标签:int scom 不能 针对 strong doc 映射 nio 应用程序
还没有搞完= =有空了继续~~
Serverless computing越来越受欢迎,他允许用户快速在云上发起成千上万的short-lived tasks,并且具有高弹性,能够精细计费。这些特性使得Severless Computing请求(更倾向于)交互式数据分析(interactive data analytics)。然而,在分析作业的执行阶段之间交换中间数据是一个关键挑战,因为在没有服务器的任务之间进行直接通信非常困难。传统方式是将这些短期的数据存放在远程的data store中。但是,现在的存储系统并不能满足severless applications在弹性、性能、成本上的需求。
我们提出了Pocket,一个弹性的分布式数据存储。Pocket能够自动的调整,为应用以低成本提供他们想要的性能。Pocket能跨多维度(CPU核,网络带宽,存储性能)的动态调整资源的大小,并且在确保不会出现I/O瓶颈的情况下,能够利用多样的存储技术来最小化成本。我们的研究表明,对于无服务器分析的应用程序(serverless analytics application),Pocket实现了与ElastiCache Redis类似的性能,同时降低了近60%的成本。
serverless平台一开始是因为web微服务和 IoT 应用而发展起来的,但是由于serverless 平台 的弹性、计费的优势,使得他们更加期待 数据密集型的应用,例如interactive analytics。
传统的serverless应用由一个单一的函数组成,这个该函数在新请求到达时执行。analytics jobs由好几个阶段组成。需要在任务的不同阶段共享数据和状态。
大多数的框架实现数据共享的方式是,在本地存储中每一个缓冲中间数据的node上放一个长时间运行的framework agent。这允许不同执行阶段的任务可以在network上直接交换中间数据。
但是,在serverless视线中,不存在长时间运行的应用代理来管理本地存储。此外,serverless应用没有控制 任务调度或任务位置,使得任务之间的直接通信很困难。由于这些限制,serverless应用的传统的传统数据共享方法是 远程存储服务(remote storage service)。例如,早期的 serverless 分析框架 使用对象存储(例如,S3)、数据库(例如,CouchDB)或分布式缓存(例如,Redis)。
不幸的是,现在的存储服务并不适合 serverless 应用的 临时中间数据 的共享。 我们所说的中间数据不是 需要长期存储的输入或输出的数据,而是 临时数据(ephemeral data )。
文件系统,对象存储和 NoSQL数据库 更加关注 持久的,长期的,高度可靠的村塾,而非性能或者成本。
分布式的 key-value 存储能够提供好的性能,但是用户会疲于 需要管理storage cluster scale和配置,其中包括选择要提供的适当的计算、存储和网络资源。
不同存储技术的可用性(例如:(例如DRAM、NVM、Flash和HDD),使得更难性能和成本最佳的集群配置。然而,存储技术的选择是至关重要的,因为作业由不同的存储延迟、带宽和容量需求,而不同的存储技术在性能特征和成本方面存在显著差异。
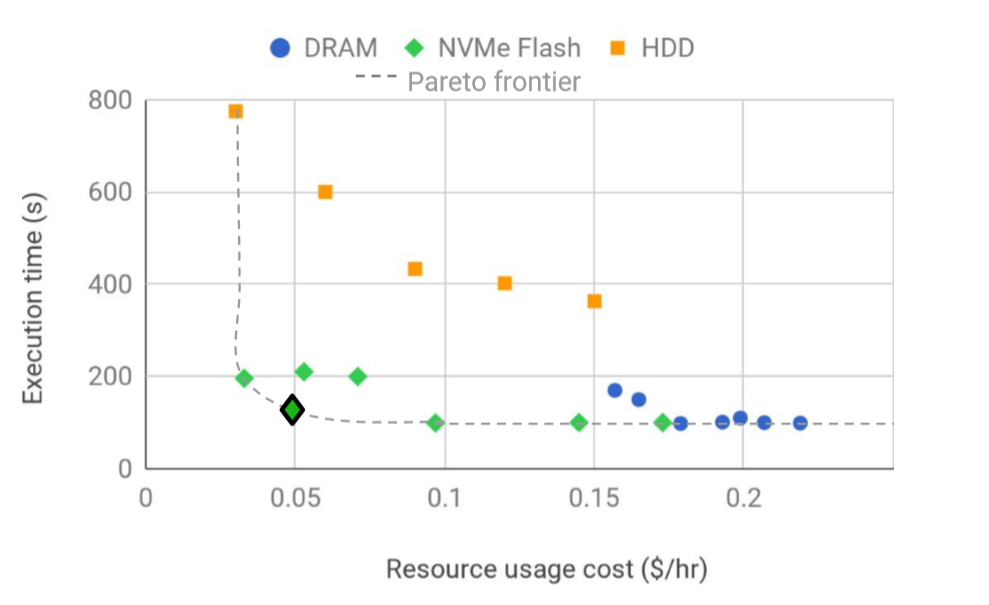
这个图绘制了 一个serverless video job 在 Amazon EC2 上展现出的性能-成本 均衡图。他们使用了分布式的临时数据存储,但是配置有所不同:存储技术、节点数目、每个节点的计算资源、网络带宽。 每一种配置都有队医你给的性能-成本。 为一个作业找到帕累托有效的存储分配并不简单,如果有多个作业,就会变得更加复杂。
我们提出了 Pocket,为serverless 分析的有效数据共享 所设计的一种 分布式的数据存储。Pocket为任意大小的数据集、自动资源伸缩、跨多个存储层(如DRAM、Flash和磁盘)的 智能数据存放 提供了高吞吐量和低延迟。Pocket的这个独特之处 得益于 他在三个层上的严格的职责分离:控制层(决定数据存放的策略);元数据层(管理分布式数据的存放);dumb data (即:元数据无关)层(负责存储数据)。Pocket使用启发式(考虑作业特征)来分配存储介质、容量、带宽和CPU资源,以提高成本和性能效率。存储API特意公开简单的I/O操作,以达到亚毫秒级的访问延迟。我们打算让云提供商来管理我们的口袋,并向用户提供一种“用多少就付多少”的成本模式。
我们在 Amazon EC2 上部署了Pocket,并且使用3种任务来评估他:video analytics, Map Reduce sort, distributed source code compilation。我们发现,Pocket能够调整资源的类型和数量,使作业的性能与使用ElastiCache Redis(基于DRAM的键值存储)相似,同时节省了近60%的成本。
总而言之,我们做了以下贡献:
大范围的对象大小变化时保有高性能。Serverless 分析应用程序在存储、分发和处理数据的方式上差别很大。这种多样性反映在作业期间生成的临时数据的粒度上。
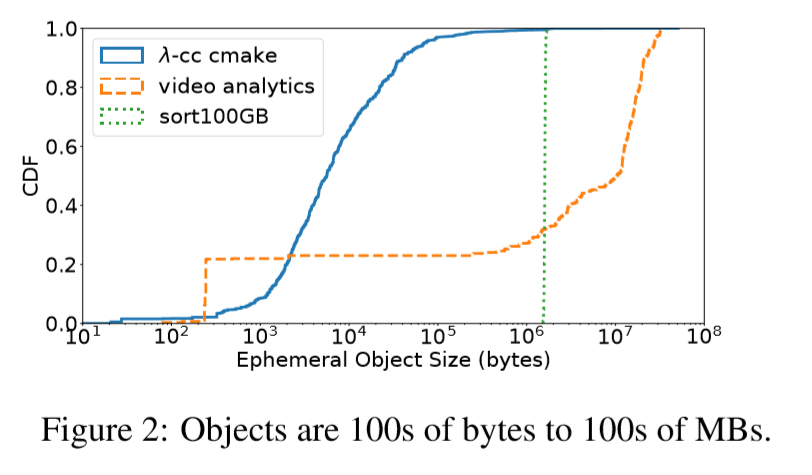
这个图 显示了 cmake程序的分布式lambda编译、使用 Thousand Island(THIS)视频扫描仪的无服务器视频分析作业[63],以及lambdas上的100gb MapReduce排序作业的临时对象大小分布。关键的发现是,临时数据访问粒度在大小上变化很大,从数百字节到数百兆字节不等。
排序作业的结果是一条直线,因为他的临时数据大小等于分区大小。但是,当数据集大小和/或工人数量不同时,线的大小位置会发生变化。
读/写大对象的应用程序需要高吞吐量(例如,我们发现用500个lambdas对100 GB进行排序需要高达7.5 GB/s的临时存储吞吐量),而低延迟对于小对象访问很重要。
因此,对于对象大小的整个范围,临时数据存储必须提供高带宽、低延迟和高IOPS。
自动和细粒度的缩放(Automatic and ?ne-grain scaling)。serverless computing关键的一点是能灵活的动态满足应用需求。因此,一个用于serverless的应用程序的临时数据存储可以在不到一秒的时间内观察到大量的I/O请求。一旦负载减少了,应该能立即缩小,来降低成本。想要扩展或者缩小来满足弹性应用程序的需求,需要一个 能够在以秒为单位的细时间粒度上 能够在多个资源维度 (例如,增加/减少存储容量和带宽、网络带宽和 cpu core)中 增长或收缩 的存储解决方案。此外,serverless 平台的用户希望使用自动管理资源的存储服务,并且只对其作业实际消耗资源 进行 精细收费,以便与serverlesscomputing已经为计算和内存资源提供的抽象相匹配。
自动的资源管理很重要,因为对于用户来讲,寻找最合适的配置很难。例如,找到图1中列出的帕累托最优点并不是件容易的事;超过这个点,即使资源增多(成本增多),执行时间也不会减少;而在这个点之前,成本随低,但是时间会增长。总之,临时数据存储必须自动调整资源的大小,以满足应用程序I/O需求,同时最小化成本。
存储技术Storage technology awareness。除了调整集群资源的大小之外,存储系统还需要决定对哪些数据使用哪种存储技术。云中的各种存储介质支持不同的性能-成本权衡,如图1所示。每种存储技术在I/O延迟、吞吐量和每GB容量的IOPS以及每GB的成本方面有所不同。存储技术的选择取决于作业的特性。因此,临时数据存储必须将应用程序数据放在正确的存储技术层上,以提高性能和成本效率。
容错(Fault-(in)tolerance):通常,数据存储必须在保持服务正常运行的同时处理故障。因此,存储系统通常采用 复制 (replication )和 擦除码 (erasure codes)等容错技术。对于需要长期存储的数据,比如分析工作负载的原始输入和最终输出数据,数据不可用带来的通常会超过容错机制的成本。
但是,如图3所示,临时数据的生命周期很短,只有10-100秒。与原始输入和最终输出数据不同,临时数据只有在作业执行期间才有价值,并且可以很容易地重新生成。
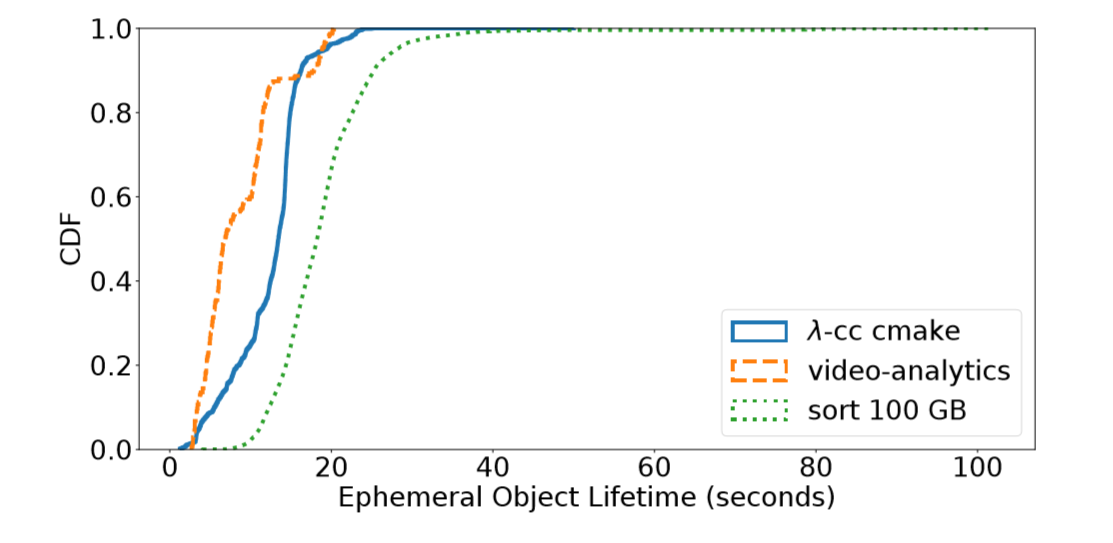
此外,容错通常被嵌入到计算框架中,这样存储数据和计算数据就变成了可互换的[39]。例如,Spark使用了一种称为 resilient distributed datasets (RDDs)的数据抽象来减少离散和跟踪沿袭信息,以实现快速数据恢复。因此,我们认为 短期存储不必像传统存储系统那样提供高容错。
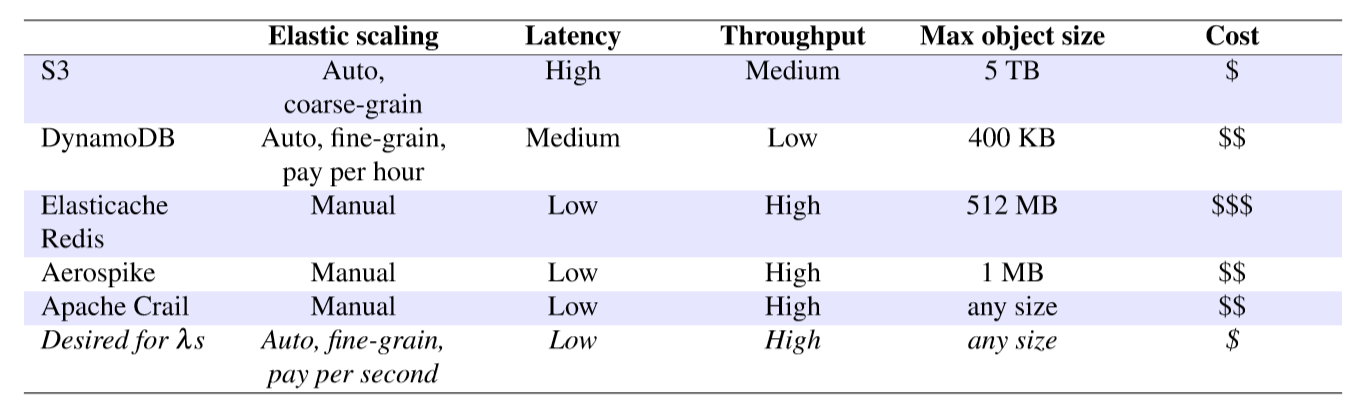
Pocket的关键设计原则:
看图4.该系统由一个逻辑集中式控制器、一个或多个元数据服务器和多个数据平面存储服务器组成。
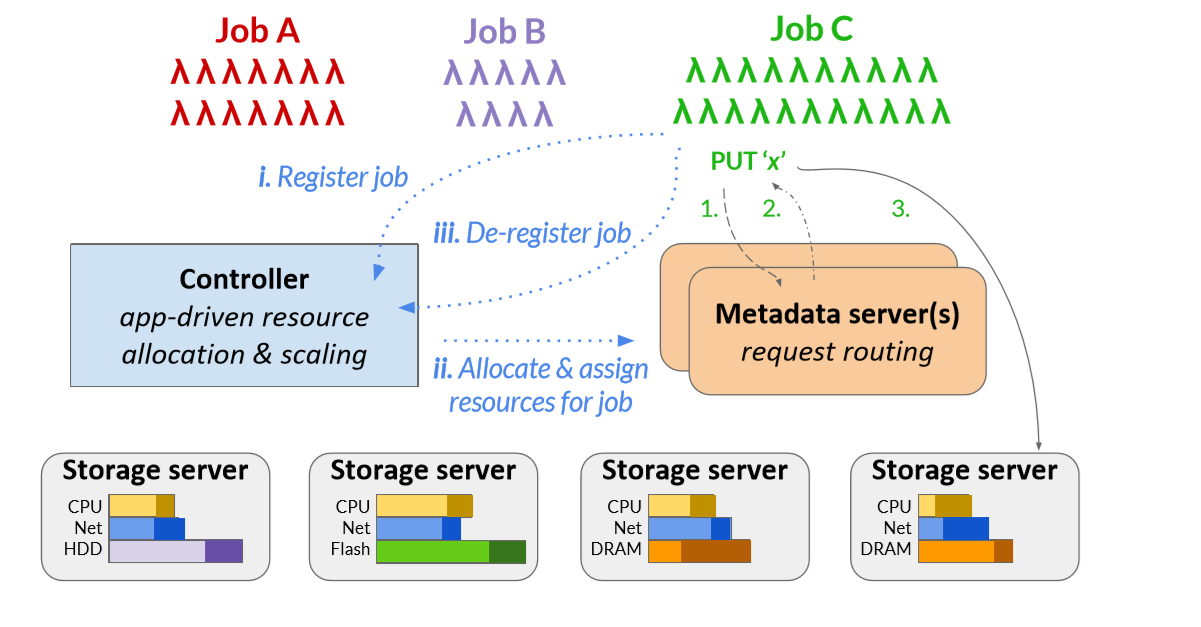
Controller ,将会在第四节详细描述。它为作业分配存储资源,并随着作业数量及其需求的变化,动态地调整Pocket元数据和存储节点。Controller 还决定的数据放在哪(作业数据要使用哪些节点和存储媒体)。
metadata servers 通过将 客户端请求传给 适当的storage server,强制执行由 Controller 生成的粗粒度数据放置策略。Pocket的 metadata plane 以块的粒度管理数据,块的大小是可配置的。我们 使用64 KB大小的块。大于 块大小 的对象被划分称号及块,分布在不同的存储服务器上,因此Pocket可以支持任意大小的对象。
客户端访问元数据无关的、性能优化的存储服务器上的数据块,这些服务器配备了不同的存储介质(DRAM、Flash和/或HDD)。
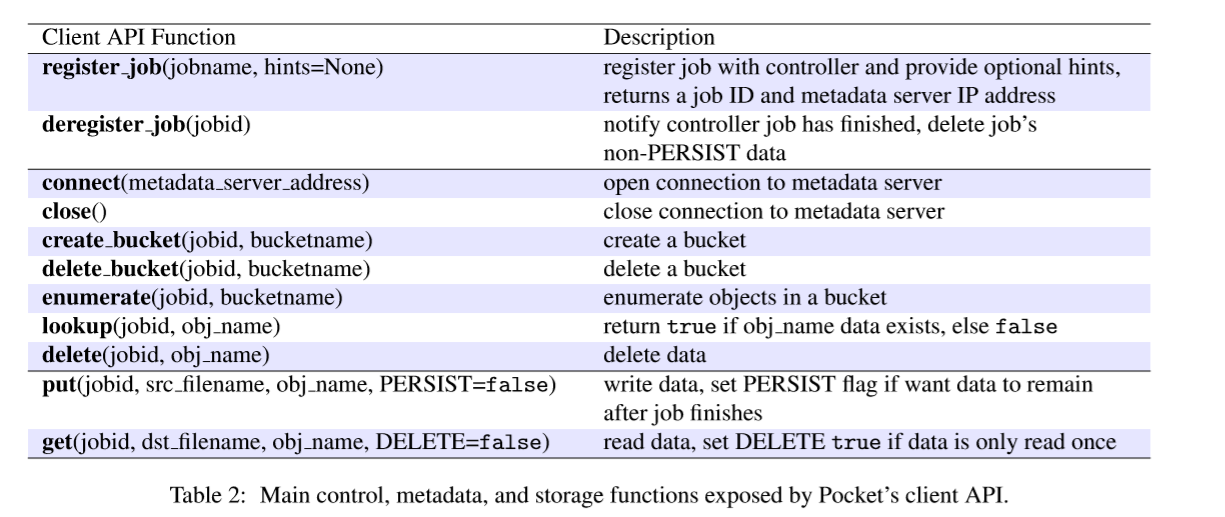
这个表概述了 Pocket的应用程序的接口。Pocket公开了一个对象存储API,包含针对 临时存储用例 定制的附加功能。我们描述了这些function以及它们如何映射到 Pocket 的三个分离的层(the control plane, the metadata plane, the data plane)。
Control function。应用程序有两个用来和Pocket Controller交互的API call:register job 和deregister job。
Metadata functions:
Storage functions:
看看使用 Pocket 的 serverless analytics application是如何完成工作的。首先,他 注册controller,并且可选择是否提供关于他的job的特性的hint。controller决定了使用的存储层(DRAM、闪存、磁盘)和storage servers 的数量。通过这些storage servers 来分发作业的数据,以满足吞吐量和容量需求。controller 生成一个 weight map (4.1中详细讲),来决定工作的数据放置策略并将此信息发送给它分配的 metadata server 。metadata server负责管理job的元数据,引导客户端的I / O请求(步骤二)。如果controller 需要新的存储服务器来满足job的资源分配,这个job的registration就call stalls,(???)直到这些节点是可用的。
注册表完整后,job启动lambdas。Lambdas首先连接到分配给它们的metadata server,该服务器的IP地址由controller根据注册表提供。Lambda客户机首先链接metadata server,获取 storage server的IP地址和块地址,来写入数据。对于需要多个块的大object,客户端以流方式请求metadata server分配容量;当单个块的容量耗尽时,客户端向metadata server发出新的容量分配请求。
当最后一个λ的工作完成,job销毁他的登记表来释放Pocket的资源。同时,当jiob正在执行时,controller持续监视storage server 和matadata server中的资源利用情况(storage server里的水平柱子),根据需要添加/删除服务器,以在提供高性能的同时最小化成本(参见§4.2)。
虽然Pocket不是为了提供高数据持久性而设计的,但该系统也有相应的机制来处理这些问题。
storage server 向controller 和metadata server 发送心跳。当storage server无法发送心跳时,metadata server 会自动将其块标记为无效。因此,客户端对存储在错误 storage server上的数据进行读取操作,将返回一个“data unavailable”错误。Pocket目前期望应用程序框架重新启动serverless任务来重新生成丢失的临时数据。一种常见的方法是应用程序框架跟踪 数据志,数据志就是产生每个对象的任务序列[78,39]。
对于元数据容错,Pocket支持记录共享存储上的所有元数据RPC操作。当metadataserver失败时,它的状态可以通过重放共享日志来恢复。
Controller 容错可以通过主从复制实现,尽管我们在研究中没有对此进行评估。
Pocket的 control plane 弹性地自动调整集群资源的大小。当一个作业注册时,Pocket的 controller利用通过API传递的可选hint来保守估计作业的延迟、吞吐量和容量需求,并找到一个经济有效的资源分配方式,如4.1节所述。除了预先调整作业的资源分配,pocket 持续监控集群的总体利用率,并根据负载决定何时以及如何扩展存储和元数据节点。§4.2描述了Pocket的资源升级机制及其平衡负载的数据转向策略。
当一个job注册时,控制器首先通过三个维度来决定他的资源分配:吞吐量、容量和存储介质的选择。然后,控制器使用一个onlinebin-packing 算法将资源分配转换为节点上的资源分配。
确认I/O需求:Pocket使用启发式来适应通过 register_job API传递的可选hint。表3列出了Pocket支持的hint,以及它们对吞吐量、容量和分配给作业的存储介质的选择的影响,并给出了我们在AWS上部署的示例(括号中)。

没有hint时,
资源分配:Pocket为作业生成weight map ,将作业的资源分配转换为特定storage servers上的资源分配。weight map 是一个关联数组,将每个storage server (由其IP地址和端口标识)映射为从0到1的权值,该权值表示要放在该storage server 上的作业数据集的比例。如果storage server 分配了1的权重,它将存储job的所有数据。controller将weight map发送到metadata server,metadata server使用基于weight map中的权值的加权,将客户端请求随机路由到storage server上 ,执行数据放置策略。
weight map取决于作业的资源需求和可用的集群资源。Pocket使用online bin-packing算法。该算法首先尝试在活跃的存储服务器上匹配作业的吞吐量、容量和存储介质分配,只有当作业的需求不能通过与其他作业共享资源来满足时才启动新服务器[67]。如果某个作业需要的资源比当前可用的资源更多,则controller 启动必要的存储节点,同时应用程序等待其作业注册命令返回。节点启动需要几秒钟或几分钟,这取决于是否需要一个新的VM(§6.2)。
4.2 Rightsizing the Storage Cluster
除了调整每个作业的存储分配,Pocket还动态调整集群资源,以适应随时间变化的多个作业的弹性应用程序负载。在其核心部分,Pocket集群由用于运行controller的几个长时间运行的节点、最少数量的metadata server 和(我们只有1个)最少数量的 storage servers(我们只有2个)。特别是,使用§3.2中描述的PERSIST ?ag写入的数据,其生存期更长,总是存储在集群中的长时间运行的PERSIST ?ag上。除了这些持久资源之外,Pocket还根据需求根据负载调整资源。Pocket还根据需求根据负载调整资源。我们首先描述水平和垂直扩展的机制,然后讨论通过谨慎地跨服务器操纵请求来平衡集群负载的策略。
机制: controller通过处理来自metadata server,metadata server心跳(包含cpu、网络和存储媒体容量的使用情况)来监控集群资源的利用情况。Node每秒向controller 发送统计信息。间隔是可配置的。
启动新的storage server时,controller提供所有Metadata servers 的IP地址,因为storage server 必须与Metadata servers 建立连接以 来 加入集群。新的storage server 向每个metadata server 注册其容量的一部分。Metadata servers 独立地管理它们所分配的容量,而不相互通信。storage server 定期向Metadata servers 发送心跳。
删除storage server,controller在传入作业的weight map中为storage server分配一个零权重,将storage server列入黑名单。这确保Metadata server不会将数据从新作业转移到此节点。controller随机挑选一个Metadata server,在被列入黑名单的存储服务器的心跳响应中设置一个“kill”标志。黑名单中的storage server将等待,直到其容量完全释放,因为作业终止,临时数据被垃圾收集。然后,storage server终止并释放其资源。
当控制器启动新的Metadata server时,Metadata server将等待启动新的存储服务器并注册它们的容量。
删除元数据服务器,控制器向节点发送一个“kill”RPC。元数据服务器等待它所管理的所有容量被释放,然后通知所有连接的存储服务器关闭它们的连接。当所有连接关闭时,元数据服务器终止。存储服务器然后在新的元数据服务器上注册由旧元数据服务器管理的容量。
除了水平扩展之外,控制器还管理垂直扩展。
当控制器发现某个节点上的CPU利用率很高并且有额外的内核可用时,控制器通过心跳响应指示该节点使用额外的CPU内核。
集群规模策略:Pocket使用旨在在目标范围内保持 每种资源类型(CPU、网络带宽和每个存储层的容量)的总体利用率的策略 弹性地扩展集群。可以为每种资源类型分别配置目标利用率范围,并为元数据服务器、长时间运行的存储服务器(存储使用PERSIST标志设置写入的数据)和常规存储服务器分别管理目标利用率范围。对于我们的部署,我们对所有资源维(元数据和存储节点)使用60%的低利用率阈值和80%的高利用率阈值。范围根据经验调整,并取决于添加/删除节点所需的时间。如果总体CPU、网络带宽和容量利用率低于目标范围的下限,Pocket的控制器通过删除存储服务器来缩小集群。在这种情况下,Pocket删除了属于最低容量利用率层的存储服务器。如果总体CPU、网络带宽和容量利用率超过目标范围的上限,Pocket会增加一个存储服务器。为了响应CPU负载高峰或暂停,Pocket首先尝试垂直伸缩元数据和存储服务器上的CPU资源,然后再水平伸缩节点数量。
使用数据转向平衡负载(分发数据给存储服务器):为了在动态调整集群大小的同时平衡负载,Pocket利用了临时数据和无服务器作业的短暂性。由于临时数据对象的生存时间只有几十到数百秒(参见图3),因此在添加或删除节点时迁移该数据以重新分发负载会带来很高的开销。相反,Pocket专注于在加入集群的活动和新存储服务器之间为传入的作业控制数据。Pocket通过每个job的weight map来确定给存储服务器传递多少数据。为了平衡负载,该控制器将较高的权重分配给未充分利用的存储服务器。
控制器以较粗的粒度使用类似的方法在metadata servers之间平衡负载。如§3.2所述,控制器当前将每个作业分配给一个元数据服务器。控制器会根据任务的吞吐量和容量分配来估计任务对元数据服务器施加的负载。控制器将此估计与元数据服务器资源利用率统计信息结合起来,选择用于传入作业的元数据服务器,以便预测的元数据服务器资源利用率保持在目标范围内。
Controller: 用Python实现controller,利用Kubernetes容器编排系统来启动和关闭元数据和存储服务器,运行在独立的Docker容器[7]中。The controller使用Kubernetes操作(kops)来操控运行容器[6]的虚拟机。正如在§4.2中所解释的,Pocket会对集群资源进行适当调整,以保持一个目标利用率范围。我们在Python中实现了一个资源监控守护进程,它运行在每个节点上,每秒向控制器发送CPU和网络利用率统计信息。元数据服务器还会发送存储层容量利用统计数据。我有经验的根据节点启动时间调优目标利用率范围。例如,当控制器需要启动新vm时,与运行vm而控制器仅启动容器时相比,我们使用保守的目标利用率范围。
元数据管理:我们在Apache Crail分布式数据存储之上实现Pocket的元数据和存储服务器架构[2,71]。Crail专为低延迟、高吞吐量、低持久性存储任意大小的数据要求而设计。Crail提供了跨集群中分布的一组异构存储资源的统一名称空间。它的模块化架构分离了数据和元数据平面,并支持可插拔存储层和RPC库实现。虽然Crail最初是为RDMA网络设计的,但我们为Pocket实现了一个基于tcp的RPC库,因为RDMA在公共云中并不容易获得。和Crail一样,Pocket的元数据服务器也是java实现的。每个元数据服务器将元数据操作记录到共享NFS挂载点上的一个文件中,这样,在元数据服务器出现故障时,新的元数据服务器可以访问和重播日志。
存储层:我们为Pocket实现了三种不同的存储层。
第一个是用Java实现的DRAM层,使用NIO api有效地为来自TCP连接的客户机的请求提供服务。
第二层使用NVMe闪存存储。我们在ReFlex的上层实现了Pocket的NVMe存储服务器,ReFlex是一种允许客户端(即lambdas)通过使用高性能[47]的普通以太网访问Flash的系统。ReFlex是用C语言实现的,它利用Intel的DPDK[43]和SPDK[44]库直接从用户空间,访问网络和NVMe设备队列。ReFlex使用基于轮询的执行模型来高效地处理TCP上的网络存储请求。该系统还使用一个感知服务质量(QoS)的调度器来管理Flash上的读/写干扰,并为客户端提供可预测的性能。
第三层是一个通用的块存储层,它允许Pocket通过一个标准的内核设备驱动程序使用任何块存储设备(例如HDDorSATA/SASSSD)。与ReFlex类似,该层是用C实现的,并使用DPDK实现高效的用户空间网络。但是,这个层不是使用SPDK从用户空间访问NVMe闪存设备,而是使用Linux libaio库向内核块设备驱动程序提交异步块存储请求。利用Pocket NVMe和通用块设备层的用户空间api,可以提高性能和资源效率。例如,每核ReFlex比传统的Linux网络存储栈[47】可处理11倍多的请求。
客户端库 Client library:由于我们使用的serverless 应用程序是用Python编写的,所以我们将Pocket的应用程序接口(表2)实现为Python客户端库。库的核心是用c++实现的,以优化性能。我们使用Boost将代码包装到Python库中。该库在内部管理,与元数据和存储服务器的TCP连接。
API的选择:Pocket简单的get/put接口为我们研究的应用程序提供了足够的功能。这些作业中的Lambda使用它们读取的整个数据对象,它们不需要更新或附加文件。但是,附加或访问对象的部分的posix类I/O语义可能有利于其他应用程序。Pocket的get/put API是在Apache Crail的仅追加流抽象之上实现的,该抽象允许客户端读取文件偏移量并以[3]的单写入语义追加到文件。因此,可以很容易地修改Pocket的API以公开Crail的I/O语义。过滤器或multiget等其他操作符也可以帮助优化所传输的rpc和字节的数量。如何正确选择用于临时存储的API仍然是一个悬而未决的问题。
安全性:Pocket使用访问控制来保护多租户环境中的应用程序。为了防止恶意用户访问其他租户的数据,元数据服务器向客户机发出一次性证书,这些证书在存储服务器上进行验证。没有伴随有效证书的I/O请求被拒绝。客户端通过SSL与元数据服务器通信,以防止man in the middle攻击。用户设置云网络安全规则,以防止TCP流量窥探lambdas和存储服务器之间的连接。或者,用户可以加密他们的数据。Pocket目前不会阻止作业发出比作业注册提示中指定的更高的负载。可以在元数据服务器上实现请求节流,以减少作业试图超过其分配时的干扰。
学习job特征:Pocket目前依赖于用户或应用程序框架提示的hint评估工作资源分配的有效大小。目前,Pocket还不能自主学习应用程序属性。由于用户可能会在不同的数据集上重复运行作业,因为许多数据分析和现代机器学习作业都是循环的[55],Pocket的控制器可以维护以前对作业的调用的统计信息,并将这些信息与机器学习技术结合起来,为将来的运行调整资源分配的大小[48,10]。我们计划在今后的工作中对此进行探讨。
对其他云平台的适用性:尽管我们只在AWS云平台上评估Pocket,该系统解决了一个真正适用于所有云提供商的问题。因为没有可用的平台为serverless任务交换临时数据提供优化的方式。Pocket的性能将随不同基础设施的网络和存储能力而变化。例如,如果有一个低延迟网络可用,DRAM存储层提供的延迟要比NVMe层低得多。这样的变化就需要制定计划来实现资源分配和数据放置的自动化。
对其他云工作负载的适用性:虽然我们在无服务器分析中介绍了Pocket的临时数据共享,但是Pocket也可以用于其他需要分布式、可伸缩临时存储的应用程序。例如,谷歌的Cloud Dataflow是一个完全管理的数据处理服务,用于流和批处理数据分析管道,它实现了shuffle操作器(用于GroupByKey等转换)作为后端[35]的一部分。在这种服务中,Pocket可以快速、弹性的存储由shuffle操作生成的中间数据。
通过获取资源来降低成本:云作业通常在CPU、DRAM、网络和存储资源方面供应过剩,这是由于难以对一般作业进行精确估量,并且需要适应每日的负载模式和意外的负载峰值。其结果是集群水平上容量的利用率显著不足[21,74,29]。最近的研究表明,大量已分配但暂时未使用的资源提供了一个稳定的基板,可用于运行分析作业[22,79]。我们同样可以利用已收获的资源,有效地降低运行的总成本。Pocket的存储服务器特别适合在临时空闲资源上运行,因为临时数据的生命周期短,耐久性要求低。
severless结构上的通用分析(General-analytics)在性能、弹性、资源效率上提出了独特机遇和挑战。我们分析了与数据共享有关的挑战,并且提出了Pocket,一种为serverless analytics的短期数据存储。与serverless computing的思想类似,Poket致力于为analytics workloads提供一种高弹性、划算的、精细付费的存储解决方案。Pocket通过严格分离 控制、元数据和数据管理 的职责来实现这些目标。据我们所知,Pocket是第一个专为 无服务器分析工作负载中 的 临时数据共享 而设计的系统。我们在AWS的评估表明,Pocket为任意大小的数据集提供了高性能数据访问,并结合了automatic ?ne-grain scaling、自管理和跨多个存储层的经济有效的数据放置data placement。Pocket的客户端库在为当前块写入数据时内部重叠下一个块的metadata RPCs,以避免停滞。类似地,lambdas通过以类似的方式首先链接metadata server读取数据。客户端缓存元数据,以防它们需要多次读取一个对象。
Poket: Elastic Ephemeral Storage for Serverless Analytics
标签:int scom 不能 针对 strong doc 映射 nio 应用程序
原文地址:https://www.cnblogs.com/luo-he/p/13811868.html