标签:集群 mapred 操作 自定义 调优 分发 微软雅黑 image com
因业务上的需要,无可避免的一些运算一定要使用shuffle操作,无法用map类的算子来替代,那么尽量使用可以map侧预聚合的算子。
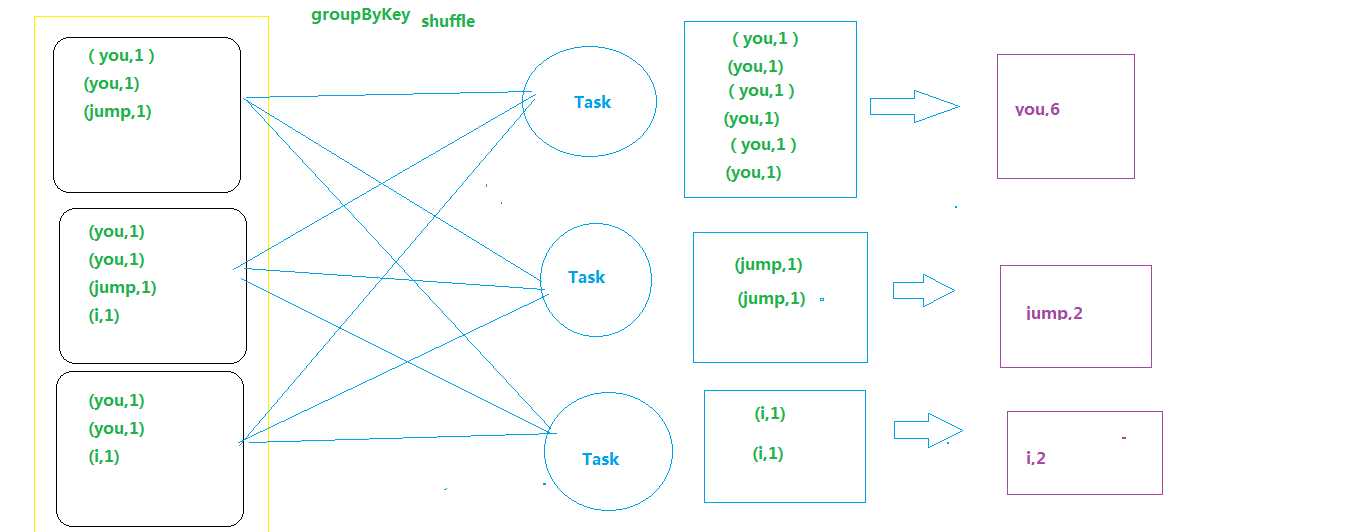
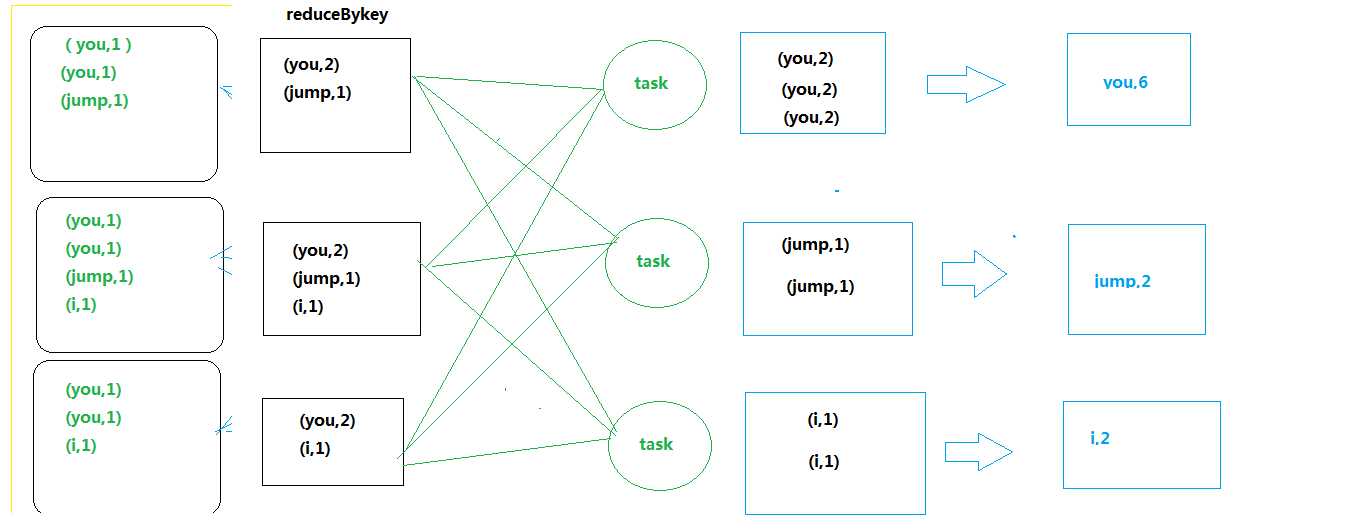
map侧预聚合,是指在每个节点本地对相同的key进行一次聚合操作,类似于MapReduce中的本地combine。map-side预聚合之后,每个节点本地就只会有一条相同的key,因为多条相同的key都被聚合起来了。shuffle时,节点间拉取其他节点上的相同key时,就会大大减少需要拉取的数据数量,从而也就减少了磁盘IO以及网络传输开销。
对应到算子,建议使用reduceByKey或者aggregateByKey算子来代替groupByKey算子。因为reduceByKey和aggregateByKey算子都会使用用户自定义的函数对每个节点本地的相同key进行预聚合。而groupByKey算子是不会进行预聚合的,全量的数据会在集群的各个节点之间分发和传输,性能相对较差。
【Spark调优】:如果实在要shuffle,使用map侧预聚合的算子
标签:集群 mapred 操作 自定义 调优 分发 微软雅黑 image com
原文地址:https://www.cnblogs.com/wwcom123/p/10514429.html