓存键</param> 14 /// <returns></returns> 15 TV Get(TK cacheKey); 16 17 /// <summary> 18 /// 移除缓存值 19 /// </summary> 20 /// <param name="cacheKey">缓存键</param> 21 void Remove(TK cacheKey); 22 }
比如我们说到的xml获取数据对象模块,使用缓存的具体方案就是:
1 public class XmlModelCacheManager<TXmlModel> : ICache<string, TXmlModel> 2 { 3 private readonly string xmlPath; 4 public XmlModelCacheManager(string xmlPath) 5 { 6 this.xmlPath = xmlPath; 7 } 8 9 private readonly MemoryCache<string, TXmlModel> cacheMenager = MemoryCache<string, TXmlModel>.Instance; 10 11 public TXmlModel Get(string cacheKey) 12 { 13 var result = cacheMenager.Get(cacheKey); 14 if (result == null) 15 { 16 var xmlDoc = XMLHelper.LoadXml(xmlPath); 17 result = GetXmlValues(xmlDoc); 18 cacheMenager.Set(cacheKey, result, TimeSpan.FromDays(3)); 19 } 20 return result; 21 } 22 23 public void Remove(string cacheKey) 24 { 25 cacheMenager.Remove(cacheKey); 26 } 27 28 private TXmlModel GetXmlValues(XmlDocument xmlDoc) 29 { 30 var model = (TXmlModel)Activator.CreateInstance(typeof(TXmlModel)); 31 var properies = model.GetType().GetProperties(BindingFlags.Instance | BindingFlags.Public); 32 foreach (var property in properies) 33 { 34 if (property.PropertyType.IsGenericType) 35 { 36 var xmlNodes = xmlDoc.SelectSingleNode(@"filterStr/" + property.Name).ChildNodes; 37 if (xmlNodes.Count > 0) 38 { 39 var propListValues = (from XmlNode node in xmlNodes select node.InnerText).ToList(); 40 property.SetValue(model, propListValues, null); 41 } 42 } 43 } 44 return model; 45 } 46 }
由于博主的xml文件对象较多,故GetXmlValues方法中使用了较为抽象的反射机制来取值与赋值。
就以刚才的清理html标签获取纯文本的xmlModel为例:
1 public class ClearHtmlXmlModel 2 { 3 private readonly string xmlFileName = "ClearHtml.xml"; 4 public ClearHtmlXmlModel(bool hasData) 5 { 6 var model = new XmlModelCacheManager<ClearHtmlXmlModel>(ConfigurationManager.AppSettings["XMLTemplatesRoute"] + xmlFileName).Get("ClearHtml"); 7 this.HtmlLabels = model.HtmlLabels; 8 this.Separators = model.Separators; 9 this.Other = model.Other; 10 } 11 12 public ClearHtmlXmlModel() 13 { 14 15 } 16 17 /// <summary> 18 /// HTML标签 19 /// </summary> 20 public List<string> HtmlLabels { get; set; } 21 22 /// <summary> 23 /// 分隔符 24 /// </summary> 25 public List<string> Separators { get; set; } 26 27 /// <summary> 28 /// 其它特殊字符 29 /// </summary> 30 public List<string> Other { get; set; } 31 }
d)对纯文本进行关键词提取,再匹配配置好的分类词库xml文件,分析得到该文章所属类别。
1 /// <summary> 2 /// 分析文章所属类别 3 /// </summary> 4 /// <returns></returns> 5 private List<ArticleType> GetArticleTypes(string content) 6 { 7 var result = new List<ArticleType>(); 8 if (string.IsNullOrEmpty(content)) 9 { 10 return result; 11 } 12 else 13 { 14 var keys = keyWordExtractor.TextRankExtractor(content, 10); 15 if (keys.Any()) 16 { 17 var articleTypeRuleXmlModel = new ArticleTypeRuleXmlModel(true); 18 if (articleTypeRuleXmlModel.OverseasEducation.Any()) 19 { 20 result.AddRange(from overseasEducation in articleTypeRuleXmlModel.OverseasEducation 21 where keys.Any(k => k.Contains(overseasEducation)) 22 select ArticleType.OverseasEducation); 23 } 24 if (articleTypeRuleXmlModel.OverseasFinancial.Any()) 25 { 26 result.AddRange(from overseasFinancial in articleTypeRuleXmlModel.OverseasFinancial 27 where keys.Any(k => k.Contains(overseasFinancial)) 28 select ArticleType.OverseasFinancial); 29 } 30 if (articleTypeRuleXmlModel.OverseasHome.Any()) 31 { 32 result.AddRange(from overseasHome in articleTypeRuleXmlModel.OverseasHome 33 where keys.Any(k => k.Contains(overseasHome)) 34 select ArticleType.OverseasHome); 35 } 36 if (articleTypeRuleXmlModel.OverseasLaw.Any()) 37 { 38 result.AddRange(from overseasLaw in articleTypeRuleXmlModel.OverseasLaw 39 where keys.Any(k => k.Contains(overseasLaw)) 40 select ArticleType.OverseasLaw); 41 } 42 if (articleTypeRuleXmlModel.OverseasLife.Any()) 43 { 44 result.AddRange(from overseasLife in articleTypeRuleXmlModel.OverseasLife 45 where keys.Any(k => k.Contains(overseasLife)) 46 select ArticleType.OverseasLife); 47 } 48 if (articleTypeRuleXmlModel.OverseasMedical.Any()) 49 { 50 result.AddRange(from overseasMedical in articleTypeRuleXmlModel.OverseasMedical 51 where keys.Any(k => k.Contains(overseasMedical)) 52 select ArticleType.OverseasMedical); 53 } 54 if (articleTypeRuleXmlModel.OverseasMigration.Any()) 55 { 56 result.AddRange(from overseasMigration in articleTypeRuleXmlModel.OverseasMigration 57 where keys.Any(k => k.Contains(overseasMigration)) 58 select ArticleType.OverseasMigration); 59 } 60 if (articleTypeRuleXmlModel.OverseasTax.Any()) 61 { 62 result.AddRange(from overseasTax in articleTypeRuleXmlModel.OverseasTax 63 where keys.Any(k => k.Contains(overseasTax)) 64 select ArticleType.OverseasTax); 65 } 66 67 return result.Distinct().ToList(); 68 } 69 else 70 { 71 return result; 72 } 73 } 74 }
e)最后修改抓取数据状态,提交文章数据到规则化数据库。
额~~感觉自己写得挺明白,同事却说有点无厘头,不太能看明白了......
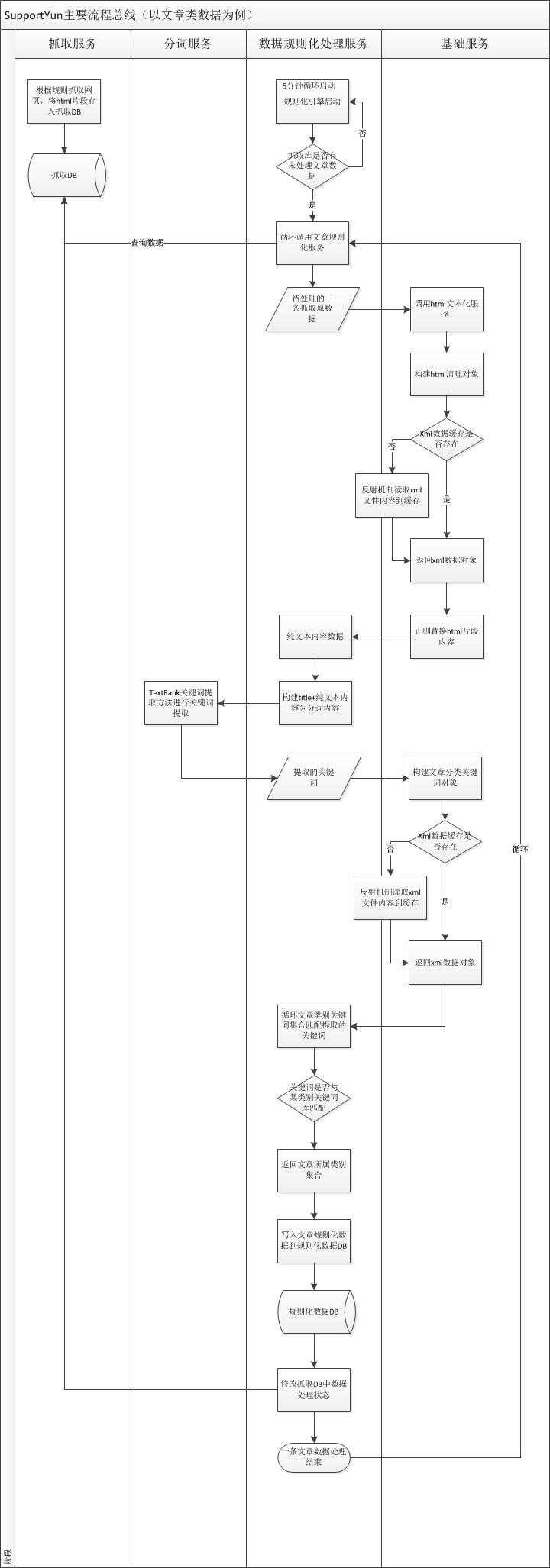
故博主就先不接着往下写了。先画了一张整体详细的流程图以供梳理(规则化引擎服务后面剩余的内容下一篇文章再详细的写):
把每一天都当成自己最后一天来过,明天都没有哪还有以后啊!
这一篇文章就先到这儿~~下一篇再接着说博主具体怎么针对活动数据做的规则化处理。
有人的地方就有程序员,有程序员的地方就有bug!
共勉!
原创文章,代码都是从自己项目里贴出来的。转载请注明出处哦,亲~~~
记一次企业级爬虫系统升级改造(三):文本分析与数据建模规则化处理
标签:分析 color com use 节点 rtu body 代码结构 sum
原文地址:http://www.cnblogs.com/csqb-511612371/p/6168800.html