只是笔记罢了,不要看
关于DAWG:
见紫书P390
把后缀自动机上所有节点都设为接受态就形成DAWG,可以接受一个字符串的所有子串。
一个子串的end-set是它在原串w中出现位置(从1开始编号)的右端点集合。
在DAWG中,end-set相同的子串属于同一个状态。
原因没原因,这应该算定义吧?
任意两个节点的end-set要么不相交,要么是包含关系。
原因:在DAWG上走一步,当前end-set的变化是将原end-set中各个元素+1(要去掉超出字符串长度的元素),然后拆分成1个或多个新end-set。
(实际相当于在一组已有子串之后同时插入一个(不同/相同的)字符,得到新子串。)
这里认为起始节点的end-set是{0,1,2,..,n},n为字符串长度。把空串也囊括进去。
以下转自:
http://fanhq666.blog.163.com/blog/static/8194342620123352232937/
冬令营上我犯了最大的一个错误,就是在陈立杰讲后缀自动机的时候睡觉。
| b
原因同DAWG。例如:3号点end-set为{4,5},其中各个元素+1得到{5,6},恰好是5号节点end-set{5}和6号节点end-set{6}的并集,而且后两者不相交。
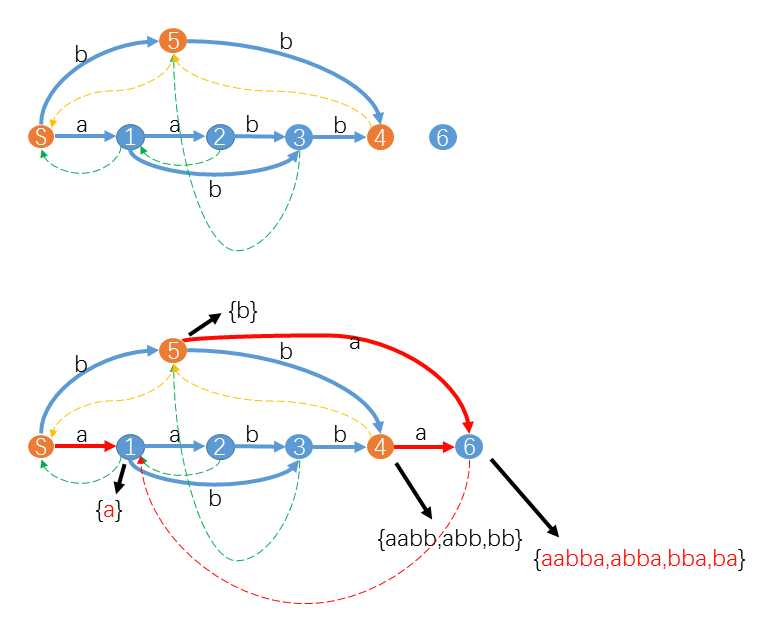
(以下为原证明)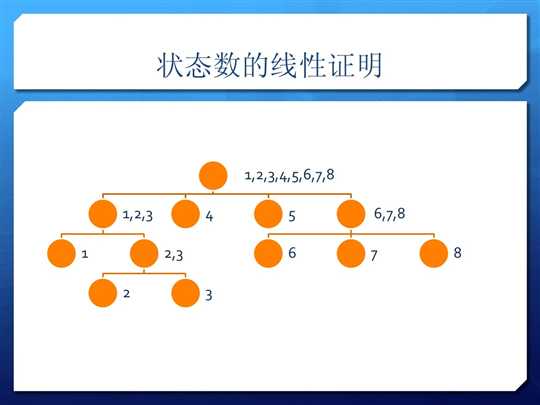 ......
......

| b
紫书上(相同含义)的描述是:((补注)在以任何方式从起始状态走到该状态得到的所有串中,)每个状态中都有一个最长串,其他的都是它的后缀,并且长度连续。
原PPT上的描述(有图):见上面
证明嘛...显然?看起来是对的?
这里有一些证明:http://hihocoder.com/problemset/problem/1441
后缀链接的定义http://hihocoder.com/problemset/problem/1441
将后缀自动机上所有边去掉,加上所有后缀链接,就得到了parent树,稍微改一下形式就可以得到将原串翻转得到的字符串的后缀树(此时所有边从子节点指向父节点)
有时候讲的Parent(x)就是x的后缀链接指向的节点
看上面两张图中,上面的那张图:后缀链接对应的后缀树上的边是:
5->S===>b,4->5===>baa,3->5===>aa,2->1===>a,1->s===>a,也就是后缀链接起点能接受的所有长度的串,按长度从小到大排,各取第一个字符组成的串
后缀树的根就是S
从某一节点沿着后缀链接走到S,记录下经过所有边代表的串,翻转序列,连成一个字符串,然后翻转整个字符串,就是该节点在后缀自动机上能接受的最长串
某一节点能接受的最长串为S,则该节点能接受的所有串都是S的后缀,往后缀链接跳一步到的节点能接受的串则也是S的
新建点r。
把Par[x]理解为类似fail指针(文本串在某节点u处失配,那么该节点能接受的最长串的一系列后缀(到该节点能接受的最短串为止)匹配时都会失配,因此可以将文本串对齐的位置向前移一段)。
转自http://wyfcyx.is-programmer.com/posts/76107.html
搞了半天还是搬到后缀树上理解容易。。。。。
感觉单纯地从"后缀自动机"的角度来入手并不是非常合理.因为我们懂得很多"后缀自动机"的性质,但却并不清楚"后缀自动机"在本质上是什么.
让我们从后缀树说起.
[1]后缀Trie
Trie树是一棵有根树,每个节点都代表从根节点到这个节点的路径上的字母顺次连接起来的字符串.
对于一个长度为\(n\)的字符串,我们用一颗Trie树插入它的所有的后缀.不难发现,这样构造的时空复杂度都是\(O(n^2)\).
但是后缀Trie却有一些非常好的性质:例如我们想得到后缀数组,只需进行一次dfs即可.又或是我们想查询一个模式串是否在这个串中出现,令模式串长度为\(m\),则我们只需\(O(m)\)的复杂度便可以解决.
但是这样时空复杂度过高了-QoQ.我们不得不考虑别的解决方法.
[2]后缀树
我们发现后缀Trie上有一些非常长的链.我们考虑对信息进行压缩,但是使得它依然具有后缀Trie的性质.
我们将原有的后缀Trie上的节点分为两类:关键点和非关键点.
形象的说,关键点就是那些链的分叉点,非关键点就是在链中间的点.
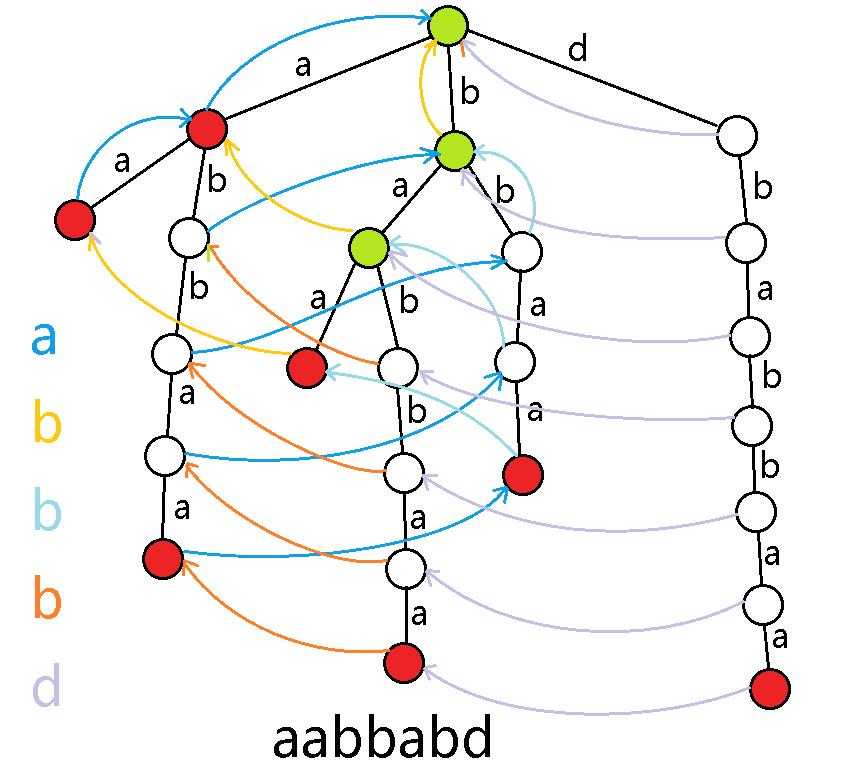
我们以串"dbabbaa"为例,看下面的图.
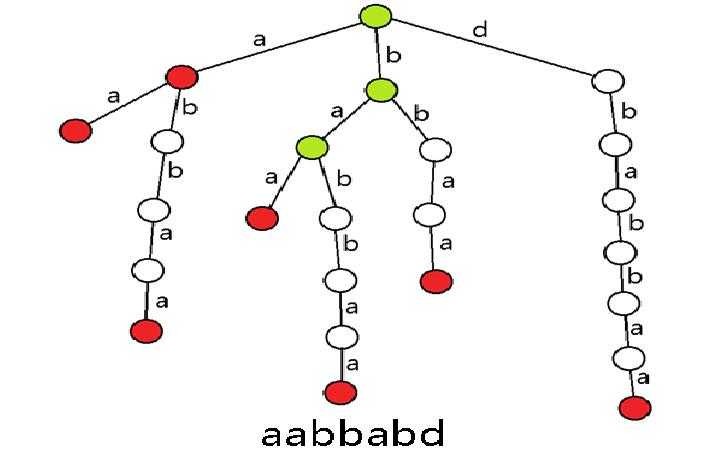
从这幅图来看,白色节点就是非关键点,有色节点就是关键节点.其中红色节点表示一个后缀.
我们考虑的后缀树,事实上仅包含这些有色的关键节点.两个关键点之间的边,便包含着之前路径上的非关键点.
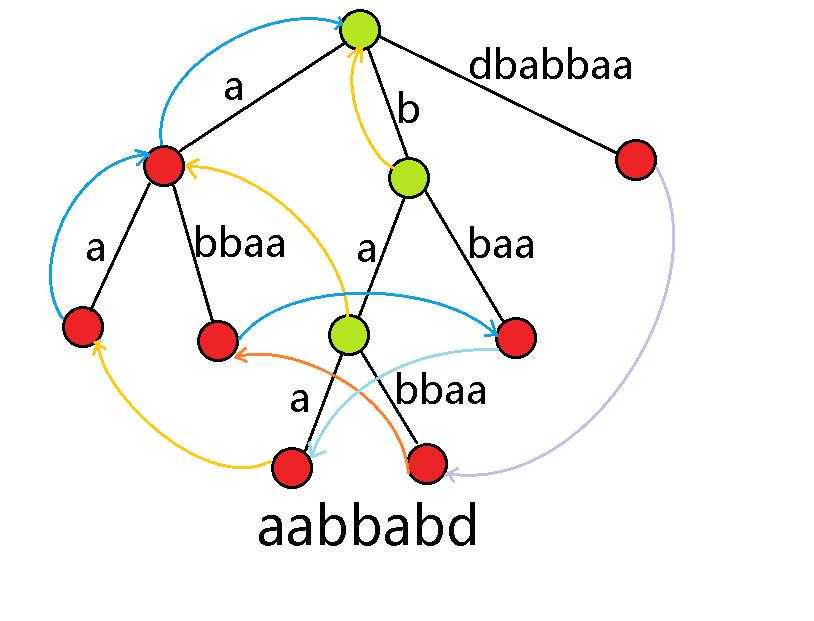
上面这幅图便是串"dbabbaa"的后缀树,至于那些指针是什么?一会再说.
为了建立刚才描述的这颗后缀树,我们依旧可以暴力将\(n\)个后缀插入Trie树中,只不过需要做一些变化:在产生分叉时新建节点即可.
通过观察我们发现:红色节点只有\(n\)个,而每一个绿色节点的出现都是在合并红色节点的集合,由于红色节点只有\(n\)个,也就是说至多被合并\(n\)次,因此绿色节点只有\(O(n)\).因此,我们有后缀树的节点数是\(O(n)\)级别的.
即便如此,暴力建树的时间复杂度依旧是\(O(n^2)\)级别的.我们需要寻求更有效率的建树方法.
[3]后缀树的高效构造(只是其中一种能用来说明后缀自动机的方法而已)
这是我们需要介绍刚才图中出现的一些指针了.
我们定义,除了根节点之外,每个节点都有一个\(pre\)指针,指向将这个节点代表的串的首字母删除后得到的串对应的节点.
刚才图中的指针就是\(pre\)指针.不过刚才的图是后缀树,我们重新给出在后缀Trie上的\(pre\)指针:
再定义\(pre\)的逆指针\(tranc\)指针.一个点显然不一定只有一个\(tranc\)指针.令节点\(p\)的\(tranc\)指针\(tranc(p,x)\)指向的字符串表示在节点\(p\)表示的字符串前面加上一个字符\(x\)得到的字符串对应的节点.这显然很符合\(pre\)的逆指针的性质.
这两个指针能够帮助我们高效的构造后缀树.
结合上面的图我们看到,后缀树的压缩信息的方式事实上是将非关键点的信息全部压缩到它的深度最小的关键点儿子上.例如,将从别处指来的\(pre\)指针指到他的关键点儿子上.将自己的\(tranc\)指针从自己的关键点儿子指出去.
事实上,我们需要的后缀树仅仅是每个节点的父节点以及\(tranc\)指针.
我们不妨采用增量法构造一颗后缀树.
假设对于字符串\(s[1,n]\),我们得到了\([i+1,n]\)的后缀树,考虑我们如何得到\([i,n]\)的后缀树.
不妨令字符\(i\)为\(x\).
事实上我们发现只是多出了一个后缀\(i\)而已,那么我们需要将这个后缀也插入后缀树中.新建一个节点\(np\)表示这个后缀.
对于后缀树中的每一个节点,我们顺便记录这个节点表示的字符串的长度.
考虑从根节点到表示串\([i+1,n]\)的节点到一条路径(链)上的若干个节点,事实上每个节点都表示着一个串\([i+1,n]\)的前缀.
我们发现我们需要拓宽这些前缀的\(tranc\)指针,使得它们能够通过在前面加上一个字符\(x\)到达一个新的状态.
{1}如果对于链上的每一个点都没有\(tranc(x)\)的出边,我们自然只需都添加上这条出边就好了.
{2}如果有链上的某个点有\(tranc(x)\)的出边呢?
假设点\(p\)是这条链上深度最大的有\(tranc(x)\)的出边的点,那么显然从根节点到\(p\)的路径上的所有点必定都有\(tranc(x)\)的出边.
为何是深度最大的?
该节点有该出边,那么该节点的任意祖先(表示的字符串都是其表示字符串的前缀)都有该出边。
我们首先让剩下的点都连上\(tranc(x)\)的出边.
都连上同一个点?
这样就产生了下面的"被压缩到它的一个关键点儿子“情况。
我们令\(q=tranc(p,x)\).
Case1:如果\(q\)原本就在后缀树中,我们只需让\(np\)的树上的父亲为\(q\),便可以结束这个阶段.因为我们考虑一下别的点,貌似都没有什么影响的说.
Case2:如果\(q\)原本是后缀树中的无用节点.这什么意思?指针不是都指向后缀树中的点吗?而这些点显然应该是原有的关键节点啊!
对应上面fhq博客中插入在"儿子和兄弟"的两种情况。
参见上面谈论的后缀树的压缩方式.可能\(q\)是被压缩到它的一个关键点儿子上了.我们令它的关键点儿子为\(q\),而其自身为\(nq\).
nq现在实际上还未被建出来。
下面考虑我们需要对后缀树进行的修改.
首先我们令\(nq\)的父亲为\(q\)原来的父亲,同时\(q\)和\(np\)的父亲都设为\(nq\).这些都是显而易见的.
回忆:np是新建节点
举例:原来是x---(abcd)---q,现在要插入一个abef,插入后变为x---(ab)---nq---(cd)---q
\
\---(ef)---np
由于\(nq\)的关键点儿子是\(q\),那么\(nq\)的\(tranc\)转移显然应该与\(q\)相同.否则,\(nq\)就不至于当做无用节点去掉.所以,我们令\(nq\)拷贝\(q\)的\(tranc\)转移.
让我们通过第三幅图来观察一下在后缀Trie上\(pre\)指针的某些特性.我们观察一整条链的\(pre\)指向,我们发现这些指向的节点形成了另外一条链.
那么反过来\(tranc\)的指针指向的节点也是呈一条链的.
在后缀树上,由于信息被压缩,那么不难发现指针指向的节点是分段的.(有点意识流QoQ,看图就会有体会了吧)
首先\(p\)的\(tranc(x)\)指针应该指向\(nq\).(否则我们为什么要把它搞出来?)考虑\(p\)的一段连续原先\(tranc(x)\)指向\(q\)的祖先,它们的\(tranc(x)\)指针都应该指向\(nq\).
注意”连续“
暂时没搞明白
这是由于一条链的连续性使然.
看起来别的节点大概就没有什么影响了.
蛮清晰吧?
总结一下,有一棵倒着建的后缀树,在原串末尾加入一个字符ch时,维护后缀树需要的操作:
(也是有一个后缀自动机,在原串末尾加入字符ch时维护需要的操作;正着建,就是原始的在首部插入字符的O(n)建后缀树算法)
(每个节点x记录父亲par[x],当前节点表示的字符串长度len[x],也相当于后缀自动机上该节点接受的最长子串的长度)
(trans[u][ch]表示:表示"(点u表示的字符串)头部加上一个ch后得到新串"的节点)
1.新建一个点np用于存放新字符
2.找到后缀树上表示原来的原串的节点u,暴跳u的父亲,直到到达某个节点p,满足p不存在(由根节点的父亲得到,用0表示)或者p的trans[p][ch]不为空;在跳的过程中对于所有不合法节点x都要将trans[x][ch]设为np
3.如果p不存在,将par[np]设为根,退出
4.令q=trans[p][ch]。若len[q]==len[p]+1,表示"q原本就在后缀树中",则直接让par[np]为q即可,退出
5.否则,表明需要拆一些点/边。新建节点nq,令par[q]=nq,par[np]=nq,par[nq]=p,将q原来的整个trans数组复制到nq中。更新len[nq]为len[p]+1。
6.暴跳p及其祖先,遍历到点x时,如果trans[x][ch]==q,则改为nq;否则break。
我们能够证明,这样建立后缀树的复杂度是\(O(n)\).
upd@2015.01.14 19:50 tag:更新了一些题解的链接
http://wyfcyx.is-programmer.com/posts/76391.html
http://wyfcyx.is-programmer.com/posts/76400.html
http://wyfcyx.is-programmer.com/posts/76423.html
你有一棵按倒过来的字符串建的后缀树,对于每一个节点u,额外记"后缀指针"trans[u][ch]表示在当前节点表示的字符串前添加字符ch得到的字符串对应的节点。
对于某一个节点u,设其表示的字符串为S,则ch+S是trans[u][ch]能匹配的字符串的前缀(因为存在路径压缩,ch+S的信息可能被压到了以它为前缀的其他串上)。
要在原串末尾加一个字符ch,就是要向后缀树中插入一条新后缀。
那么找到表示原来的原串的节点u,找到trans[u][ch]。先新建一个节点x,表示新字符位。
aaaaaaaa