标签:基础 编号 png enum mat 需要 mamicode 性能 port
文本表示是自然语言处理中的基础工作,文本表示的好坏直接影响到整个自然语言处理系统的性能。在自然语言处理研究领域,文本向量化是文本表示的一种重要方式。
顾名思义,文本向量化就是将文本表示成一系列能够表达文本语义的向量。无论中文还是英文,词语都是表达文本处理的最基本单元。
当前阶段,对文本向量化都是通过词向量化实现的。当然也有将文章或者句子作为文本处理的基本单元,像doc2vec和str2vec技术。
接下来主要是讨论以词语作为基本单元的word2vec技术,将先从onehot编码到word2vec,再从glove词向量到fasttext
one-hot编码,又称独热编码、一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。举个例子,假设我们有四个样本(行),每个样本有三个特征(列),如下图:
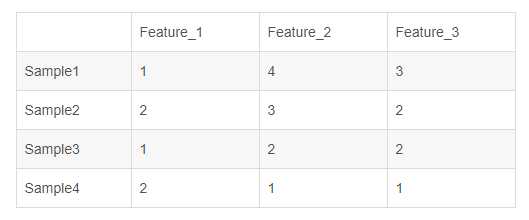
上图中我们已经对每个特征进行了普通的数字编码:我们的feature_1有两种可能的取值,比如是男/女,这里男用1表示,女用2表示。那么one-hot编码是怎么搞的呢?
我们再拿feature_2来说明:这里feature_2 有4种取值(状态),我们就用4个状态位来表示这个特征,one-hot编码就是保证每个样本中的单个特征只有1位处于状态1,其他的都是0。
1 -> 0001; 2 -> 0010; 3 -> 0100; 4 -> 1000;
对于2种状态、3种状态、甚至更多状态都可以这样表示,所以我们可以得到这些样本特征的新表示,如下图:
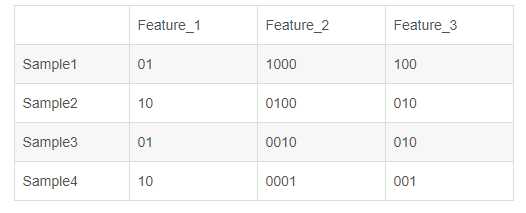
one-hot编码将每个状态位都看成一个特征。对于前两个样本我们可以得到它的特征向量分别为:
Sample1 ->[0,1,1,0,0,0,1,0,0] Sample2 ->[1,0,0,1,0,0,0,1,0]
one hot在特征提取上属于词袋模型(bag of words)。关于如何使用one-hot抽取文本特征向量我们通过以下例子来说明。假设我们的语料库中有三段话:
我们首先对上面语料进行分词,并获取其中的所有的词,然后对每个词进行编号:
1 我; 2 爱; 3 爸爸; 4 妈妈; 5 中国
然后使用one-hot对每段话提取特征向量:

因此我们得到了最终的特征向量为:
我爱中国 -> ( 1,1,0,0,1 )
爸爸妈妈爱我 ->( 1,1,1,1,0 )
爸爸妈妈爱中国 ->( 0,1,1,1,1 )
在实际应用过程中,我们对多篇文本进行分词,并统计词频,生成的词典中词数有几万,十几万,甚至更多,如果都进行one-hot进行编码肯定是行不通的,这时一般会根据词频选取前5K或50K的词进行向量化,摒弃写低频词,提高效率。当然5K或50K对于one-hot编码已经很大了,后面会用word2vec对其进行处理。
优缺点分析:
优点:
一是解决了分类器不好处理离散数据的问题;
二是在一定程度上也起到了扩充特征的作用(上面样本特征数从3扩展到了9)。
缺点:
1. 它是一个词袋模型,不考虑词与词之间的顺序,无法保留词序信息;
2. 它假设词与词相互独立,存在语义鸿沟问题(在大多数情况下,词与词是相互影响的);
3. 它得到的特征是离散稀疏的;
4. 维度灾难:很显然,如果上述例子词典中包含10K个单词,那么每个需要用10000维的向量表示,采用one-hot编码,对角线元素均设为1,其余为0,也就是说除了文本中出现的词语位置不为0,其余9000多的位置均为0,如此高纬度的向量会严重影响计算速度。
1 import numpy as np 2 3 contents = [‘我 毕业 于 **大学‘,‘我 就职 于 **公司‘] 4 word_dict = {} 5 6 for content in contents: 7 for word in content.split(): 8 if word not in word_dict: 9 word_dict[word] = len(word_dict) 10 print(word_dict) 11 12 res = np.zeros((len(contents), len(word_dict))) 13 14 for i, content in enumerate(contents): 15 for word in content.split(): 16 j = word_dict.get(word) 17 res[i, j] = 1 18 19 print(res)
2、Keras中one-hot编码的实现
1 from keras.preprocessing.text import Tokenizer 2 contents = [‘我 毕业 于 **大学‘,‘我 就职 于 **公司‘] 3 4 #构建单词索引 5 6 tokenizer =Tokenizer() 7 tokenizer.fit_on_texts(contents) 8 9 word_index = tokenizer.word_index 10 print(word_index) 11 # print(len(word_index)) 12 13 sequences = tokenizer.texts_to_sequences(contents) 14 # print(sequences) 15 16 one_hot_result = tokenizer.texts_to_matrix(contents) 17 print(one_hot_result)
标签:基础 编号 png enum mat 需要 mamicode 性能 port
原文地址:https://www.cnblogs.com/huangm1314/p/11306488.html